- 文件操作
- 字符编码解码
- 函数基础
- 内置函数
一、文件操作
对文件操作流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读;不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,写读
- a+,追加可写
"U"表示在读取时,可以将 自动转换成 (与 r 或 r+ 模式同使用)
- rU
- r+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
操作实例:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: lvlibing
# __doc__ file
f = open('file','r+',encoding='utf-8')#以读写模式及utf-8编码打开file
file1=f.read()#读取所有内容
file1=f.readline()#只读一行
file1=f.readlines()#读取所有行内容
print(f.tell())#告诉指针位置
f.seek(0)#回到文件的开头
file1=f.readlines()
f.write('
')
f.write('test5
')#写入test5内容并换行
f.write('test6
')
f.flush()#刷新文件数据到磁盘
f.write('test7
')
f.write('test8
')
print(file1)
f.truncate(5)#清空内容,只保留5个字符
print(f.readable())#判读是否可读
print(f.writable())#判读是否可写
f.close()#关闭文件
f = open('file','r+',encoding='utf-8')
f2 = open('file2','w+',encoding='utf-8')
for line in f:
if 'test5' in line:
line = line.replace('test5','test55')#字符串内容替换
f2.write(line)
f.close()
f2.close()
with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
|
1
2
3
|
with open('log','r') as f: ... |
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
with open('t1','w+',encoding='utf-8') as test1 ,
open('t2', 'w+', encoding='utf-8') as test2:
pass
二、字符编码解码
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string

上图仅适用于py2
操作实例:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# __Author__ = 'lvlibing'
# __doc__ = 'practice'
import sys
print(sys.getfilesystemencoding()) #获取系统默认编码
s='编码' #python默认是unicode编码
print(s,type(s),id(s))
s_to_gbk = s.encode('gbk')
print(s_to_gbk,type(s_to_gbk))
s_to_utf8 = s.encode('utf-8')
print(s_to_utf8,type(s_to_utf8))
s_to_gbk_to_utf8 = s_to_gbk.decode('gbk').encode('utf-8') #先解码再编码
print(s_to_gbk_to_utf8,type(s_to_gbk_to_utf8))
s_to_utf8_gbk = s_to_utf8.decode('utf-8').encode('gbk') #先解码再编码
print(s_to_utf8_gbk,type(s_to_utf8_gbk))
三、函数基础
1.函数是什么?
函数是重用的程序段。它们允许你给一个语句块一个名称,然后你用这个名字可以在你的程序的任何地方,任意多次地运行这个语句块。这被称为调用函数。我们已 经使用了许多内建的函数,比如 len 和 range 。 函数用关键字 def 来定义,在BASIC中叫做subroutine(子过程或子程序),在Pascal中叫做procedure(过程)和function,在C中只有function,在Java里面叫做method。def 关键字后跟一个函数的标识符名称,然后跟一对 圆括号。圆括号之中可以包括一些变量名,该行以冒号结尾。接下来是一块语句,它们是函数体。
语法定义如下:
def 函数名(参数):
'''注释''' ... 函数体 ...函数的定义主要有如下要点:
- def:表示函数的关键字
- 函数名:函数的名称,日后根据函数名调用函数
- 函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等
- 参数:为函数体提供数据
- 返回值:当函数执行完毕后,可以给调用者返回数据。
特性:
- 减少重复代码
- 使程序变的可扩展
- 使程序变得易维护
2.函数参数与局部变量
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
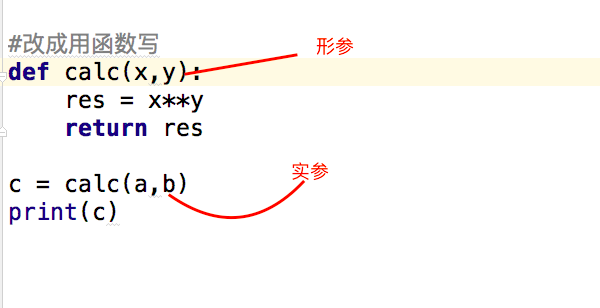
实例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#下面这段代码a,b = 5,8c = a**bprint(c)#改成用函数写def calc(x,y): res = x**y return res #返回函数执行结果c = calc(a,b) #结果赋值给c变量print(c) |
默认参数(关键参数)
给函数形参指定默认的值的就是称为默认参数。这样,如果这个参数在调用时不指定,那就是使用默认的,如果指定了的话,就用你指定的值。正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后。
非固定参数
若你的函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数。
全局与局部变量
3.返回值
要想获取函数的执行结果,就可以用return语句把结果返回
注意:
- 函数在执行过程中只要遇到return语句,就会停止执行并返回结果,so 也可以理解为 return 语句代表着函数的结束
- 如果未在函数中指定return,那这个函数的返回值为None
实例:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# __Author__ = 'lvlibing'
# __doc__ = 'practice'
import time#导入time模块
time_format = time.strftime('%Y/%m/%d %X')
#print(time_format)
def logger():#定义一个logger函数
with open('log','a+') as f:
f.write('%s append
' %time_format)
def fun1():
print('fun1')
logger()#调用logger函数
def fun2():
print('fun2')
logger()
return 0#返回指定为0的数值,如果后面有代码将不会执行。如未在函数中指定return,那这个函数的返回值为None。
def fun3():
print('fun3')
logger()
return 1,'string',[1,2,3],{4,5,6},(7,8,9)#以元组的形式返回指定的文字
x=fun2()#函数调用赋值给x
y=fun3()
z=fun1()
print('---')
# print(fun1())
# print(z,y,x)
print(x)
print(y)
print(z)
def func1(a,b,c):#位置参数,也是形参
print(a)
print(b)
print(c)
func1(1,2,3)#实参,函数调用和赋值
def func2(a=8,b=9,*args):#a,b默认参数,*args非固定参数,会把多个传入的参数变成一个元组形式
print(a)
print(b)
print(args)
func2(1,2,3,4,5)
def func3(a=8,b=9,**kwargs):#**kwargs非固定参数会把多个传入的参数变成一个dict形式
print(a)
print(b)
print(kwargs)
#func2(name='lv', age='21')
func3(a=1,b=2,name='lv',age='21')
def func4(a,b=9,*args,**kwargs):
print(a)
print(b)
print(args)
print(kwargs)
func4(1,b=2,name='lv',age='21',sex='gentleman')
# func4(1,2,3,4,name='lv',age='21',sex='gentleman')
name='oldboy'#全局变量
def func5():
global name#设置为全局变量
name='mage'#局部变量
print(name)
func5()
print(name)
4.递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
实例:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# __Author__ = 'lvlibing'
# __doc__ = 'practice'
def calc(n):
print(n)
if int(n/2) > 0:
return calc(int(n/2))
print('--',n)
calc(100)
'''斐波那契数列
def func(arg1,arg2):
if arg1 == 0:
print(arg1, arg2)
arg3 = arg1 + arg2
print(arg3)
func(arg2, arg3)
func(0,1)
'''
5.高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
def add(x,y,f):
return f(x) + f(y)
res = add(3,-6,abs)
print(res)
四、内置函数
内置函数一:

详细见python文档:https://docs.python.org/3.6/library/functions.html
内置函数二:
一、filter
对于序列中的元素进行筛选,最终获取符合条件的序列

二、map
遍历序列,对序列中每个元素进行操作,最终获取新的序列。

三、reduce
对于序列内所有元素进行累计操作

代码实例:


1 res0 = [ lambda n:n*2 for n in range(10) ] 2 res1 = filter(lambda n:n>5,range(10))#对于序列中的元素进行筛选,最终获取符合条件的序列 3 res2 = map(lambda n:n*2,range(10))#遍历序列,对序列中每个元素进行操作,最终获取新的序列。 4 import functools 5 res3 = functools.reduce(lambda x,y:x+y,range(1,10))#对于序列内所有元素进行累计操作 6 7 for i in res1: 8 print(i) 9 print() 10 for i in res2: 11 print(i) 12 print() 13 print(res3)
# -*- coding:utf-8 -*-
__author__ = 'BillyLV'
a=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
m = map(lambda x:x+1,a)
for i in m:print('i',i)
f = filter(lambda x: x > 3,a)
for ff in f:print(ff)
import functools
result = functools.reduce(lambda arg1, arg2: arg1 + arg2, a)
print(result)
li = [11, 22, 33]
new_list = map(lambda a: a + 100, li)
for i in new_list:
print(i)
li = [11, 22, 33]
sl = [1, 2, 3]
new_list2 = map(lambda a, b: a + b, li, sl)
for i in new_list2:
print(i)
a = [1,2,3,4,5]
b = ['a','b','c','d','e']
x = zip(a,b)
for i in x:
print('zip拉链',i)
参考:
http://www.cnblogs.com/alex3714
http://www.cnblogs.com/wupeiqi
internet&python books
PS:如侵权,联我删。