转自:http://sofasofa.io/forum_main_post.php?postid=1002963
1.对于supervised learning,分布是指关于特征X和结果Y的联合分布F(X,Y)或者条件F(Y|X)。
我们说训练集和测试集服从同分布的意思是训练集和测试集都是由服从同一个分布的随机样本组成的,也就是

对于unsupervised learning,分布是指特征X的分布F(X),也就是
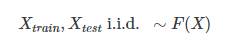
但是现实中比较难做到这点,特别是当训练集是过去的数据,测试集是当下的数据,由于时间的因素,它们很可能不是完全同分布的,这就增加了预测难度。
这也是为什么一般交叉验证的误差往往小于实际的测试误差。因为交叉验证中每折数据都是来自训练集,它们肯定是同分布的。
如果训练集和测试集的分布风马牛不相及,那么根据训练集学习得到的模型在测试集上就几乎没有什么用了。所以我们训练模型和应用模型时一个重要的前提假设就是训练集和测试集是同分布的。
另外一个方面是牵涉到过拟合问题,即使训练集和测试集是同分布的,由于数据量的问题,训练集的分布可能无法完整体现真实分布,当我们过分去学习训练集分布的时候,我们反而会远离真实分布(以及测试集的分布),造成预测不准确,这就造成过拟合。