2.关于各种方式存储稀疏矩阵python,这个讲的非常具体
https://www.cnblogs.com/hellojamest/p/11769467.html (待看)
3.果然我就猜测是否会GPU内存溢出。。
RuntimeError: CUDA out of memory. Tried to allocate 1.28 GiB (GPU 0; 10.76 GiB total capacity;
8.17 GiB already allocated; 825.56 MiB free; 1.02 GiB cached)
https://github.com/pytorch/pytorch/issues/958,从这个解答中可以看出,有一个例子是给了好多全连接层,然后溢出了。这个链接的讲解是great的!!!
那我有个疑问,如果GPU溢出的话, 能不能放到cpu上来训练,但是这样的话,模型还有什么意义。。。
https://zhuanlan.zhihu.com/p/61892329 这个里面的让我很震惊啊,真的是这个意思啊,原来溢出是和数据集大小和模型大小是没关系的吗,握哭了,原来是这样。

以后遇到溢出的话,就直接只考虑把batch_size足够减小就好了。。。
3-12————————————————
4.如果模型不收敛
https://zhuanlan.zhihu.com/p/36369878
http://theorangeduck.com/page/neural-network-not-working#batchsize
5.sklearn中的另一个标准化方法StandardScaler
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html

均值和标准差:
>>> scaler.mean_ array([0.5, 0.5]) >>> scaler.var_ array([0.25, 0.25])
总的过程就是x-miu/std,是标准差,不是方差哦。
3-13————————————————————
1.TF-IDF逆文档频率
https://zhuanlan.zhihu.com/p/31197209
需要理解的三个点:词频和逆文档频率的计算方法、and优缺点。
TF-IDF为两者相乘,与词频成正比,与逆文档频率成反比,这样的话就能够选出来那些在文档中出现次数多,但在其他文档中出现次数少的词,以此来作为一个文档的标志。
优缺点:有时候关键的词可能出现次数并不多,而且不能反应上下文关系,只是从一个频率上去反映。
这个博客讲的就蛮清楚的了。
sklearn中计算
from sklearn.feature_extraction.text import TfidfVectorizer corpus = [ 'This is the first document.', 'This document is the second document.', 'And this is the third one.', 'Is this the first document?', ] vectorizer = TfidfVectorizer() X = vectorizer.fit_transform(corpus) print(vectorizer.get_feature_names()) print(X.shape) #输出: ['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this'] (4, 9) >>> X <4x9 sparse matrix of type '<class 'numpy.float64'>' with 21 stored elements in Compressed Sparse Row format> >>> vectorizer.vocabulary >>> vectorizer.vocabulary_ {'this': 8, 'is': 3, 'the': 6, 'first': 2, 'document': 1, 'second': 5, 'and': 0, 'third': 7, 'one': 4} >>> len(vectorizer.vocabulary_) 9 >>> X[0] <1x9 sparse matrix of type '<class 'numpy.float64'>' with 5 stored elements in Compressed Sparse Row format> >>> X[0].toarray()#可以看到它是按照字典中的从小到达的顺序来作为句子的特征的 array([[0. , 0.46979139, 0.58028582, 0.38408524, 0. , 0. , 0.38408524, 0. , 0.38408524]])
>>> X[1].toarray()
array([[0. , 0.6876236 , 0. , 0.28108867, 0. ,
0.53864762, 0.28108867, 0. , 0.28108867]])
也就失去了原来句子的顺序吗?
这样每一个句子就可以用一个向量来表示了。
2.亚线性
头一次知道了什么是亚线性,原来和方有关系
线性相当于1次方,亚线性就是0-1次,超线性就是1次方以上
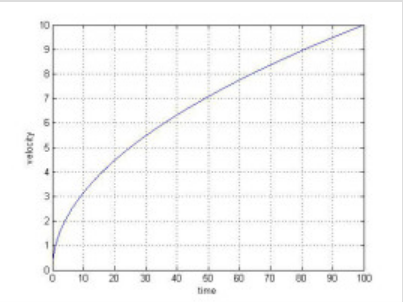
也就是上图的变化关系,这样的话就可以理解为,log那种在y=x曲线下的,就是亚线性,那种指数词的曲线在y=x上的,就是超线性。
3.14————————————————————————
1.发生了一件十分震惊我的事,一个简单的逻辑回归效果都这么好??

那我得好好研究研究了。
2.sklearn中的LogisticRegression是如何实现的及具体用法
其实我有一点好奇的是,LogisticRegression在fit的时候有没有batch_size呢?毕竟我的IMDB这个数据集,它可是有25000条数据的,如果全都作为一个矩阵输入的话可能是不太好吧?计算速度会很慢吧。
看了一下源码,也看不出来是怎么计算的,反正肯定是有优化的吧,会训练出参数w,就这样。

震惊我全家,TF-IDF+逻辑回归真的高,为啥比用双向LSTM+词向量还高?真jb恐怖!!!又简单又有效!
还有一个可能的原因是后者我没用特别详细的预处理,所以导致效果没那么好。
3.sklearn中accuracy_score,recall_score,precision_score计算方法
只要根据真实的标签和预测的标签,构建出一个混淆矩阵,就很好算出来啦,这个地方不是问题。
4.预处理方法运用到IMDB+词向量+LSTM模型中
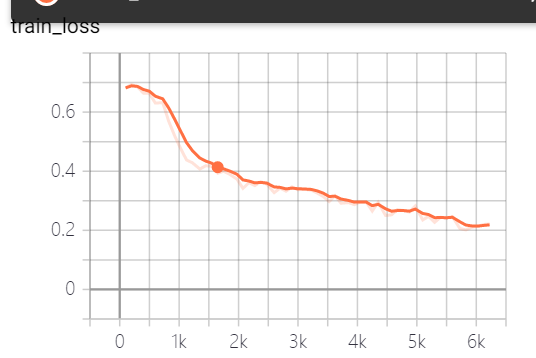
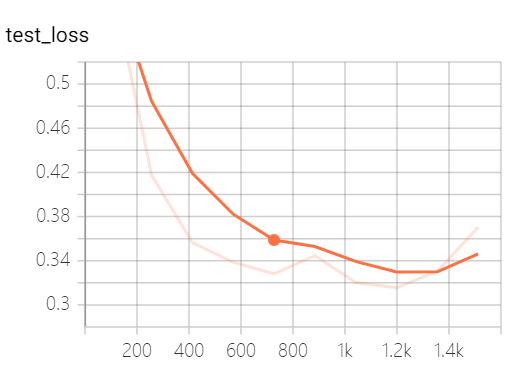
看起来损失函数还行啊,为啥??这个精确度让我怀疑人生????

是我写错了,已改。
不行,提交之后效果非常差,只有0.80.。。为啥深度学习的方法不行了???崩塌。
能有的接下来的方法就是去看一下别人的有效的模型。吸取经验。
5.从这个文章中学到了不少文本分类知识
https://zhuanlan.zhihu.com/p/25928551
fastText将句子中的词向量取均值,然后softmax得到句子的label进行文本分类,这样虽然没有考虑词序,说明句子和句意之间也许没有那么复杂的非线性关系。
text CNN因为CNN最大的特点就是捕获临近相关性,局部相关性,也就是相当于捕获n-gram信息,所以它也不能用在长句中,不能捕获上下文信息,通常用RNN来捕获。
还有加上attention之后的,能够加深理解句子分类与对应单词的影响关系。
还有很重要的trick:
词向量一定要fine-tune微调
一定要dropout,默认为0.5(那如果不是在文本分类任务中,是不是这个就不通用了?)
理解数据的badcase,下面学习什么是badcase。
对于类目不均衡的问题,可以调整样本权重。(这个我还没有实验过,目前是只知道理论。。)
6.badcase
https://blog.csdn.net/qianyongismydream/article/details/90513004,虽然这个链接里,它的统计有很多我没看懂,比如说用DBSCAN的那个,但是还是有启发的。
在处理数据时,可能会存在重复的,这个我从来没考虑过,所以以后需要考虑一下。去重。
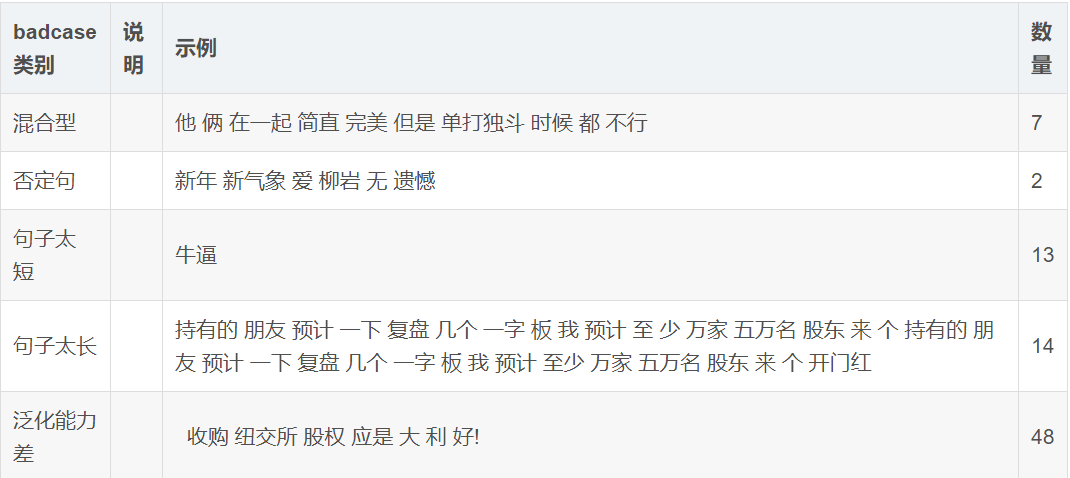
对于情感分类来说,比如上面的,否定型,句子太短他、太长等,都会导致这个case样例效果不行、
简单理解,就是那些对模型训练没有帮助,反而会混淆的样例吧。
8.欠采样和过采样
https://www.zhihu.com/question/269698662
2020-4-5周日更新————————
我就说我赞同了微调的这个回答,但是又看为啥就没印象呢?原来还是待看啊,吓我一跳。
首先内容讲到了欠采样和过采样,假设不平衡数据集中正例少,负例多,那么欠采样就是从负例中抽取部分的样本,这样就会产生数据丢弃了,但是数据是很珍贵的,如果是每次采样负例然后和正例组成一个训练集,这样产生多个训练集,就可能会存在正例过拟合,及训练成本增加的现象。
过采样就是从正例中重复采样直到1:1,那当然正例就会存在重复,所以就也可能会过拟合,而且正例中的噪声多次使用就会被放大,可能会对模型产生不好的影响。
还介绍了一种方法SMOTE,它可以从正例中的k临近中创造新的正样本,好像效果不错,但是评论区中有人说:
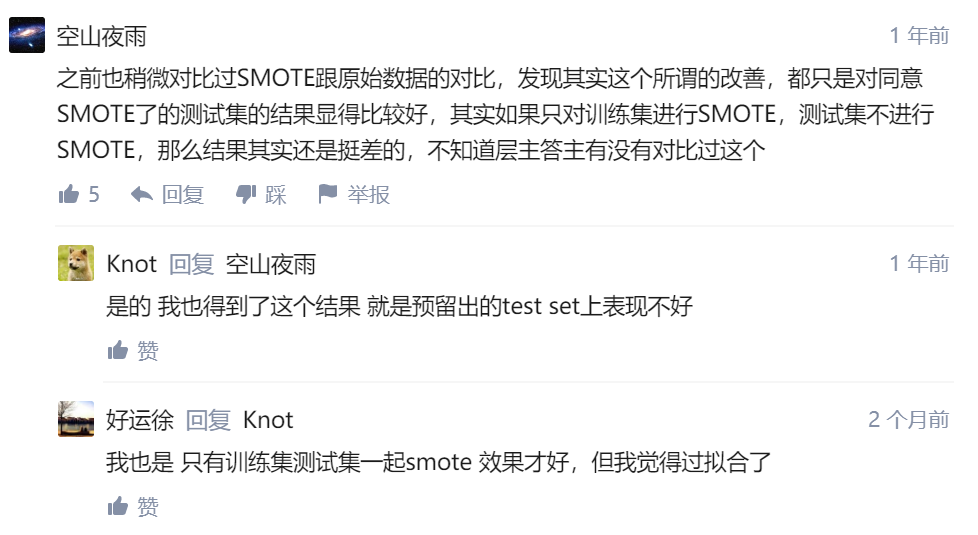
这里面说还要对测试集进行smote,这我就不知道了,反正它打消了我目前想要用它的想法。
评论里面还有一个特别有价值的:
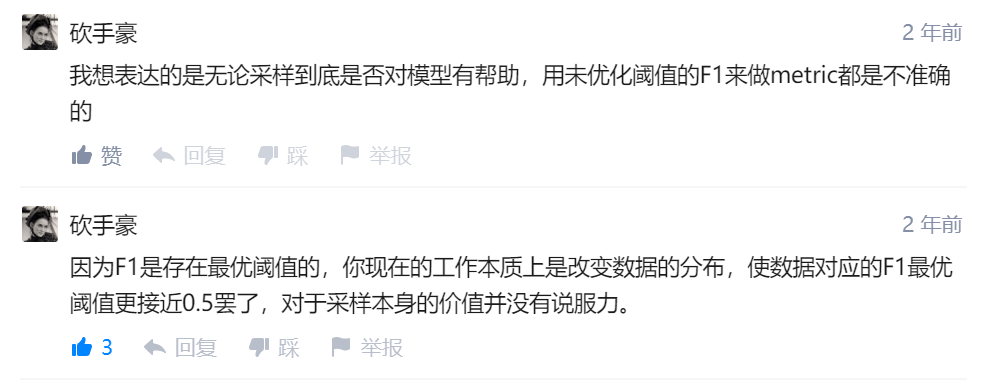
这里的意思是,因为数据不平衡可以通过调整阈值来改变分类结果,所以就首先应该找到最优的阈值,然后确定对应的F1值,之后改变数据分布的效果,就应该用这个最优阈值去判断,然后得出对应的F1值,再和之前的F1值做对比,这样一来才能说采样这些方法是有效的,我认为他说的非常有道理!还有一个评论,很有启发:

就是到底什么比例的数据才会被认为是不平衡的呢?这个我还真的没想过。。。这个我就要学习一下了。。。写到4-5号的笔记里去吧。
还有一个有价值的问题,

https://www.zhihu.com/question/269698662/answer/350806067 这个给了解释,重新调整metric的意思?我还不太理解,以后再来看。
太6了,能发现这么多有价值的问题,我爱知乎!
要学的太多了啊!
最终微调给出的经验是:
