2.fastText适用方法及原理理解
https://blog.csdn.net/feilong_csdn/article/details/88655927 (待看)
3-2————————
1.IMDB项目读入
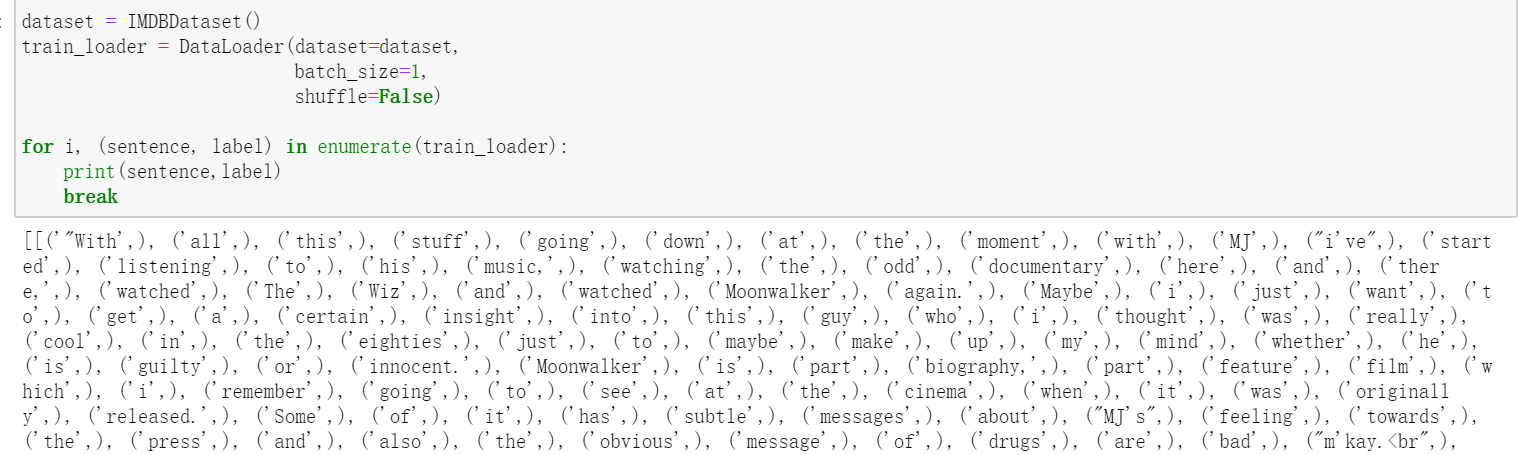
class IMDBDataset(Dataset): # Initialize your data, download, etc. def __init__(self, filename="./data/trainData.tsv"): self.len = 0 with open(filename, 'rt') as f: reader=f.readlines() reader=reader[1:] self.sentences=[] self.labels=[] for r in reader: line=r.strip().split(' ') self.sentences.append([line[2].split()]) self.labels.append(int(line[1])) self.len=len(self.labels) def __getitem__(self, index): return self.sentences[index], self.labels[index] def __len__(self): return self.len
3-3_________
1.原来torch.tensor是不能处理str的,只能对整形的进行处理,否则:
torch.tensor(['1']) File "<ipython-input-14-602ae6edb6c1>", line 1, in <module> torch.tensor(['1']) ValueError: too many dimensions 'str'
2.如果针对最后的hidden输出,size为(numlayes*directions, batch_size, hidden_size)
a=np.random.randn(2,3,4) a Out[18]: array([[[-0.66829249, -0.76499464, -0.74026101, -0.48124549], [-2.178205 , 1.60187794, -0.30890059, 0.33686713], [ 2.05912833, 0.37473968, -0.56136807, -0.72185835]], [[-0.91576137, -0.86514116, 0.03120998, 0.23659517], [-2.83921972, 2.10052047, -0.61340947, 1.20655193], [ 0.60929364, 1.22116812, 0.39065162, -0.53161084]]]) a[-1] Out[19]: array([[-0.91576137, -0.86514116, 0.03120998, 0.23659517], [-2.83921972, 2.10052047, -0.61340947, 1.20655193], [ 0.60929364, 1.22116812, 0.39065162, -0.53161084]])
只选择最后的话,就相当于是最后一个batch的最后一个word的隐层输出。