- Python介绍
- python2和python3的主要区别
- 安装
- Hello World程序
- 变量
- 字符编码
- 用户输入
- .pyc是什么
- 控制流语句
一、 Python介绍
Python的创始人为Guido van Rossum,1989年的圣诞节期间,他为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
Python是一种简单易学,功能强大的编程语言,它有高效率的高层数据结构,简单而有效地实现面向对象编程。Python简洁的语法和对动态输入的支持,再加上解释性语言的本质,使得它在大多数平台上的许多领域都是一个理想的脚本语言,特别适用于快速的应用程序开发。Python语法简洁清晰,特色之一是强制用空白符(white space)作为语句缩进。Python具有丰富和强大的库。它常被昵称为胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。
最新的TIOBE排行榜,Python排第三。

由上图可见,Python整体呈上升趋势,反映出Python应用越来越广泛并且也逐渐得到业内的认可!
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、Quora、Google、Yahoo!、Facebook、NASA、百度、腾讯、汽车之家、美团、大众点评、豆瓣、知乎等。
目前Python主要应用领域:
- 云计算: 云计算最火的语言, 典型应用OpenStack
- WEB开发: 众多优秀的WEB框架,众多大型网站均为Python开发,Youtube, Dropbox, 豆瓣等, 典型WEB框架有Django
- 科学运算、人工智能: 典型库NumPy, SciPy, Matplotlib, Enthought librarys,pandas
- 系统运维: 运维人员
- 金融:量化交易,金融分析,在金融工程领域,Python不但在用,且用的最多,而且重要性逐年提高。原因:作为动态语言的Python,语言结构清晰简单,库丰富,成熟稳定,科学计算和统计分析都很强,生产效率远远高于c,c++,java,尤其擅长策略回测
- 图形GUI: PyQT, WxPython,TkInter
Python在一些公司的应用:
- 谷歌:Google App Engine 、code.google.com 、Google earth 、谷歌爬虫、Google广告等项目都在大量使用Python开发
- CIA: 美国中情局网站就是用Python开发的
- NASA: 美国航天局(NASA)大量使用Python进行数据分析和运算
- YouTube:世界上最大的视频网站YouTube就是用Python开发的
- Dropbox:美国最大的在线云存储网站,全部用Python实现,每天网站处理10亿个文件的上传和下载
- Instagram:美国最大的图片分享社交网站,每天超过3千万张照片被分享,全部用python开发
- Facebook:大量的基础库均通过Python实现的
- Redhat: 世界上最流行的Linux发行版本中的yum包管理工具就是用python开发的
- 豆瓣: 公司几乎所有的业务均是通过Python开发的
- 知乎: 国内最大的问答社区,通过Python开发(国外Quora)
- 春雨医生:国内知名的在线医疗网站是用Python开发的
- 除上面之外,还有搜狐、金山、腾讯、盛大、网易、百度、阿里、淘宝 、土豆、新浪、果壳等公司都在使用Python完成各种各样的任务。
Python是一门什么样的语言?
编程语言主要从以下几个角度为进行分类,编译型和解释型、静态语言和动态语言、强类型定义语言和弱类型定义语言,每个分类代表什么意思呢,我们一起来看一下。
编译和解释的区别是什么?
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
这是因为计算机不能直接认识并执行我们写的语句,它只能认识机器语言(是二进制的形式)


编译型vs解释型
编译型
优点:编译器一般会有预编译的过程对代码进行优化。因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行。
缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件。
解释型
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。
一、低级语言与高级语言
最初的计算机程序都是用0和1的序列表示的,程序员直接使用的是机器指令,无需翻译,从纸带打孔输入即可执行得到结果。后来为了方便记忆,就将用0、1序列表示的机器指令都用符号助记,这些与机器指令一一对应的助记符就成了汇编指令,从而诞生了汇编语言。无论是机器指令还是汇编指令都是面向机器的,统称为低级语言。因为是针对特定机器的机器指令的助记符,所以汇编语言是无法独立于机器(特定的CPU体系结构)的。但汇编语言也是要经过翻译成机器指令才能执行的,所以也有将运行在一种机器上的汇编语言翻译成运行在另一种机器上的机器指令的方法,那就是交叉汇编技术。
高级语言是从人类的逻辑思维角度出发的计算机语言,抽象程度大大提高,需要经过编译成特定机器上的目标代码才能执行,一条高级语言的语句往往需要若干条机器指令来完成。高级语言独立于机器的特性是靠编译器为不同机器生成不同的目标代码(或机器指令)来实现的。那具体的说,要将高级语言编译到什么程度呢,这又跟编译的技术有关了,既可以编译成直接可执行的目标代码,也可以编译成一种中间表示,然后拿到不同的机器和系统上去执行,这种情况通常又需要支撑环境,比如解释器或虚拟机的支持,Java程序编译成bytecode,再由不同平台上的虚拟机执行就是很好的例子。所以,说高级语言不依赖于机器,是指在不同的机器或平台上高级语言的程序本身不变,而通过编译器编译得到的目标代码去适应不同的机器。从这个意义上来说,通过交叉汇编,一些汇编程序也可以获得不同机器之间的可移植性,但这种途径获得的移植性远远不如高级语言来的方便和实用性大。
二、编译与解释
编译是将源程序翻译成可执行的目标代码,翻译与执行是分开的;而解释是对源程序的翻译与执行一次性完成,不生成可存储的目标代码。这只是表象,二者背后的最大区别是:对解释执行而言,程序运行时的控制权在解释器而不在用户程序;对编译执行而言,运行时的控制权在用户程序。
解释具有良好的动态特性和可移植性,比如在解释执行时可以动态改变变量的类型、对程序进行修改以及在程序中插入良好的调试诊断信息等,而将解释器移植到不同的系统上,则程序不用改动就可以在移植了解释器的系统上运行。同时解释器也有很大的缺点,比如执行效率低,占用空间大,因为不仅要给用户程序分配空间,解释器本身也占用了宝贵的系统资源。编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
编译型和解释型
我们先看看编译型,其实它和汇编语言是一样的:也是有一个负责翻译的程序来对我们的源代码进行转换,生成相对应的可执行代码。这个过程说得专业一点,就称为编译(Compile),而负责编译的程序自然就称为编译器(Compiler)。如果我们写的程序代码都包含在一个源文件中,那么通常编译之后就会直接生成一个可执行文件,我们就可以直接运行了。但对于一个比较复杂的项目,为了方便管理,我们通常把代码分散在各个源文件中,作为不同的模块来组织。这时编译各个文件时就会生成目标文件(Object file)而不是前面说的可执行文件。一般一个源文件的编译都会对应一个目标文件。这些目标文件里的内容基本上已经是可执行代码了,但由于只是整个项目的一部分,所以我们还不能直接运行。待所有的源文件的编译都大功告成,我们就可以最后把这些半成品的目标文件“打包”成一个可执行文件了,这个工作由另一个程序负责完成,由于此过程好像是把包含可执行代码的目标文件连接装配起来,所以又称为链接(Link),而负责链接的程序就叫……就叫链接程序(Linker)。链接程序除了链接目标文件外,可能还有各种资源,像图标文件啊、声音文件啊什么的,还要负责去除目标文件之间的冗余重复代码,等等,所以……也是挺累的。链接完成之后,一般就可以得到我们想要的可执行文件了。
上面我们大概地介绍了编译型语言的特点,现在再看看解释型。噢,从字面上看,“编译”和“解释”的确都有“翻译”的意思,它们的区别则在于翻译的时机安排不大一样。打个比方:假如你打算阅读一本外文书,而你不知道这门外语,那么你可以找一名翻译,给他足够的时间让他从头到尾把整本书翻译好,然后把书的母语版交给你阅读;或者,你也立刻让这名翻译辅助你阅读,让他一句一句给你翻译,如果你想往回看某个章节,他也得重新给你翻译。
两种方式,前者就相当于我们刚才所说的编译型:一次把所有的代码转换成机器语言,然后写成可执行文件;而后者就相当于我们要说的解释型:在程序运行的前一刻,还只有源程序而没有可执行程序;而程序每执行到源程序的某一条指令,则会有一个称之为解释程序的外壳程序将源代码转换成二进制代码以供执行,总言之,就是不断地解释、执行、解释、执行……所以,解释型程序是离不开解释程序的。像早期的BASIC就是一门经典的解释型语言,要执行BASIC程序,就得进入BASIC环境,然后才能加载程序源文件、运行。解释型程序中,由于程序总是以源代码的形式出现,因此只要有相应的解释器,移植几乎不成问题。编译型程序虽然源代码也可以移植,但前提是必须针对不同的系统分别进行编译,对于复杂的工程来说,的确是一件不小的时间消耗,况且很可能一些细节的地方还是要修改源代码。而且,解释型程序省却了编译的步骤,修改调试也非常方便,编辑完毕之后即可立即运行,不必像编译型程序一样每次进行小小改动都要耐心等待漫长的Compiling…Linking…这样的编译链接过程。不过凡事有利有弊,由于解释型程序是将编译的过程放到执行过程中,这就决定了解释型程序注定要比编译型慢上一大截,像几百倍的速度差距也是不足为奇的。
编译型与解释型,两者各有利弊。前者由于程序执行速度快,同等条件下对系统要求较低,因此像开发操作系统、大型应用程序、数据库系统等时都采用它,像C/C++、Pascal/Object Pascal(Delphi)、VB等基本都可视为编译语言,而一些网页脚本、服务器脚本及辅助开发接口这样的对速度要求不高、对不同系统平台间的兼容性有一定要求的程序则通常使用解释性语言,如Java、JavaScript、VBScript、Perl、Python等等。
但既然编译型与解释型各有优缺点又相互对立,所以一批新兴的语言都有把两者折衷起来的趋势,例如Java语言虽然比较接近解释型语言的特征,但在执行之前已经预先进行一次预编译,生成的代码是介于机器码和Java源代码之间的中介代码,运行的时候则由JVM(Java的虚拟机平台,可视为解释器)解释执行。它既保留了源代码的高抽象、可移植的特点,又已经完成了对源代码的大部分预编译工作,所以执行起来比“纯解释型”程序要快许多。而像VB6(或者以前版本)、C#这样的语言,虽然表面上看生成的是.exe可执行程序文件,但VB6编译之后实际生成的也是一种中介码,只不过编译器在前面安插了一段自动调用某个外部解释器的代码(该解释程序独立于用户编写的程序,存放于系统的某个DLL文件中,所有以VB6编译生成的可执行程序都要用到它),以解释执行实际的程序体。C#(以及其它.net的语言编译器)则是生成.net目标代码,实际执行时则由.net解释系统(就像JVM一样,也是一个虚拟机平台)进行执行。当然.net目标代码已经相当“低级”,比较接近机器语言了,所以仍将其视为编译语言,而且其可移植程度也没有Java号称的这么强大,Java号称是“一次编译,到处执行”,而.net则是“一次编码,到处编译”。呵呵,当然这些都是题外话了。总之,随着设计技术与硬件的不断发展,编译型与解释型两种方式的界限正在不断变得模糊。动态语言和静态语言
通常我们所说的动态语言、静态语言是指动态类型语言和静态类型语言。(1)动态类型语言:动态类型语言是指在运行期间才去做数据类型检查的语言,也就是说,在用动态类型的语言编程时,永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。Python和Ruby就是一种典型的动态类型语言,其他的各种脚本语言如VBScript也多少属于动态类型语言。
(2)静态类型语言:静态类型语言与动态类型语言刚好相反,它的数据类型是在编译其间检查的,也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#、JAVA等。
强类型定义语言和弱类型定义语言
(1)强类型定义语言:强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。举个例子:如果你定义了一个整型变量a,那么程序根本不可能将a当作字符串类型处理。强类型定义语言是类型安全的语言。
(2)弱类型定义语言:数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。
强类型定义语言在速度上可能略逊色于弱类型定义语言,但是强类型定义语言带来的严谨性能够有效的避免许多错误。另外,“这门语言是不是动态语言”与“这门语言是否类型安全”之间是完全没有联系的!
例如:Python是动态语言,是强类型定义语言(类型安全的语言); VBScript是动态语言,是弱类型定义语言(类型不安全的语言); JAVA是静态语言,是强类型定义语言(类型安全的语言)。
通过上面这些介绍,我们可以得出,python是一门动态解释性的强类型定义语言。那这些基因使成就了Python的哪些优缺点呢?我们继续往下看。
Python的优缺点
优点:
- Python的定位是“优雅”、“明确”、“简单”,所以Python程序看上去总是简单易懂,初学者学Python,不但入门容易,而且将来深入下去,可以编写那些非常非常复杂的程序。
- 开发效率非常高,Python有非常强大的第三方库,基本上你想通过计算机实现任何功能,Python官方库里都有相应的模块进行支持,直接下载调用后,在基础库的基础上再进行开发,大大降低开发周期,避免重复造轮子。
- 高级语言————当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内存一类的底层细节
- 可移植性————由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工 作在不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修改就几乎可以在市场上所有的系统平台上运行
- 可扩展性————如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。
- 可嵌入性————你可以把Python嵌入你的C/C++程序,从而向你的程序用户提供脚本功能。
缺点:
- 速度慢,Python 的运行速度相比C语言确实慢很多,跟JAVA相比也要慢一些,因此这也是很多所谓的大牛不屑于使用Python的主要原因,但其实这里所指的运行速度慢在大多数情况下用户是无法直接感知到的,必须借助测试工具才能体现出来,比如你用C运一个程序花了0.01s,用Python是0.1s,这样C语言直接比Python快了10倍,算是非常夸张了,但是你是无法直接通过肉眼感知的,因为一个正常人所能感知的时间最小单位是0.15-0.4s左右,哈哈。其实在大多数情况下Python已经完全可以满足你对程序速度的要求,除非你要写对速度要求极高的搜索引擎等,这种情况下,当然还是建议你用C去实现的。
- 代码不能加密,因为PYTHON是解释性语言,它的源码都是以名文形式存放的,不过我不认为这算是一个缺点,如果你的项目要求源代码必须是加密的,那你一开始就不应该用Python来去实现。
- 线程不能利用多CPU问题,这是Python被人诟病最多的一个缺点,GIL即全局解释器锁(Global Interpreter Lock),是计算机程序设计语言解释器用于同步线程的工具,使得任何时刻仅有一个线程在执行,Python的线程是操作系统的原生线程。在Linux上为pthread,在Windows上为Win thread,完全由操作系统调度线程的执行。一个python解释器进程内有一条主线程,以及多条用户程序的执行线程。即使在多核CPU平台上,由于GIL的存在,所以禁止多线程的并行执行。关于这个问题的折衷解决方法,我们在以后线程和进程章节里再进行详细探讨。
Python的特色
- 简单
-
Python是一种代表简单主义思想的语言。阅读一个良好的Python程序就感觉像是在读英语一样,尽管这个英语的要求非常严格!Python的这种伪代码本质是它最大的优点之一。它使你能够专注于解决问题而不是去搞明白语言本身。
- 易学
-
就如同你即将看到的一样,Python极其容易上手。前面已经提到了,Python有极其简单的语法。
- 免费、开源
-
Python是FLOSS(自由/开放源码软件)之一。简单地说,你可以自由地发布这个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。FLOSS是基于一个团体分享知识的概念。这是为什么Python如此优秀的原因之一——它是由一群希望看到一个更加优秀的Python的人创造并经常改进着的。
- 高层语言
-
当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内存一类的底层细节。
- 可移植性
-
由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工作在不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修改就可以在下述任何平台上面运行。
这些平台包括Linux、Windows、FreeBSD、Macintosh、Solaris、OS/2、Amiga、AROS、AS/400、BeOS、OS/390、z/OS、Palm OS、QNX、VMS、Psion、Acom RISC OS、VxWorks、PlayStation、Sharp Zaurus、Windows CE甚至还有PocketPC!
- 解释性
-
这一点需要一些解释。
一个用编译性语言比如C或C++写的程序可以从源文件(即C或C++语言)转换到一个你的计算机使用的语言(二进制代码,即0和1)。这个过程通过编译器和不同的标记、选项完成。当你运行你的程序的时候,连接/转载器软件把你的程序从硬盘复制到内存中并且运行。
而Python语言写的程序不需要编译成二进制代码。你可以直接从源代码 运行 程序。在计算机内部,Python解释器把源代码转换成称为字节码的中间形式,然后再把它翻译成计算机使用的机器语言并运行。事实上,由于你不再需要担心如何编译程序,如何确保连接转载正确的库等等,所有这一切使得使用Python更加简单。由于你只需要把你的Python程序拷贝到另外一台计算机上,它就可以工作了,这也使得你的Python程序更加易于移植。
- 面向对象
-
Python即支持面向过程的编程也支持面向对象的编程。在 面向过程 的语言中,程序是由过程或仅仅是可重用代码的函数构建起来的。在 面向对象 的语言中,程序是由数据和功能组合而成的对象构建起来的。与其他主要的语言如C++和Java相比,Python以一种非常强大又简单的方式实现面向对象编程。
- 可扩展性
-
如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。
- 可嵌入性
-
你可以把Python嵌入你的C/C++程序,从而向你的程序用户提供脚本功能。
- 丰富的库
-
Python标准库确实很庞大。它可以帮助你处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。记住,只要安装了Python,所有这些功能都是可用的。这被称作Python的“功能齐全”理念。
Python解释器
当我们编写Python代码时,我们得到的是一个包含Python代码的以.py为扩展名的文本文件。要运行代码,就需要Python解释器去执行.py文件。
由于整个Python语言从规范到解释器都是开源的,所以理论上,只要水平够高,任何人都可以编写Python解释器来执行Python代码(当然难度很大)。事实上,确实存在多种Python解释器。
CPython
当我们从Python官方网站下载并安装好Python 2.7后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
CPython是使用最广的Python解释器。教程的所有代码也都在CPython下执行。
IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。
CPython用>>>作为提示符,而IPython用In [序号]:作为提示符。
PyPy
PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。
绝大部分Python代码都可以在PyPy下运行,但是PyPy和CPython有一些是不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy下执行,就需要了解PyPy和CPython的不同点。
Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
小结
Python的解释器很多,但使用最广泛的还是CPython。如果要和Java或.Net平台交互,最好的办法不是用Jython或IronPython,而是通过网络调用来交互,确保各程序之间的独立性。
二、python2和python3的主要区别
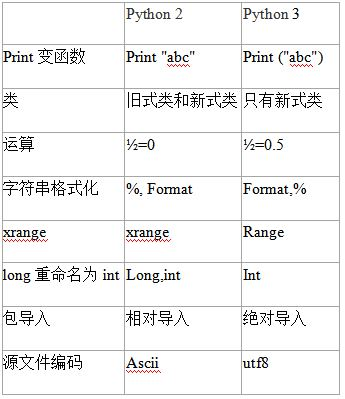
可以在Python2.7中引用Python的__future__库,__future__库里面包含了Python3的大多特性。
三、Python安装
windows
|
1
2
3
4
5
6
7
|
1、下载安装包 https://www.python.org/downloads/2、安装 默认安装路径:C:python273、配置环境变量 【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用 ; 分割】 如:原来的值;C:python27,切记前面有分号 |
linux、Mac
|
1
2
3
|
无需安装,原装Python环境 ps:如果自带2.6,请更新至2.7 |
四、Hello World程序
在linux 下创建一个文件叫hello.py,并输入
|
1
|
print("Hello World!") |
然后执行命令:python hello.py ,输出
|
1
2
3
|
localhost:~ jieli$ vim hello.pylocalhost:~ jieli$ python hello.pyHello World! |
python内部执行过程如下:
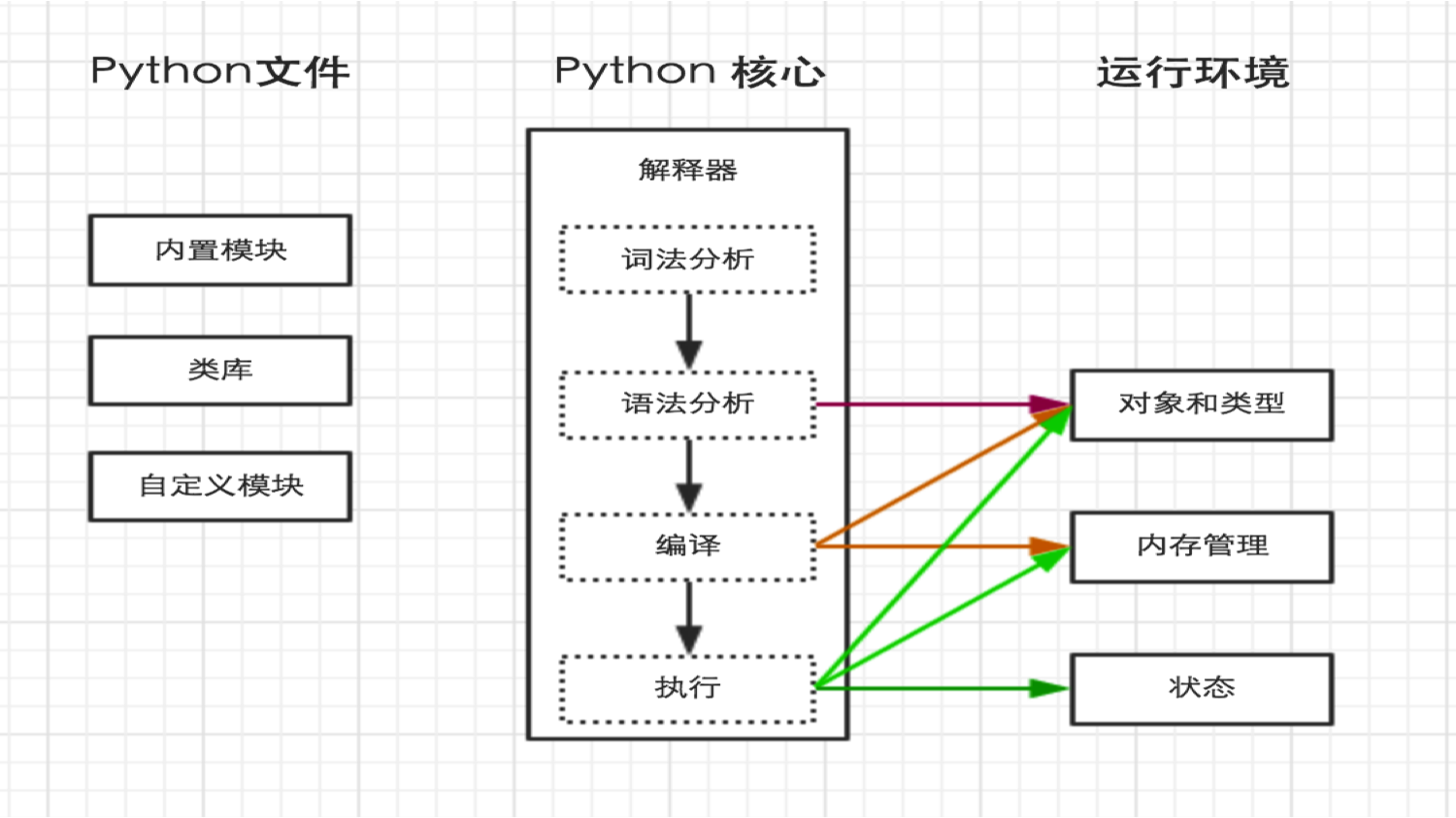
指定解释器
上一步中执行 python hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需要在 hello.py 文件的头部指定解释器,如下:
|
1
2
3
|
#!/usr/bin/env python print "hello,world" |
执行前需给予 hello.py 执行权限,chmod 755 hello.py,执行: ./hello.py(只适用于*unix) 即可。
在交互器中执行
除了把程序写在文件里,还可以直接调用python自带的交互器运行代码,
|
1
2
3
4
5
6
|
localhost:~ jieli$ pythonPython 2.7.10 (default, Oct 23 2015, 18:05:06)[GCC 4.2.1 Compatible Apple LLVM 7.0.0 (clang-700.0.59.5)] on darwinType "help", "copyright", "credits" or "license" for more information.>>> print("Hello World!")Hello World! |
五、变量
声明变量
|
1
2
3
|
#_*_coding:utf-8_*_name = "wupeiqi" |
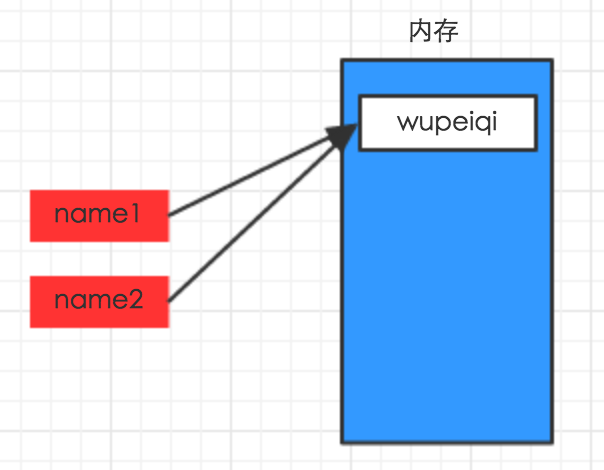
上述代码声明了一个变量,变量名为: name,变量name的值为:"wupeiqi"
变量的作用:昵称,其代指内存里某个地址中保存的内容
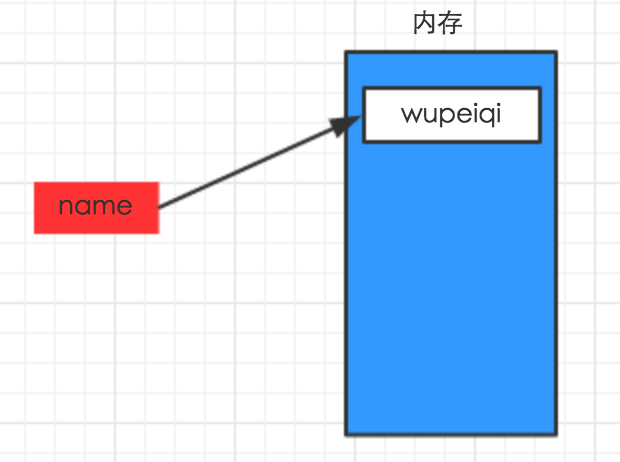
变量定义的规则:
- 变量名只能是字母、数字或下划线的任意组合且不能以数字开头
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']

#!/usr/bin/env python # -*- coding: utf-8 -*- name1 = "wupeiqi" name2 = "alex"
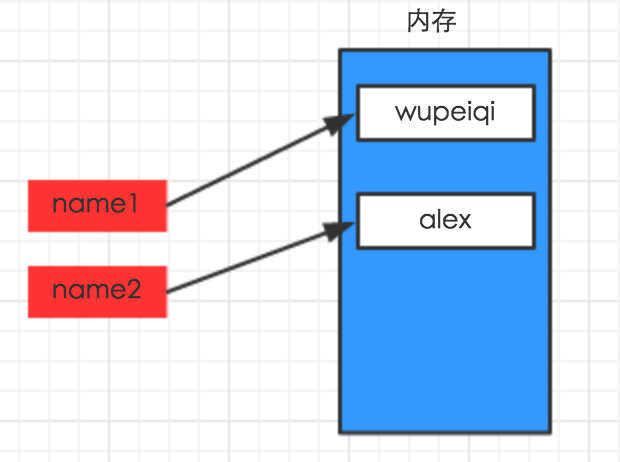
#!/usr/bin/env python # -*- coding: utf-8 -*- name1 = "wupeiqi" name2 = name1
六、字符编码
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。

- 二进制,01
- 八进制,01234567
- 十进制,0123456789
- 十六进制,0123456789ABCDEF 二进制到16进制转换http://jingyan.baidu.com/album/47a29f24292608c0142399cb.html?picindex=1
关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
|
1
2
3
|
#!/usr/bin/env python print "你好,世界" |
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
|
1
2
3
4
|
#!/usr/bin/env python# -*- coding: utf-8 -*- print "你好,世界" |
注释
单行注释:# 被注释内容
多行注释:""" 被注释内容 """ 或 ''' 被注释内容 '''
#!/usr/bin/env python # -*- coding:utf-8 -*- msg = '编码' print(msg) print(msg.encode(encoding='utf-8')) print(msg.encode(encoding='utf-8').decode(encoding='utf-8'))
七、用户输入
|
1
2
3
4
5
6
7
|
#!/usr/bin/env python#_*_coding:utf-8_*_#name = raw_input("What is your name?") #only on python 2.xname = input("What is your name?")print("Hello " + name ) |
输入密码时,如果想要不可见,需要利用getpass 模块中的 getpass方法,即:
|
1
2
3
4
5
6
7
8
9
10
|
#!/usr/bin/env python# -*- coding: utf-8 -*- import getpass # 将用户输入的内容赋值给 name 变量pwd = getpass.getpass("请输入密码:") # 打印输入的内容print(pwd) |
八、.pyc是什么
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
九、控制流语句
if ... else
if 语句用来检验一个条件,如果条件为真,我们运行一块语句(称为 if-块),否则我们处理另外一块语句(称为 else-块)。else子句是可选的。
场景一、用户登陆验证

while ... else
只要在一个条件为真的情况下, while 语句允许你重复执行一块语句。 while 语 句是所谓循环语句的一个例子。 while 语句有一个可选的 else 从句。
break 语句是用来终止循环语句的,即哪怕循环条件没有变为 False 或序列还没有 被完全迭代结束,也停止执行循环语句。 如果你从 for 或 while 循环中终止,任何对应的循环 else 块将不执行。
continue 语句被用来告诉 Python 跳过当前循环块中的剩余语句,然后继续进行下一轮循环。
场景二、猜年龄游戏

for ... else
for..in 是另外一个循环语句,它在一序列的对象上迭代,即逐一使用序列中的每个项目。
场景三、循环100次后并输出完成

参考:
http://www.cnblogs.com/alex3714/articles/5465198.html
http://www.cnblogs.com/wupeiqi/articles/4906230.html
internet&python books
PS:如侵权,联我删。