1.导入odin包

老是出现这个问题,是要搞死我吗?
首先尝试一下将老的卸载,然后重新安装。
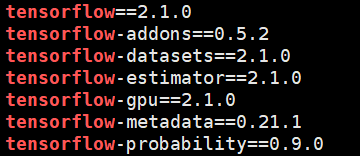
https://odin0.readthedocs.io/en/latest/setup.html 按照这个再重新安装一下pip就ok了,但是又遇到了TensorFlow版本的问题,真烦。
![]()
要安装2.1.1版本的tf。我明白了,因为我安装的是GPU版本的,所以需要这样去更新:pip install --upgrade tensorflow-gpu。ok了。
2020-4-1周三更新————————
我将tfp包将为了https://github.com/tensorflow/probability/releases 0.8,它能够适应2.0版本的tf。
2.OS.ENVIRON()详解
https://blog.csdn.net/junweifan/article/details/7615591
这个讲的还蛮好的,就是可以根据名称获得系统的路径,windows和linux是不同的。
3.PBMC的数据组成
我不明白的是pbmc它不是一共12039个cell吗?没错的,然后分为full和ly和my,但是这两者的和并不是12039啊。。。就很尴尬。
行吧纠结了一阵,还是用它直接可以下载的数据吧,因为如果用它的实验数据,我也不知道怎么预处理,会很复杂会很占用时间。
4.导入tf工具时遇到了这个问题

原来这些都是warning,我吐了!!!!!!!!记住这个错误啊,https://blog.csdn.net/toopoo/article/details/104506143。
又是关于这个libnvinfer.so.6的问题。
操,原来是tf不能导入了,我哭了。
https://github.com/tensorflow/tensorflow/issues/36201 这里是问这个问题的,感觉还是没有解决,有点绝望,我目前是有点怀疑tf2.1.0它的版本对应到哪个cuda版本的问题。
我现在使用的cuda版本是10.0:

https://www.tensorflow.org/install/gpu 看这个是说需要升级到10.1版本?
又遇到了问题: Install of driver component failed.原来是因为我的GPU在被占用!
https://forums.developer.nvidia.com/t/info-finished-with-code-256-error-install-of-driver-component-failed/107661 这个讲的非常好,在安装cuda的时候它有两个日志文件,是不同的!
还是有问题,难道我后台运行的jupyter也要关掉吗?
https://codeyarns.com/2017/09/04/nvidia-module-already-loaded-in-kernel/
这里面要重启机器,真的这么恶心吗?我记得以前安装不需要这么麻烦的啊,真的好烦!
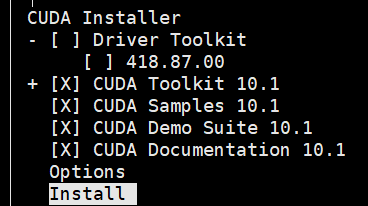
操tmd,不会是这个弱智问题吧?原来它默认是选着这个driver的???操。https://blog.csdn.net/iefyy/article/details/102740388 直到这个说我才反应过来,其他配图的我都没注意,我真是瞎啊。
取消了之后就可以安装成功了。
5.对pickle文件读取
https://blog.csdn.net/lishangyin88/article/details/79614174 太难记住了。
利用pickle 存储和读取文件 1.存储文件: #引入所需包,将列表元素存入data2的文件里面 import pickle mylist2=['a','b',['你好','证明'],1,3,5,7] df2=open('E:\data2.txt','wb')# 注意一定要写明是wb 而不是w. #最关键的是这步,将内容装入打开的文件之中(内容,目标文件) pickle.dump(mylist2,df2) df2.close() 2.读取文件: #读取文件中的内容。注意和通常读取数据的区别之处 df=open('E:\data2.txt','rb')#注意此处是rb #此处使用的是load(目标文件) data3=pickle.load(df) df.close()
6.odin包画图的导不进来

真是恶心jb死我了。去了对应的
lib/python3.7/site-packages/odin/visual/__init__.py)
路径下面,整个visual都没有看到from这句话啊。
我知道了,不应该取找odin,应该找sisua啊。。。
是因为它用的这个odin包里的函数已经被修改了,而且参数也不一样,
2020-4-1周三更新————————
尝试将所有使用plot_scatter_heatmap的地方注释掉,
![]()
#上面问题的解决办法是,我进入了安装包的路径,然后看了一下它的导入方式应该都加上一个_下划线,就ok了,就能找到包的所在。
说这不是一个包,emm那就再安装吧?然后pip install anndata。。
找遍了odin的visual模块,真的没有plot_scatter_heatmap这个函数!
我就尝试着运行,然后把所有关于上面这个函数的部分注释掉,然后又出现了以下问题:
![]()
然后我就把那句错的注释掉了。
![]()
不能从tfp中导入这个,我猜是版本的问题,难道我真的要升级tfp版本,然后升级cuda吗,我哭。

看来是不行了,要升级版本了。
https://bluesmilery.github.io/blogs/a687003b/ 根据这个设置了一下cuda的变量,写了一个sh文件,但是我觉得好像不怎么管用啊,我挺怕的。
现在将tf-gpu升级至2.1版本,又将tfp升级到了0.9版本。升级之后果然又出现了这些warning,不过我不在意了。

不行啊,我升级所有的版本之后就还是报同样的错误,我不懂了。
https://github.com/tensorflow/tensorflow/issues/27547 ,看这个上面说要安装,tfp-nightly,好吧安。而且这里面说tfp是完全基于tf的,和tf-fpu没有关系。
![]()
我要吐了,安装了之后,出现了上面更多的问题,在运行import tensorflow_probability as tfp时,吐了不整了,我们无缘。吐了!不整了!
2020-4-2周四——————
我又锲而不舍地回来了。
https://www.tensorflow.org/api_docs/python/tf/math/xlog1py 根据这个我尝试安装了pip install tf-nightly-gpu,因为里面说这个core好像只有在nightly版本中有。
上面的问题解决了,但是又出现了下面的问题啊。

搜索之后发现是https://github.com/tensorflow/addons/issues/753,在import tensorflow_addons as tfa时出现的bug,
我尝试升级一下它pip install --upgrade tensorflow-addons,但是立马给出了bug。。。
![]()
不管了,先试试吧。现在导入tfs就不会报上面的错误了,应该是在新版里就修复了。因为https://github.com/tensorflow/addons/issues/574 提到说是什么tf和tfa版本mismatch的问题,所以就尝试了一下。嗯,然后又遇到了这个问题:
![]()
我去对应路径下看了文件,发现根本没有self_vae.py这样的文件,当然本地路径也没有,所以我就将这一句注释掉了。
![]()
又出现了问题,在意料之中。我查看了odin的layer路径将import语句路径改了一下,odin.bay.layers,就找到了,解决bug。
![]()
发现也是路径的问题,就将它改了一下,改成和上面一样的路径就ok了。又出现了问题:
![]()
同理,我将这个注释掉,并且注释掉了那个Statistic.DIST参数,,不会有啥问题吧。
![]()
又遇到了很多相似的问题,都用相同的思路来解决。
![]()
这个什么高级模型,在odin里是真的没有找到啊。这可咋整?我换了之后它又出现问题了,下面:

原来还不赖我改的,是下面有导入,这又是啥包啊????天哪。

那么使用pip install hyperopt安装,是https://pypi.org/project/hyperopt/它是一种通过贝叶斯优化来调整参数的工具,该方法较快的速度,并有较好的效果。

安装后和本地的omic不一样,没了const文件不一样,我打算把本地的omic那个class赋值进去。
//感觉越来越恶心。去si吧。
2020-3-26————————————————————————
1.python的local()函数
https://www.cnblogs.com/blackmatrix/p/5604160.html 这个讲的这么好,居然没有人赞?
def func(): arg_a, arg_b = 'a', 'b' def func_a(): pass def func_b(): pass def print_value(): print(arg_a, arg_b) return locals() if __name__ == '__main__': args = func() print(type(args)) print(args) #输出: <class 'dict'> {'print_value': <function func.<locals>.print_value at 0x00000247B01F30D0>,
'func_b': <function func.<locals>.func_b at 0x00000247B01F3048>,
'func_a': <function func.<locals>.func_a at 0x00000247B01F0F28>, 'arg_b': 'b', 'arg_a': 'a'}
可以看到它是返回当前命名空间中的局部值,不仅包括局部变量还包括局部的函数。
果然,当用在类中的时候也会返回类的参数。
class NewProps(object): def __init__(self,units,xdist): self._age = 40 self.kw=dict(locals()) def getkw(self): return self.kw if __name__ == '__main__': x = NewProps(1.2,3.4) print(x.getkw()) #输出: {'xdist': 3.4, 'units': 1.2, 'self': <__main__.NewProps object at 0x00000205957BD080>}
2.y蛋白质数据是用bigarray存储的
怪不得我用pickle读取就会报错,说不是pickle类型的。。。
暂时没读出来
3.二值化
https://blog.csdn.net/weixin_44953364/article/details/99541530
原来二值化就是设置一个阈值啊,让高于它的为,低于它的为0.
import numpy as np from sklearn import preprocessing data = np.array([[3, -1.5, 2, -5.4], [0, 4, -0.3, 2.1], [1, 3.3, -1.9, -4.3]]) data_binarized=preprocessing.Binarizer(threshold=1.4).transform(data)#设定阈值 print("原始: ",data) print("二值化: ",data_binarized) #输出: 原始: [[ 3. -1.5 2. -5.4] [ 0. 4. -0.3 2.1] [ 1. 3.3 -1.9 -4.3]] 二值化: [[1. 0. 1. 0.] [0. 1. 0. 1.] [0. 1. 0. 0.]]