1.下载spark,python包
略
2.环境变量配置
打开 ~/.bashrc配置文件
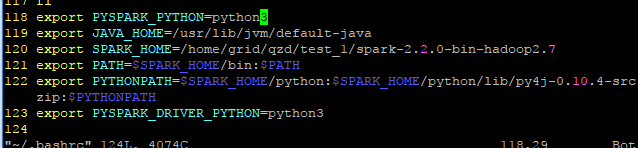
如图添加下列环境变量及path
3.退出配置文件,输入 source ~/.bashrc 来执行你添加的一些配置
4. vim test.py
from pyspark import SparkContext
sc = SparkContext(master = 'local[2]', appName = 'test_4')
logFile = "/home/grid/qzd/test_1/spark-2.2.0-bin-hadoop2.7/README.md"
logData = sc.textFile(logFile,2).cache()
numAs = logData.filter(lambda line: 'a' in line ).count()
numBs = logData.filter(lambda line: 'b' in line ).count()
print('Lines with a: %s , Lines with b : %s '%(numAs,numBs))
5.python3 test.py
如图,编译成功

* 6. 但是,当我在jupyter中执行如上4中的代码时还是会报错,看了stack,有很多种方法(如关防火墙,执行java程序来启动JVM等)都不行。最后,只能在driver端执行。