最近看了一下深度学习的表征学习,总结并记录与一下学习笔记。
1.在标签数据集中做的监督学习容易导致过拟合,半监督学习由于可以从无标签数据集中学习,可以有一定概率化解这种情况。
2.深度学习所使用的算法不能太复杂,否则会加大计算复杂度和工作量。
3.逐层贪婪的无监督预训练有这几个特点:
(1)贪婪:基于贪婪算法,独立优化问题解的各方面,但是每次只优化一个方面,而不是同时同步全局优化。
(2)逐层:各个独立方面可以看做网络的每一层,每次训练的第i层,都会固定前面的所有层。
(3)无监督:每次训练都是无监督表征学习算法。
(4)预训练:训练前的一步操作。
4.在分类任务中减少测试误差,初始化的参数选择对模型产生显著正则化影响,通俗点就是优化效果更明显。
5.无监督预训练还是有一些缺点的,比如需要两个或更多的训练阶段,则需要更多的参数来支持,同时使用有监督和无监督时,通常只需要一个超参。额外项系数减少,优化效果会相应减少
6.无监督学习的四种实现模型
(1)自动编码器,优点是技术简单重建输入,可堆栈多层,直觉型基于神经科学研究
缺点是贪婪训练每一层,没有全局优化,比不上监督学习表现,层一多会失效
(2)聚类学习优点聚类相似输出可被多层堆栈,直觉型且基于神经科学研究。
缺点是贪婪训练每一层没有全局优化,在一些情况下比不上监督学习的表现,层数增加会失效,收益递减。特别的,受限RBMs,DBMs,DBNs难以训练,而配分函数的数值难题,还未普遍用来解决问题。
(3)生成模型,尝试在同一个时间创建一个分类网络和一个生成图像模型。
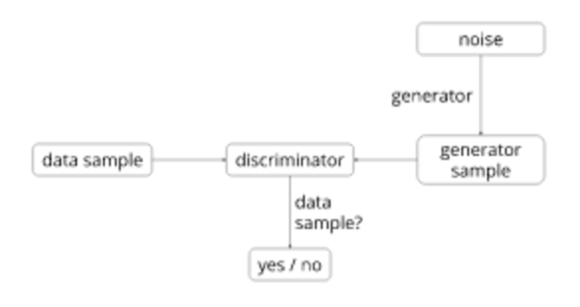
优点是整个全局训练
缺点难以训练和转化,在某些情况下和监督学习表现相似,需要论证展示方法的可用性