1.git更新本地项目到远程仓储。
https://blog.csdn.net/u014135752/article/details/79951802
我是fork了别人的项目,然后下到了本地,阅读后加上了注释,想要更新到我的github上,但是又怕更新到人家的那个上面,把人家出事的给覆盖了。
https://stackoverflow.com/questions/20939648/issue-pushing-new-code-in-github/28009046
出现了 git pull的问题。
git的分支到底是什么意思?
https://backlog.com/git-tutorial/cn/stepup/stepup1_1.html
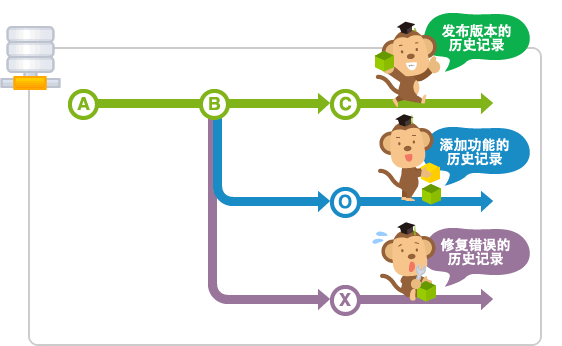
也就相当于不同的文件夹,文件夹之间可以合并,这是我的理解。
https://www.jianshu.com/p/8265d29a0ba5
使用git branch可以查看当前分支的名字,git branch -r查看远程分支的名字。
https://blog.csdn.net/ming13849012515/article/details/81011632
本地仓储的branch和别的不能建立联系的话,就使用:git branch --set-upstream-to=origin/远程分支的名字 本地分支的名字 。
出现问题:
Updates were rejected because the tip of your current branch is behind its remote counterpart.

https://blog.csdn.net/zhangkui0418/article/details/82977519
但 git pull --allow-unrelated-histories 又出现了一下错误:
The following untracked working tree files would be overwritten by merge:

git add *
git stash
git pull
还是都不行啊。
还是解决不了,我决定换一种方法了。。
但是又出现了等问题,
Everything up-to-date Branch 'master' set up to track remote branch 'master' from 'origin'.
而且首先是这个"fatal: HttpRequestException encountered. "https://stackoverflow.com/questions/2936652/git-push-wont-do-anything-everything-up-to-date
大意是需要windows桌面版本才可以push
终于可以了,原来是账号登录不对了,我真的枯了。
2020-2-22————————————
2.为什么softmax要取log?
https://blog.csdn.net/LEILEI18A/article/details/101284481
https://blog.csdn.net/tongjinrui/article/details/79724074
因为我们可以看一下-log的曲线,在取softmax之后数据归到【0,1】之间,那么当取值接近于0时,当label预测趋近于错误时,损失函数相应会很大,反之靠近1,就很小。这样就可以满足损失函数的要求了。
3.返回的loss是否要求梯度了呢?

看到这个代码就突发了一个问题,那么loss的返回结果是什么呢?看了一下损失函数的返回类型是一个scalar,也就是标量,那么requires_grad值是什么呢?
进行了下面的小实验:
import torch a=torch.tensor(0.1) print(a) print(a.item()) b=torch.tensor([0.1]) print(b) print(b.item()) c=torch.tensor([0.1],requires_grad=True) print(c) print(c.item()) #结果: tensor(0.1000) 0.10000000149011612 tensor([0.1000]) 0.10000000149011612 tensor([0.1000], requires_grad=True) 0.10000000149011612 >>> a.requires_grad False >>> b.requires_grad False >>> c.requires_grad True
原来创建tensor默认requires_grad就是False,我之前一直为误以为是True。。。所以就不必像那样声明requires_grad是False。。
3.出现了这个Nosetests的问题,真是气死了。。

https://blog.csdn.net/kongsuhongbaby/article/details/96488949
这个解决办法原来是可以的!就是不能以test开头函数名或者类型!
2-23——————————————
1.momentum 动量到底在优化函数中有什么意思??
https://towardsdatascience.com/stochastic-gradient-descent-with-momentum-a84097641a5d 这个我还看不太明白。
它是一种像SGD的优化方法,不过SGD是直接通过当前的梯度来更新参数,momentum有不同的更新参数的公式。
https://www.zhihu.com/question/305638940

用来更新参数的Vt,计算是通过前一时刻的Vt-1和现阶段的梯度来计算的。
https://zhuanlan.zhihu.com/p/61955391 这个讲的蛮不错的。
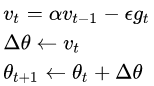

这里也涉及到了指数加权平均exponentially weighted averges。
2.divmod
把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
>>>divmod(7, 2) (3, 1) >>> divmod(8, 2) (4, 0)
3.keepdim=True
原来不是直接转换成one-hot呢。
import torch a=torch.tensor([[1,2,3],[6,5,4]]) print(a.data.max(1,keepdim=True)[1]) #结果: tensor([[2], [0]]) >>> b=torch.tensor([1,2]) >>> b.view_as(torch.tensor([[2], [0]])) tensor([[1], [2]])
返回的是保持原来y轴0轴上的维度。
4.CNN中Chanel的变换

为啥输入一个通道,就能够输出10个通道数??
明白了,那如果输出的Chanel是10将会有10个size一样的卷积核(过滤器)。
对于mnist,这种二维的,kenel_size应该是默认变为(5,5)
从这个简单的例子中就可以看出来:
import torch import torch.nn as nn m = nn.Conv2d(16, 33, 3, stride=2) input = torch.randn(20, 16, 50, 100) output = m(input) #输出: >>> output.size() torch.Size([20, 33, 24, 49])
计算公式如下:

#搞明白了,真的好开心呐~
2020-5-25更新————————
#我知道我为什么看了那么多次,还是不明白的原因了,因为我还是无法将它和nlp在具体应用时结合起来。
见《textcnn》那篇文章,有针对讲解了。
5.pytorch正常的RNN该怎么写?
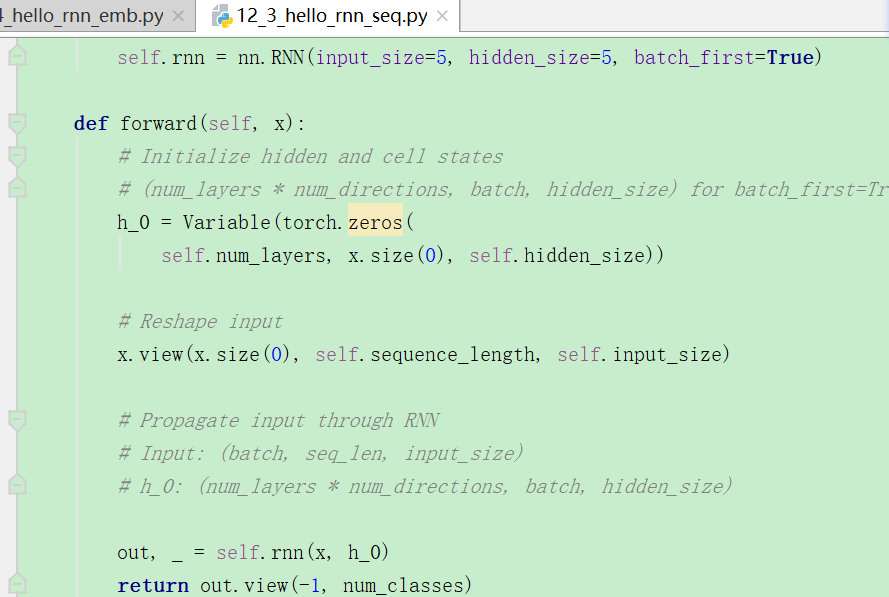
看到这个教程这么写,我觉得非常奇怪啊,这样的话那就每次只进行了一次forward,没有timestep??
并且每次都initHidden,那么如何保留上一个时间步的输出?RNN不是会记忆吗?如果重新初始化为0,那记忆又是怎么实现的呢???
https://www.pytorchtutorial.com/pytorch-sequence-model-and-lstm-networks/ 和https://pytorch.org/tutorials/beginner/nlp/sequence_models_tutorial.html
最终的最终,我还是没搞明白什么时候要初始化hidden,就算在处理同一个问题的时候,可能是时间先后的问题,两个给出了不同的,差异点就是在有没有初始化hidden上。上面的。
6.nn.Embeddings

https://pytorch.org/docs/stable/nn.html
原来第一个维度是嵌入的个数,第二个是维度,第一个理解起来就是vocab的大小是多少,一共有多少单词需要建立embedding。
import torch import torch.nn as nn embedding = nn.Embedding(10, 3) input = torch.LongTensor([[1,2,4,5],[4,3,2,9]]) print(embedding(input)) #输出: tensor([[[ 0.0836, 0.8841, 1.0482], [-0.5619, -0.1675, 0.4611], [ 0.3298, 0.2257, -0.5489], [ 1.3400, -0.2116, 0.0309]], [[ 0.3298, 0.2257, -0.5489], [ 0.1834, -1.0833, 0.4628], [-0.5619, -0.1675, 0.4611], [ 2.6498, -1.2940, 1.0904]]], grad_fn=<EmbeddingBackward>)
有一点小小的疑问,就是不是说输入10个??那么input中给了6个,所以就很emmm。那两个呢?
当我在上面的地方加上:
input2=torch.LongTensor([[11,12,14,15],[4,31,2,9]]) print(embedding(input2)) #果然报错: RuntimeError: index out of range at c:aw1swindowspytorchatensrc hgeneric/THTensorEvenMoreMath.cpp:191 #就是word太多,vocab下标越界了。
但我如果换成这个样子:
不对不对,之前我理解错了,就是index超标了,超过了10,0-9,不能出现10以上的。
input2=torch.LongTensor([[1,2,0,6],[7,8,2,9]]) print(embedding(input2))
变成上面代码的话,就非常地正常了。原来是这样啊。
2020-5-12周二更新————————
6.1这里词向量是否是可以更新的?
https://pytorch.org/docs/stable/nn.html
我跑了上面的例子代码
a=embedding.weight #输出: >>> a Parameter containing: tensor([[ 0.0288, 0.8227, -1.0783], [-1.1472, -1.0256, -0.0144], [-0.2304, 1.2761, 0.4757], [ 1.0669, -0.5264, 1.5879], [-1.5114, -0.1351, -1.5455], [-0.1970, -1.1633, 0.1477], [-1.1048, -0.0703, -0.6963], [-0.7295, -0.3831, -1.1680], [ 0.1752, -0.1280, 1.3552], [ 0.1582, 0.3204, -0.3480]], requires_grad=True)
我们可以看到,这里a是requires_grad=True,所以在训练的过程中,词向量是有个学习的过程的,也就是微调的过程吧,默认是更新的。
如果想要固定住的话,可以手动地设置:
>>> embedding.weight.requires_grad=False >>> embedding.weight.requires_grad False
之前的方法,这个Variable对象,默认求导是False的。
import torch from torch.autograd import Variable autograd_tensor = torch.randn((2, 3, 4)) #输出: >>> autograd_tensor.requires_grad False
7.torch.mm
矩阵相乘,结果非常简单,输入参数非常简单。
8.nlp教程第一篇实现:A Neural Probabilistic Language Model
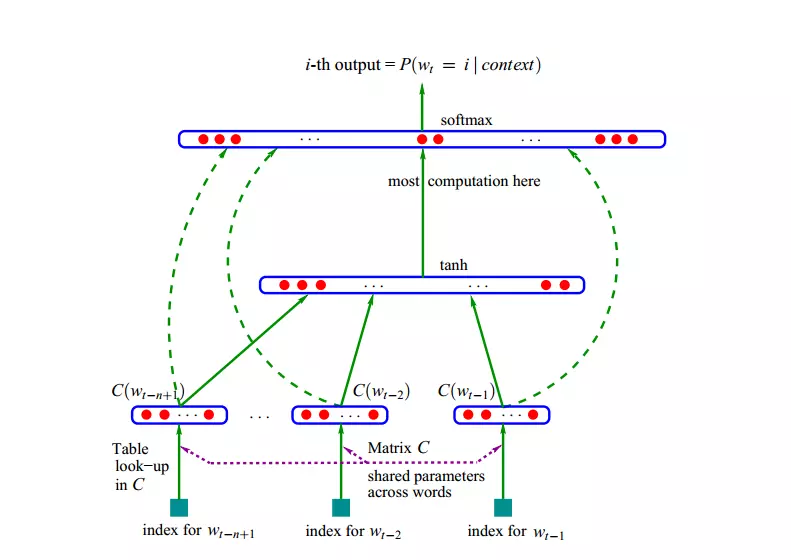
https://zhuanlan.zhihu.com/p/21101055
其他讲解的博客说,最后一层softmax的计算量非常大。那么由此就改进了层次softmax等,这个我还从来都不知道,所以需要学习一下这方面的。
想一下它的计算公式,如果词表大的话,大到几万,那么分母的计算可是非常吓人的啊。
9.softmax的改进
https://blog.csdn.net/qunnie_yi/article/details/80128024
分层softmax,分片softmax,CNN-Softmax等。

这个图非常有意思,各种softmax近似计算方法比较。原来softmax还有这么多替换的方法啊!
但是我还是有一个疑问,重采样到底是什么。。。