论文题目:《Momentum Contrast for Unsupervised Visual Representation Learning》
论文作者: Kaiming He、Haoqi Fan、 Yuxin Wu、 Saining Xie、 Ross Girshick
论文来源:arXiv
论文来源:https://github.com/facebookresearch/moco
1 主要思想
文章核心思想是使用基于 Contrastive learning 的方式自监督的训练一个图片表示器(编码器),能更好的对图片进行编码然后应用到下游任务中。基于对比的自监督学习最大的问题就是负样本数量增大后会带来计算开销的增大,这里使用了基于队列的动态字典来存储样本,同时又结合了动量更新编码器的方式,解决了编码器的快速变化降低了键的表征一致性问题。MoCo在多个数据集上取得了最有效果,缩小了监督学习和无监督学习之间的差距。
2 框架
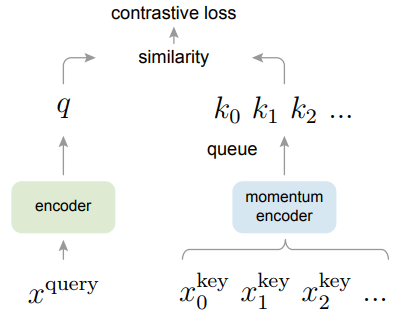
查询表示 是 $q=f_q(x^q)$,其中 $f_q$ 是编码器网络,$x_q$ 是查询样本(同样,$k=f_k(x^k)$)。
输入 $x^q$ 和 $x^k$ 可以是 images, patches 或由一些 patche 组成的 context。 网络 $f_q$ 和 $f_k$ 可以相同、部分共享或不同。编码器可以是任何卷积神经网络。
作者采用动量对比方法的两个核心:(1)将字典作为队列。将字典作为队列主要就是为了能将字典的大小和 mini-batch 分离开来。(2)动量更新。主要是为了解决字典这部分数据在反向传播的时候更新参数的问题,因为反向传播需要在队列中所有的样本中进行传播。
- 数据增强(data augmentation)手段
- 从随机调整大小的图像中获取 224×224 像素的裁剪(a 224×224-pixel crop is taken from a randomly resized image)
- 随机颜色抖动(random color jittering)
- 随机水平翻转(random horizontal flip)
- 随机灰度转换(random grayscale conversion)
- 对比损失(contrastive loss): lnfoNCE
- 字典中有一个与 q 匹配的键,表示为 $ k_{+}$。
- 通过点积(dot product)衡量相似性,这是一种对比损失函数,称为 InfoNCE。
$mathcal{L}_{q}=-log frac{exp left(q cdot k_{+} / au ight)}{sum limits _{i=0}^{K} exp left(q cdot k_{i} / au ight)}$
- 其中 $ au $ 是温度超参数( temperature hyper-parameter),$sum $ 包括 $1$ 个正样本 和 $K$ 个负样本。
- 该损失是试图将 q 分类为 $k_+$ 的(K+1)路基于 softmax 的分类器的对数损失。
- 动量对比(Momentum Contrast)
- 假设是好的特征可以通过一个包含丰富负样本集的大字典来学习。
- 字典作为队列(Dictionary as a queue)
- 将字典维护为数据样本队列, 允许重用来自前面的小批量(mini-batche)的编码键( key );
- 字典大小可以比典型的小批量大小(l mini-batch size)大得多;
- 字典中的样本被逐步替换。删除最旧的(oldest) mini-batch 是有益的,因为它的编码键( key )是过时的,因此与最新的键最不一致。
- 动量更新(Momentum update)
- 使用队列可以使字典变大,但也使得通过反向传播更新关键编码器变得困难(梯度应该传播到队列中的所有样本)。一个不成熟的解决方案是从 key encoder $f_q$ 复制梯度到 query encoder $f_k$,忽略 $f_k$ 的梯度。但是这种解决方案在实验中产生了较差的结果。我们假设这种失败是由快速变化的编码器引起的,这降低了关键表示的一致性。 我们建议 使用 动量更新 来解决这个问题。
- 将 $f_k$ 的参数表示为 $ heta _k$,将 $f_q$ 的参数表示为 $ heta _q$,我们通过以下方式更新 $ heta _k$:
- 使用队列可以使字典变大,但也使得通过反向传播更新关键编码器变得困难(梯度应该传播到队列中的所有样本)。一个不成熟的解决方案是从 key encoder $f_q$ 复制梯度到 query encoder $f_k$,忽略 $f_k$ 的梯度。但是这种解决方案在实验中产生了较差的结果。我们假设这种失败是由快速变化的编码器引起的,这降低了关键表示的一致性。 我们建议 使用 动量更新 来解决这个问题。
$ heta_{mathrm{k}} leftarrow m heta_{mathrm{k}}+(1-m) heta_{mathrm{q}}$ $m in[0,1)$
只有参数 $ heta _q$ 被反向传播更新,经发现 $m = 0.999$ 效果比较好。
3 相关研究
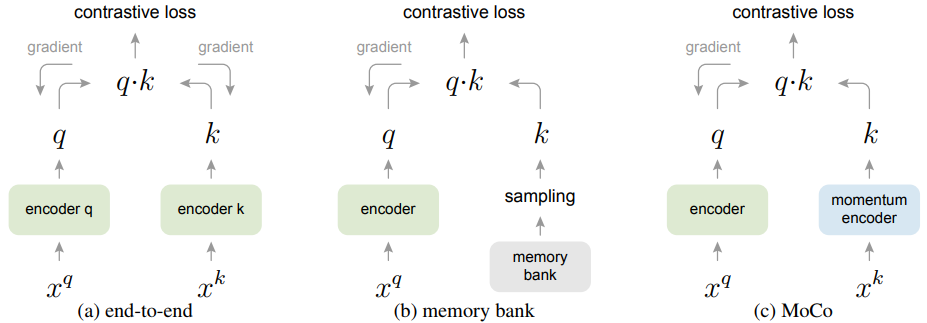
作者还对传统的更新方式和MoCo的更新方式进行了对比 分别是 end-to-end 和 memory bank 。
3.1 Method: end-to-end
(a) 查询(query) 和 键( key ) 表示的编码器(encoder)通过反向传播(back-propagation)进行端到端更新(两个编码器可以不同)。
这种方式query和key用两个encoder,然后两个参数是都进行更新的,字典大小就是 mini-batch 的大小。
- 使用当前小批量中的样本作为字典,因此键是一致编码的(相同的编码器参数集);
- 但是字典大小加上 mini-batch 大小,受GPU显存大小限制;
3.2 Method: memory bank
(b) 键( key )表示是从存储库(memory bank)中采样的。
由于memory bank里面存着所有的样本,每次实验只取部分样本,所以无法对其进行计算,这里就只更新 encoder q 的参数。
- 存储库(memory bank)由数据集中所有样本的表示组成;
- 每个 mini-batch 的字典是从存储库(memory bank)中随机采样的,没有反向传播,因此它可以支持大字典大小;
- 存储库中样本的表示在最后一次看到时更新,因此采样的密钥本质上是关于过去 epoch 中多个不同步骤的编码器,因此不太一致;
- 它的动量更新基于相同样本的表示,而不是编码器。
3.3 Method: MoCo
(c) MoCo 通过动量更新的编码器(momentum-updated encoder,)即时对新键( key )进行编码,并维护一个键队列(图中未显示)。

对于每个batch x:
- 随机增强出 $x^{q} 、 x^{k} $ 两种 view ;
- 分别用 $f_{q} $ , $ f_{k} $ 对输入进行编码得到归一化的 $q $ 和 $ mathrm{k} $ , 并去掉 $mathrm{k} $ 的梯度更新 ;
- 将 $mathrm{q} $ 和 $mathrm{k} $ 中的唯一一个正例做点积得 cosine相似度 ($mathrm{Nx} 1$) , 再将 $mathrm{q}$ 和队列中存储的K个负样本做点积得 cosine相似度 ($mathrm{NxK}$) , 拼接起来的到 $mathrm{Nx}(1+mathrm{K}) $ 大小 的矩阵, 这时第一个元素就是正例,直接计算交叉摘损失, 更新 $f_{q}$ 的参数;
- 动量更新 $f_{k} $ 的参数: $ f_{k}=m * f_{k}+(1-m) * f_{q} $;
- 将 $ mathrm{k}$ 加入队列,把队首的旧编码出队,负例最多时有 65536 个。
4 实验
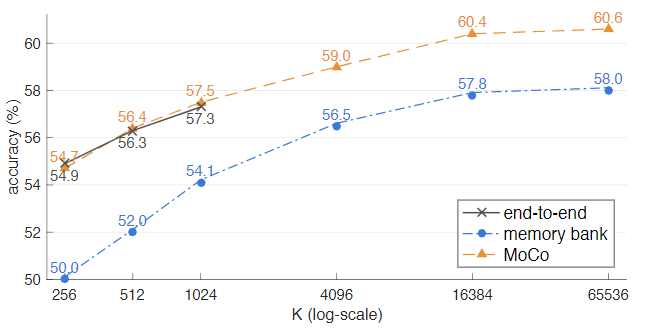
上述图是 ImageNet 线性分类协议下三种对比损失机制的比较。采用相同的 Pretext task ,使用不同的对比机制,研究不同负对数 K 的影响,其中网络使用的是ResNet-50。
MoCo不仅能支持更大的字典大小,而且也能带来更优的效果。可以看到 end-to-end 方式的 K 只研究到 1024 就结束了,因为这种方式受限于内存大小。采用 Memory bank 的方式只比 MoCo 的方式差了大概 2.6% 。

上表显示了在预训练中使用不同 MoCo 动量值的 ResNet-50 精度(此处 K = 4096):
当 m 在 0.99 ∼ 0.9999 时,它表现得相当好,表明缓慢进展(即相对较大的动量)key encoder 是有益的。 当 m 太小时(例如,0.9),准确度大幅下降; 在极端 没有动量(m 为 0),训练损失振荡并且无法收敛。 这些结果支持我们的动机建立一个一致的字典。

可以看到MoCo远远的超过了之前的方法,同时在参数量上也不会有很大的增加。

7个下游任务超越有监督预训练
random init是随机初始化,super.IN-1M是在ImageNet上有监督预训练的,MoCo IN-1M是在ImageNet上自监督预训练的,MoCo IG-1B是在Ins10亿数据上预训练的。
这个的自监督在ImageNet上预训练的模型比有监督的好。就是说自监督得到的特征提取器在一些场景下可以比有监督得到的backbone要好,但是在ImageNet上做分类任务的话,目前只有SimCLR V2超过了有监督的ResNet50。
5 总结
MoCo作为CV领域自监督的文章极大地缩小了自监督模型和监督模型在效果上的距离,自监督作为解决实际生产中标注数据少的方案正在被更多的人发现和研究。相信未来有一天自监督的表现能在有限标注数据的情况下达到甚至超越有监督模型