1 前言
数据准确主要解决训练时遇到数据不足的问题。如为解决一个任务,目前只有小几百的数据,然而目前流行的最先进的神经网络都是成千上万的图片数据。当得到大的数据集是效果好的保证时,对自己数据集小感到失望,为避免我们的模型只在小样本数据上的优势,需要大量数据做支持。
我们需知道目前最领先的神经网络有着数百万的参数!
如果没有很多数据,该怎么去获得更多数据?不必寻找新奇的图片增加到数据集中。为什么?因为,神经网络在开始的时候并不是那么聪明。比如,一个欠训练的神经网络会认为这三个如下的网球是不同、独特的图片。

明显上图是相同的网球,但被移位了。
为获得更多数据,只要对现有的数据集进行微小的改变。如旋转、移位、旋转等微小的改变,网络会认为这是不同的图片。
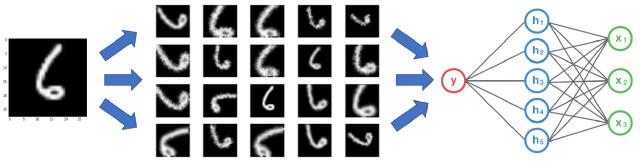
在下面的图像中,对手写数字数据集进行了一些转换。

2 入门
在喂入模型之前,先进行数据增强,此时有两个选项。1:事先执行所有转换,实质上会增强你的数据集的大小。2:在送入模型之前,在小批量(mini-batch)上执行这些转换。
- 第一个选项叫做线下增强(offline augmentation)。这种方法适用于较小的数据集(maller dataset)。最终会增加一定倍数的数据集,这个倍数等于转换的个数。如要翻转所有图片,数据集相当于乘以2。
- 第二种方法叫做线上增强(online augmentation)或在飞行中增强(augmentation on the fly)。这种方法更适用于较大的数据集(larger datasets),因为无法承受爆炸性增加的规模。另外,在喂入模型之前进行小批量的转换。一些机器学习框架支持在线增强,可以再 gpu 上加速。
3 常用数据增强技术
3.1 翻转(Flip)
可以对图片进行水平和垂直翻转。一些框架不提供垂直翻转功能。但是,一个垂直反转的图片等同于图片的180度旋转,然后再执行水平翻转。下面是图片翻转的例子。

3.2 旋转(Rotation)
一个关键性的问题是当旋转之后图像的维数可能并不能保持跟原来一样。如果图片是正方形,那么以直角旋转将会保持图像大小。如果是长方形,那么180度的旋转将会保持原来的大小。以更精细的角度旋转图像也会改变最终的图像尺寸。这里将在下一节中看到我们如何处理这个问题。以下是以直角旋转的方形图像的示例。

3.3 缩放比例(Scale)
图像可以向外或向内缩放。向外缩放时,最终图像尺寸将大于原始图像尺寸。大多数图像框架从新图像中剪切出一个部分,其大小等于原始图像。将在下一节中处理向内缩放,因为它会缩小图像大小,迫使对超出边界的内容做出假设。以下是缩放的示例或图像。

3.4 裁剪(Crop)
与缩放不同,裁剪从原始图像中随机抽样一个部分。然后,将此部分的大小调整为原始图像大小。这种方法通常称为随机裁剪。以下是随机裁剪的示例。

3.5 平移(Translations)
上下左右移动物体。

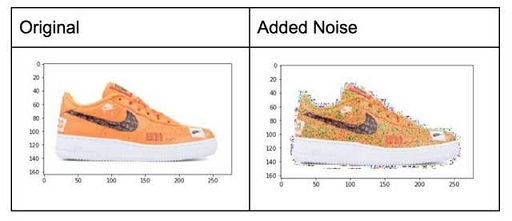
3.6 加噪声–高斯噪声
当神经网络试图学习可能无用的高频特征(大量出现的模式)时,通常会发生过度拟合。具有零均值的高斯噪声基本上在所有频率中具有数据点,从而有效地扭曲高频特征。这也意味着较低频率的组件(通常是您的预期数据)也会失真,但神经网络可以学会超越它。添加适量的噪音可以增强学习能力。
一个色调较低的版本是盐和胡椒噪音,它表现为随机的黑白像素在图像中传播。这类似于通过向图像添加高斯噪声而产生的效果,但可能具有较低的信息失真水平。
4 高级增强技术
-----以后补上