作为一名Pythoner,相信大家对Python的就业前景或多或少会有一些关注。索性我们就写一个爬虫去获取一些我们需要的信息,今天我们要爬取的是前程无忧!说干就干!进入到前程无忧的官网,输入关键字“Python”,我们会得到下面的页面

我们可以看到这里罗列了"职位名"、"公司名"、"工作地点"、"薪资"、"发布时间",那么我们就把这些信息爬取下来吧!确定了需求,下一步我们就审查元素找到我们所需信息所在的标签,再写一个正则表达式把元素筛选出来就可以了!

顺理成章得到这样一个正则表达式:
reg = re.compile(r'class="t1 ">.*? <a target="_blank" title="(.*?)".*? <span class="t2"><a target="_blank" title="(.*?)".*?<span class="t3">(.*?)</span>.*?<span class="t4">(.*?)</span>.*? <span class="t5">(.*?)</span>',re.S)
完成这关键的一步,下面写入本地就灰常简单了!还是来段代码吧!
1 # -*- coding:utf-8 -*- 2 import urllib.request 3 import re 4 5 #获取原码 6 def get_content(page): 7 url ='http://search.51job.com/list/000000,000000,0000,00,9,99,python,2,'+ str(page)+'.html' 8 a = urllib.request.urlopen(url)#打开网址 9 html = a.read().decode('gbk')#读取源代码并转为unicode 10 return html 11 12 def get(html): 13 reg = re.compile(r'class="t1 ">.*? <a target="_blank" title="(.*?)".*? <span class="t2"><a target="_blank" title="(.*?)".*?<span class="t3">(.*?)</span>.*?<span class="t4">(.*?)</span>.*? <span class="t5">(.*?)</span>',re.S)#匹配换行符 14 items=re.findall(reg,html) 15 return items 16 17 #多页处理,下载到文件 18 for j in range(1,10): 19 print("正在爬取第"+str(j)+"页数据...") 20 html=get_content(j)#调用获取网页原码 21 for i in get(html): 22 #print(i[0],i[1],i[2],i[3],i[4]) 23 with open ('51job.txt','a',encoding='utf-8') as f: 24 f.write(i[0]+' '+i[1]+' '+i[2]+' '+i[3]+' '+i[4]+' ') 25 f.close()
再来一张效果图
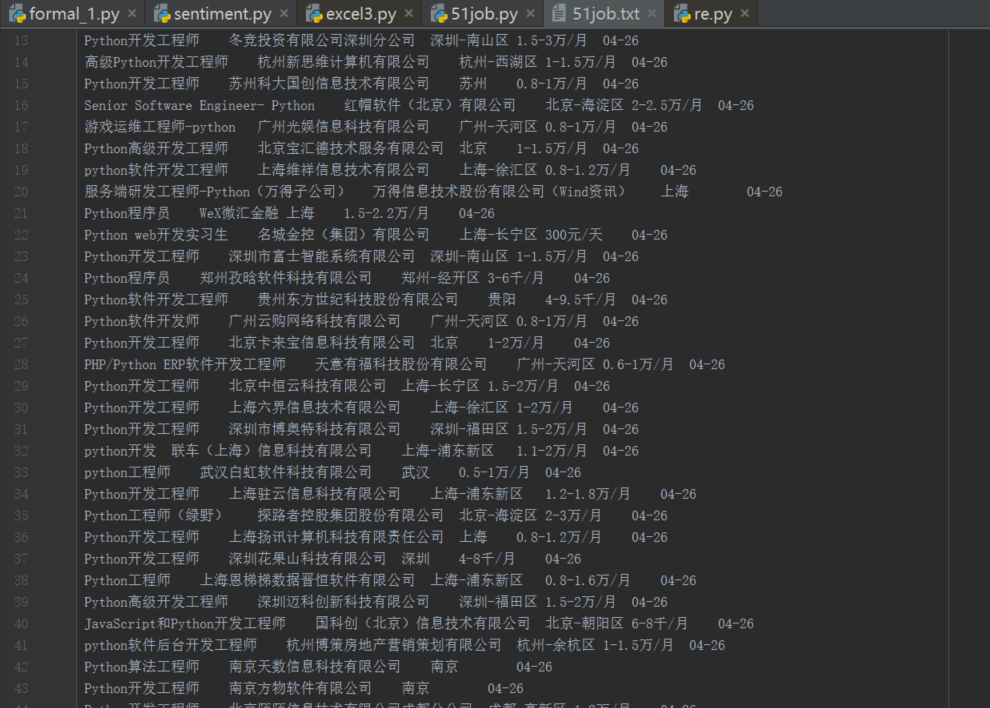
看起来效果还不错,要是能够以表格的形式展示出来就更好了,在网上看到有的大佬直接把招聘信息写入excel表格,今天我也来试一下吧!其实也并麻烦,只需要将上面的代码稍加修改就可以了。下面贴一下代码,重要的地方会有注释。
1 # -*- coding:utf-8 -*- 2 import urllib.request 3 import re 4 import xlwt#用来创建excel文档并写入数据 5 6 #获取原码 7 def get_content(page): 8 url ='http://search.51job.com/list/000000,000000,0000,00,9,99,python,2,'+ str(page)+'.html' 9 a = urllib.request.urlopen(url)#打开网址 10 html = a.read().decode('gbk')#读取源代码并转为unicode 11 return html 12 13 def get(html): 14 reg = re.compile(r'class="t1 ">.*? <a target="_blank" title="(.*?)".*? <span class="t2"><a target="_blank" title="(.*?)".*?<span class="t3">(.*?)</span>.*?<span class="t4">(.*?)</span>.*? <span class="t5">(.*?)</span>',re.S)#匹配换行符 15 items = re.findall(reg,html) 16 return items 17 def excel_write(items,index): 18 19 #爬取到的内容写入excel表格 20 for item in items:#职位信息 21 for i in range(0,5): 22 #print item[i] 23 ws.write(index,i,item[i])#行,列,数据 24 print(index) 25 index+=1 26 27 newTable="test.xls"#表格名称 28 wb = xlwt.Workbook(encoding='utf-8')#创建excel文件,声明编码 29 ws = wb.add_sheet('sheet1')#创建表格 30 headData = ['招聘职位','公司','地址','薪资','日期']#表头部信息 31 for colnum in range(0, 5): 32 ws.write(0, colnum, headData[colnum], xlwt.easyxf('font: bold on')) # 行,列 33 34 for each in range(1,10): 35 index=(each-1)*50+1 36 excel_write(get(get_content(each)),index) 37 wb.save(newTable)
最后实现的效果如下图:

至此,我们的工作就已经完成了!有的朋友可能想要爬取其他工作的招聘信息,观察了一下URl可以知道修改一下关键字名称就可以了!可以定义成一个函数只需输入关键字,然后就可以自动爬取该工作的招聘信息!条条大路通罗马,想要实现上面的效果肯定不止这一种方法,以上内容仅供参考,希望可以给有需要的朋友提供一点思路!至于代码就比较粗糙了,而本人也希望有一天能够写得一手风骚代码!还是要重申一遍,本人能力有限,文章中可能会有纰漏或者错误,也欢迎表哥表姐们前来指正!谢谢大家!