http:--hive.apache.org/
Hive 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类SQL查询功能。
*使用HQL作为查询接口;
*使用HDFS存储;
*使用MapReduce计算。
hiveql要结合mapReduce来读,会有很多想法
灵活性号,自定义函数,自定义存储格式
groupby#按K来把数据进行分组
orderby#全局排序
join#两个表进行连接
distribute by#把数据打散,按字段把数据分到不同的文件里面
sort by#会把每个reducer上的数据进行排序,局部排序
cluster by#cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。
union all 把多个表进行组合起来形成一个新表
理解hadoop的核心能力,是hive优化的根本
https:--blog.csdn.net/preterhuman_peak/article/details/40649213
长期观察hadoop处理数据的过程,有几个显著的特征:
1.不怕数据多,就怕数据倾斜。
2.对jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次汇总,产生十几个jobs,没半小时是跑不完的。map reduce作业初始化的时间是比较长的。
3.对sum,count来说,不存在数据倾斜问题。
4.对count(distinct ),效率较低,数据量一多,准出问题,如果是多count(distinct )效率更低。
日志内容,统一规范
Schema 模式,约束
Hive
*处理的数据存储在HDFS
*分析数据底层的实现MapReduce
*执行程序运行的Yarn
Select substring(ip,0,4) ip_prex from bg_log;
查看表的建立情况
hive> select * from stat_boss_order_paid_tw where dt="2018-06-27";
CREATE TABLE `stat_boss_order_paid_tw`(
`datavalue` string,
`platform` int,
`pay_type` int,
`actcode` string,
`push_channel` int,
`gateway` int,
`ispaid` int,
`renewals` int,
`autorenew` int,
`bfr` int,
`totalpaidp` int,
`total_income` int,
`totalvodp` int,
`total_vod_income` int,
`totalvipp` int,
`total_vip_income` int,
`totalmonthp` int,
`total_month_income` int,
`totalquarterp` int,
`total_quarter_income` int,
`totalsuccessivequarterp` int,
`total_successive_quarter_income` int,
`totalhalfyearp` int,
`total_halfyear_income` int,
`totalyearp` int,
`total_year_income` int,
`totalsuccessiveyearp` int,
`total_successive_year_income` int,
`otherp` int,
`total_other_income` int)
PARTITIONED BY (
`dt` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.SequenceFileInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat'
LOCATION
'hdfs:--hadoop-bd-ns01/hive/warehouse/hadoopclient_user.db/stat_boss_order_paid_tw'
TBLPROPERTIES (
'transient_lastDdlTime'='1530002639')
Time taken: 0.036 seconds, Fetched: 43 row(s)
察看hdfs文件情况
hive>dfs –du -h hdfs:--hadoop-bd-ns01/hive/warehouse/hadoopclient_user.db/stat_boss_order_paid_tw;
4.4 K 13.1 K hdfs:--hadoop-bd-ns01/hive/warehouse/hadoopclient_user.db/stat_boss_order_paid_tw/dt=2017-11-09
4.8 K 14.3 K hdfs:--hadoop-bd-ns01/hive/warehouse/hadoopclient_user.db/stat_boss_order_paid_tw/dt=2017-11-10
5.3 K 16.0 K hdfs:--hadoop-bd-ns01/hive/warehouse/hadoopclient_user.db/stat_boss_order_paid_tw/dt=2017-11-11
5.0 K 15.0 K hdfs:--hadoop-bd-ns01/hive/warehouse/hadoopclient_user.db/stat_boss_order_paid_tw/dt=2017-11-12
4.7 K 14.1 K hdfs:--hadoop-bd-ns01/hive/warehouse/hadoopclient_user.db/stat_boss_order_paid_tw/dt=2017-11-13
4.8 K 14.5 K hdfs:--hadoop-bd-ns01/hive/warehouse/hadoopclient_user.db/stat_boss_order_paid_tw/dt=2017-11-14
4.6 K 13.9 K hdfs:--hadoop-bd-ns01/hive/warehouse/hadoopclient_user.db/stat_boss_order_paid_tw/dt=2017-11-15
4.6 K 13.7 K hdfs:--hadoop-bd-ns01/hive/warehouse/hadoopclient_user.db/stat_boss_order_paid_tw/dt=2017-11-16
4.6 K 13.9 K hdfs:--hadoop-bd-ns01/hive/warehouse/hadoopclient_user.db/stat_boss_order_paid_tw/dt=2017-11-17
5.3 K 15.8 K hdfs:--hadoop-bd-ns01/hive/warehouse/hadoopclient_user.db/stat_boss_order_paid_tw/dt=2017-11-18
分布式资源队列问题
hive> select count(*) from stat_boss_order_paid_tw where dt="2018-06-27";
这样的语句需要申请分布式资源
每次开客户端CLI set mapred.job.queue.name=de.video;
Job Submission failed with exception 'java.io.IOException(org.apache.hadoop.yarn.exceptions.YarnException: Failed to submit application_1530601329233_1135466 to YARN : User hadoopclient_user cannot submit applications to queue root.default)'
创建表
hive> create table tmg(id int,name string,age int)
> row format delimited --每行为一个记录
> fields terminated by " "; --记录数据段制表符分割
hive>load data local inpath '/home/Hadoop/order.data'into table tmg; --本地路径
hive> load data inpath '/order.data2'into table tmg; --hdfs路径
创建和加载数据可以写在一起 接起来
创建外部表
Hive中的外部表和表很类似,但是其数据不是放在自己表所属的目录中,而是存放到别处,这样的好处是如果你要删除这个外部表,该外部表所指向的数据是不会被删除的,它只会删除外部表对应的元数据;而如果你要删除内部表,该表对应的所有数据包括元数据都会被删除。
hive>create external table torder_ext(id int,name string,money double)
>row format delimited
>fields terminated by ','
>loation '/hive-tmp/order/';
创建外部表
create external table if not exists stock(exchange string,volume int)
row format delimited
fields terminated by ','
location '/data/stocks';
describe extended tablename
管理表 tableType:MANAGED_TABLE
外部表 tableType:EXTERNAL_TABLE
外部表复制表结构,也可以复制管理表的结构
create external table if not exists hdata.employee2
like hdata.employee
location '/data/employee';
查询存储
创建表来存储查询结果
create table tab_ip_ctas
as
select id new_id,name new_name,ip new_ip,country new_country
from tab_ip_ext
sort by new_id;
向临时表中追加中间结果数据
Insert overwrite table tab_ip_like select * from tab_ip
Partition 分区
hive >create table tab_ip_part(id int,name string,price double)
hive > partitioned by(country string)
hive >row foamat delimited
hive>rields terminated by ',';
导数据时起作用
load data local inpath '/home/Hadoop/order.data'into table t_order_part partition(country='China');
load data local inpath '/home/Hadoop/order.data.2'into table t_order_part partition(country='forengn');
select * from t_order_part where country='China'and prince>2400;
已有的表添加分区
Alter table tab_cts add partition(partCol='dt') location '/external/hive/dt';--直接指定数据
show partitions tab_ip_part;
hive> select * from stat_boss_order_paid_tw where dt="2018-06-27";
hive> set hive.mapred.mod=strict; --设置严格模式,如果语句没有分区过滤就不执行
hive> set hive.mapred.mod=nonstrict;
hive> show partitions employee; --查看分区
load data local inpath '${env:HOME}/dis_employee_data'
into table employees
partition(contry='US',state='CA'); --两个分区字段
外部分区表
create external table if not exists log_mesg(
hms int,
server sting)
partitioned by (year int,month int dat int)
row format delimited
fields terminated by ' ';
增加分区
alter table log_mesg add partition(year=2012,month=2,day=1)
location 'hdfs://master_server/data/log_mess/2012/02/01';
可以将前一个月的数据拷贝到s3存储设备
Hadoop distcp /data/logmess/2012/01/02 s3n://ourbucket/logs/2012/01/02
将分区路径指向s3
Alter table log_mess partion(year=2012,month=01,day=02)
set location 's3n://ourbucket/logs/2012/01/02'
删除掉原来分区的数据
Hadoop fs –rmr /data/logmess/2012/01/02
Desc externed log_mess partition(year=2012,month=01,day=02);
输出结果到hdfs
insert overwrite local directory '/home/Hadoop/hivetemp/test.txt' select * from tab_ip_part where part_flag='part1';
insert overwrite directory '/hiveout.txt' select * from tab_ip_part where part_flag='part1';
hadoop fs –cat /hiveout.txt/*
CLUSTER
create table tab_ip_cluster(id int,name string,ip string,country string)
clustered by(id) into 3 buckets;
load data local inpath '/home/hadoop/ip.txt' overwrite into table tab_ip_cluster;
set hive.enforce.bucketing=true;
insert into table tab_ip_cluster select * from tab_ip;
select * from tab_ip_cluster tablesample(bucket 2 out of 3 on id);
表array
hive >create table tab_array(a array<int>,b array<sting>)
hive >row farmat delimited
hive >fields terminated by ' '
hive >collection items terminated by ',';
例如数据 allen,jarry,tom 132,222,123
Fengxiang,jin,kol 122,112,123
hive >select a[0] from tab_array; 第一行
hive >select a from tab_array; a字段全部列出
select * from tab_array where array_contains(b,'word');
insert into table tab_array select array(0),array(name,ip) from tab_ext t;
map
create table tab_map(name string,info map<string,string>)
row format delimited
fields terminated by ' '
collection items terminated by ','
map keys terminated by ':';
示例数据:
marry age:18;height:156;addr:usa
jenny age:20;height:160;addr:Canna;weight:45KG
数据个数可以不一样
load data local inpath '/home/hadoop/hivetemp/tab_map.txt' overwrite into table tab_map;
insert into table tab_map select name,map('name',name,'ip',ip) from tab_ext;
struct
create table tab_struct(name string,info struct<age:int,tel:string,addr:string>)
row format delimited
fields terminated by ' '
collection items terminated by ','
数据个数定好了
load data local inpath '/home/hadoop/hivetemp/tab_st.txt' overwrite into table tab_struct;
insert into table tab_struct select name,named_struct('age',id,'tel',name,'addr',country) from tab_ext;
Udf用户定义函数
Java写类
方法的修饰符必须为public
package cn.itheima.bigdata.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
public class PhoneToAreaUDF extends UDF
{
public static HashMap<String,String> areaMap=new HashMap();
static{
areaMap.put("136","beijing");
areaMap.put("137","tianjin");
areaMap.put("138","nanjing");
areaMap.put("139","shanghai");
areaMap.put("188","haikou");
}
--用来将手机号翻译出城市名
public String evaluate(String phoneNum)
{
areaMap.get(phoneNum.substring(0,3));
return area==null?"huoxing":area;
}
--用来求上下行流量的和
private void evaluate(int up_flow,int d_flow)
{
return up_flow+d_flow;
}
}
打成jar包,传到服务器
hive>add jar /home/hadoop/areaudf.jar;
hive>create temporary function area as 'cn.itheima.bigdata.hive.PhoneToAreaUDF' hive>create table t_flow(phonenum string,up_flow int,d_flow int)
>row format delimited
>fields terminated by ',';
hive>load data local inpath '……';
hive>select phonenum,area(phonenum),area(up_flow,d_flow) from t_flow;
Hive文档深入阅读
变量和属性
hivevar 可读可写 用户自定义变量
hiveconf 可读可写 hive相关配置属性
system 可读可写 java定义的配置属性
env 只可读 shell环境定义的环境变量
hive变量内部是以java字符串方式存储的
set命令可以修改变量
访问系统环境变量,只能读取变量
hive> set env:HOME;
env:HOME=/home/hadoopclient_user
$ hive --define foo=bar
hive> set foo;
foo=bar
hive> set hivevar:foo;
hivevar:foo=bar
hive> set hivevar:foo=bar2;
hive> set foo;
foo=bar2
hive> set hivevar:foo ;
hivevar:foo=bar2
--define key=value 等价于 –hivevar key= value
hive> create table toss(li int,${hivevar:foo} string); hivevar: 域可以省略
hive> desc toss;
li int
bar2 string
Create/Drop/Truncate Table
一次使用命令
$ hive –S –e "select * from mytable limit 3"> /tmp/myquery
$ cat /tmp/myquery
Name1 10
Name2 20
Name3 30
-S静音模式,去掉一些"ok""time taken"等无关信息,输出流写入本地文件系统。
hive> set hive.cli.print.header=true; 可以设置select * from tableName;额外将字段名第一行打印出来
执行shell命令
hive> !/bin/echo "hello world";
"hello world"
hive> ! pwd ;
/usr/local/hive/bin
Hive中使用dfs命令
hive> dfs -ls /;
Found 2 items
drwxrwxr-x - root supergroup 0 2018-07-16 10:00 /tmp
drwxrwxr-x - root supergroup 0 2018-07-14 00:10 /user
数据类型
类型转换,讲一个s sting 转换成int ...cast(s as int)...
|
TINYINT |
1-byte signed integer, from -128 to 127 |
|
SMALLINT |
2-byte signed integer, from -32,768 to 32,767 |
|
INT/INTEGER |
4-byte signed integer, from -2,147,483,648 to 2,147,483,647 |
|
BIGINT |
8-byte signed integer, from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 |
|
FLOAT |
4-byte single precision floating point number |
|
DOUBLE |
8-byte double precision floating point number |
|
DOUBLE |
PRECISION |
|
DECIMAL |
十进制 was introduced in Hive 0.11.0 (HIVE-2693) and revised in Hive 0.13.0 (HIVE-3976) |
|
TIMESTAMP |
整数,浮点数或者字符串Note: Only available starting with Hive 0.8.0+ |
|
DATE |
Note: Only available starting with Hive 0.12.0+ |
|
INTERVAL |
Note: Only available starting with Hive 1.2.0+ |
|
STRING |
字符串文字可以用单引号(')或双引号(")表示 |
|
BINARY |
字节数组 Note: Only available starting with Hive 0.8.0+ |
create table employees(
name string,
salary float,
subordinates array<string>, --下属
deductions map<string,float>, --扣薪纪录
address struct<street:sting,city:sting,state:string,zip:int>) --地址
row format delimited
fields terminated by '�01'
collection items terminated by '�02'
map keys terminated by '�03'
lines terminated by ' '
stored as textfile;
一般 来分割记录
^A(�01) 分割字段
^B(�02) 分割array或者struct
^C(�03) 分割map中的key和value
hiveQL与mysql区别
hive不支持行级插入操作、更新操作和删除操作,hive不支持事务,增加了hadoop下的可以提供更高性能的扩展,以及一些个性化扩展,增加了一些外部程序。
Create/Drop/ Alter Database
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment] --描述信息
[LOCATION hdfs_path] --修改默认位置
[WITH DBPROPERTIES (property_name=property_value, ...)];
hive> show databases like 'h.*';
database_name
hdata
-------------------------------------------------------------------------
hive> desc database hdata;
db_name comment location owner_name owner_type parameters
hdata hdfs:--localhost:9000/user/hive/warehouse/hdata.db root USER
------------------------------------------------------------------------
hive> create database financials
> with dbproperties('creator' = 'Tomy','date'='2018-07-03');
hive> desc database financials;
db_name comment location owner_name owner_type parameters
financials hdfs:--localhost:9000/user/hive/warehouse/financials.db root USER
hive> desc database extended financials;
db_name comment location owner_name owner_type parameters
financials hdfs:--localhost:9000/user/hive/warehouse/financials.db root USER {date=2018-07-03, creator=Tomy}
hive> set hive.cli.print.current.db=true; --显示当前的数据库
hive (financials)>
hive> drop database if exist financials;
默认情况下hive不允许删除一个有表的数据库,应该先删除表在删数据库,否则要用关键字cascade,hive自行删除表再删除database
hive> drop database if exist financials cascade;
修改数据库属性
hive (financials)> alter database financials set dbproperties('edited-by'='joe dba');
Time taken: 0.149 seconds
hive (financials)> desc database extended financials;
db_name comment location owner_name owner_type parameters
financials hdfs:--localhost:9000/user/hive/warehouse/financials.db root USER {date=2018-07-03, edited-by=joe dba, creator=Tomy}
Create Table
create table if not exists default.bf_log_20190714
(
ip string comment 'remote ip address', --字段名,类型,注释
user string,
req_url string comment 'user request url'
)
comment 'web access log' --对表的注释
row format delimited fields terminated by ' ' --列分隔
collection items terminated by ' ' --默认记录回车分割,可以不写
stored as textfile --默认可以不写,存储为文本文件
location '/user/hive/warehouse/'; --默认为hdfs用户目录下
load data local inpath '/opt/datas/bf_log.txt'into table default.bf_log_20190714;
---------------------------------------------------------------------------
create table if not exists default.bf_log_20190714_sa --根据一个查询建表
as select ip,user from default.bf_log_20190714;
------------------------------------------------------------------------------
create table if not exists default.bf_log_20190715
like default.bf_log_20190714; --根据已有的表创建同样结构
===========================================================
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name -- ()
[(col_name data_type [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name,
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format] –分隔
[STORED AS file_format] –默认文本
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] --
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later) --表属性例如'cretor'='Tomy'
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (默认文本, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| JSONFILE -- (Note: Available in Hive 4.0.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE
查询另一个数据库的表
hive (financials)> show tables in hdata;
tab_name
tmg
toss
hive (hdata)> show tables [like] 't.*';
tab_name
tmg
toss
hive (financials)> show tables like 't.*' in hdata; 错误
in和正则表达式不同时使用
hive (financials)> desc extended hdata.toss;
可以显示parameters 属性
使用formatted代替extended得到结果可读性要更强
表自动有两个属性 last_modified_by 和 last_modified_time,并且不会显示在表的详细信息中
自定义表存储格式
Hive 存储格式是文本文件,也可以用 stored as textfile来显示设定
create table employees(
name string,
salary float,
subordinates array<string>, --下属
deductions map<string,float>, --扣薪纪录
address struct<street:sting,city:sting,state:string,zip:int>) --地址
row format delimited
fields terminated by '�01'
collection items terminated by '�02'
map keys terminated by '�03'
lines terminated by ' '
stored as textfile;
存储记录编码是通过inputformat 对象来控制的,hive使用一个名为org.apache.hadoop.mapred.TextInputFormat的java类
将输入流->记录
记录的解析是用Serde 序列化器/反序列化器来控制的,
记录->列
Hive还有一个outputformat的对象来讲查询的输出写入文件中或者控制台记录格式化->输出流
删除表
drop table if exists employees;
外部表,表的元数据信息会删除,数据文件本身不会删除
修改表
重命名
alter table log_mess rename to log_message;
增加、修改和删除分区
alter table log_mess add [if not exists]
partition (year=2011,month=1,day=1) location '/logs/2011/01/01'
partition (year=2011,month=1,day=1) location '/logs/2011/01/02';
可以增加多个分区
移动位置修改分区
alter table log_mess partition(year=2012,month=01,day=02)
set location 's3n://ourbucket/logs/2012/01/02';
该命令不会移走外部表旧数据,也不会删除旧数据
删除分区
alter table log_mess drop if exists partion(year=2012,month=01,day=02);
外部表的数据文件依然不会删除
修改列信息
重命名
alter table log_mess
change [column] hms hours_min_sec int
[comment 'the hours,minutes and seconds']
after severity; --将更改的字段移到severity字段之后,如果要放在第一个位置,用first代替after severity即可
即使字段名和类型只有一个改变,也要都重新指定
增加列
alter table log_mess
add columns(
app_name string comment 'sdfsd'
session_id long comment 'dfsdf'
);
删除/替换列
alter table log_mess replace columns(
hours int
server string
)
Alter 只改变元信息
修改表属性
alter table log_mess set tblproperties(
'note'='aaadfsd');
只能修改或者增加属性,不能删除属性
修改存储属性
alter table log_mess
partition(year=2012, month=01,day=02)
set fileformat sequencefile;
其他修改语句
场景1:当表中存储的文件在hive之外被修改了,就会触发touch钩子的执行
alter table log_mess
touch
partition(year=2012,month=01,day=02);
场景2:如果表或者分区不存在,那么上述语句不会创建表或者分区,那么下述语句会将这个分区内的文件打成hadoop压缩包(HAR)文件
alter table log_mess
archive
partition(year=2012,month=01,day=02);
unchive可以反向操作
alter table log_mess
partition(year=2012,month=01,day=02) enable no_drop;
alter table log_mess
partition(year=2012,month=01,day=02) enable offline;
enable 替换disable可以反向操作
数据操作
向管理表装载数据
load data local inpath '${env:HOME}/dis_employee_data'
overwrite into table employees
partition(contry='US',state='CA'); --两个分区字段
overwrite:如果目录不存在的话,这个命令会先创建分区目录,然后在将数据拷贝到该目录。
如果存在的话,之前的数据会被覆盖。
load data 没有local关键字,只能源文件和目标文件以及目录在同一个文件系统,即不允许从一个集群hdfs转载数据到另一个集群hdfs。
Hdfs 默认为/user/$USER
Hive还会验证文件存储格式是否一致。
通过查询语句向表中插入数据
insert overwrite table employees
partition (country='US',state='OR')
select * from staged_employees se
where se.cnty='US'and se.st='OR';
但是如果staged_employees表非常大,有多个分区,那么就得扫描好多次,如下语句可以解决
from staged_employees se
insert overwrite table employees --或者insert into
partition(country='US',state='OR')
select * where se.cnty='US'and se.st='OR'
insert overwrite table employees
partition(country='US',state='CA')
select * where se.cnty='US'and se.st=' CA'
insert overwrite table employees
partition(country='US',state='IL')
select * where se.cnty='US'and se.st='IL';
动态分区插入
如果要创建非常多的分区,用户就需要写非常多的sql,而动态分区可以基于查询的参数推断出需要创建的分区名称。
insert overwrite table employees
partition (country, state)
select …,se.cnty,se.st from staged_employees se ;
根据最后2列来确定分区字段country和state值。根据位置来匹配。
如果country和state值有100组的话,那么employees将会有100个分区。
用户也可以混合静态和动态分区
insert overwrite table employees
partition (country='US', state)
select …,se.cnty,se.st from staged_employees se
where se.cnty='US' ;
静态分区键必须出现在动态分区键之前
动态分区功能默认未开启,开始后默认是以'严格'模式执行的,在这种模式下要求至少有一列分区字段是静态的。防止用户使用时间戳等来作为分区。
hive .exec.dynamic.partition false 设置成true,表示开启动态分区功能
hive.exec.dynamic.patition.mode strict 设置成nonstrict,允许所有分区都是动态的,否则要求至少有一列分区字段是静态的
创建表存储单个查询语句结果
Create table ca_employee
as
select name,salary,address from employees
where se.state='CA';
导出数据
如果是需要的数据文件
hadoop –fs –cp source_path target_path
否则
insert overwrite local derectory '/tmp/ca_employees'
select name,salary,address from employees se
where se.state='CA';
一个或多个文件会被写入这个文件目录,具体个数由调用的reducer决定
指定目录也可以是url全路径 hdfs://master-server/tmp/ca_employees

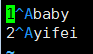
导出多个
from employees se
insert overwrite local direction '/tmp/or_employees'
select name,salary,address where se.cty='US'and se.state='OR';
insert overwrite local direction '/tmp/ca_employees'
select name,salary,address where se.cty='US'and se.state='CA';
insert overwrite local direction '/tmp/il_employees'
select name,salary,address where se.cty='US'and se.state='IL';
查询
**在SELECT子句中出现的字段或属性,同时有聚合函数存在,如果不是在聚合函数中,那就必须要放到GROUP BY子句里面去,反过来,没有出现在GROUP BY子句中的字段或属性,只能在聚合函数中。
create table employees(
name string,
salary float,
subordinates array<string>, --下属
deductions map<string,float>, --扣薪纪录
address struct<street:sting,city:sting,state:string,zip:int>) --地址
partitioned by(country sting,state sting);
select name,subordinates, subordinates[0],deductions,address,deductions["State Taxes"],address.city from employees;
正则表达式来指定列
select symbol,'price.*' from stocks; 有问题
hive> desc tmg;
OK
id int
name string
age int
time string
hive> select id,'na.*' from tmg;
OK
1 na.*
2 na.*
3 na.*
使用列值进行计算
select upper(name),salary,deduction["Federal Taxes"],round(salary*(1- deduction["Federal Taxes"])) from employee;
int和 bigint 计算会提升为bigint
int和float计算会提升为float
注意数据溢出和下溢,参照java数据结构
函数
https://www.cnblogs.com/yejibigdata/p/6380744.html
round(1.3) floor(1.3) ceil/ceiling(1.3) rand() exp(1.1) ln(1.3) log10(1.3) log2(1.3) log(1.2,1.3) pow(1.2,1.3) /power sqrt(1.3) bin(1.3)得到二进制的string类型 hex(20)十六进制string类型 hex('str') hex(binary b) unhex(string i) conv(bigint i,int base,int to_base) 将i从base进制转换为to_base
abs(1.3) pmod(int i,int j)i对j取模,double类型也可以
sin(1.3) 弧度 asin() cos() acos() tan() atan() degrees(1.3) 弧度变角度 radians(1.3)角度变弧度
positive(int i)返回值本身也可以double negative()相反数 sign(1.3) 返回正负号1.0/-1.0 e()自然常数 pi() 圆周率
数学函数见hive编程指南85页
聚合函数注意distinct的使用
hive> set hive.map.aggr=true 提高聚合函数的性能,需要更多的内存
表生成函数
与聚合函数相反
select explode(subordinates) as sub from employees;
使用表生成函数时,必须使用列别名
-
parse_url函数使用案例
parse_url('http://facebook.com/path/p1.php?query=1', 'HOST')返回'facebook.com' ,
parse_url('http://facebook.com/path/p1.php?query=1', 'PATH')返回'/path/p1.php' ,
parse_url('http://facebook.com/path/p1.php?query=1', 'QUERY')返回'query=1',
或,可以指定key来返回特定参数,key的格式是QUERY:,
例如:QUERY:k1
parse_url('http://facebook.com/path/p1.php?query=1#Ref', 'REF')返回'Ref'
parse_url('http://facebook.com/path/p1.php?query=1#Ref', 'PROTOCOL')返回'http'
HIVE直接读入json的函数有两个:
(1)get_json_object(string json_string, string path)
返回值: string
说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。
举例:
hive> select get_json_object('{"store":{"fruit":[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}], "bicycle":{"price":19.95,"color":"red"}}, "email":"amy@only_for_json_udf_test.net", "owner":"amy" } ','$.owner') from dual;
结果:amy
注:如果ower是一个数组 path还可以用$.owner[0] 这样的坐标来获取具体的数据
这个函数每次只能返回一个数据项。
(2)json_tuple(jsonStr, k1, k2, ...)
参数为一组键k1,k2……和JSON字符串,返回值的元组。该方法比 get_json_object 高效,因为可以在一次调用中输入多个键
select a.timestamp, b.*
from log a lateral view json_tuple(a.appevent, 'eventid', 'eventname') b as f1, f2;
处理数据样例:
{"GPS_LAT":39.8965125,"GPS_LONG":116.3493225,"GPS_SPEED":20.9993625,"GPS_STATE":"A","GPS_TIME":"2014-01-02 00:00:16","IMEI":"508597","after_oxygen_sensor":132,"air_condion_state":3,"bdoneNo_after_mileage":0,"bdoneNo_zero_mileage":8044,"db_speed":22,"direction_angle":358.2585,"front_oxygen_sensor":64,"instant_fuel":233,"speed":1210,"torque":33,"total_fuel":0}
处理HIVE语句:
create table 2014jrtest as select json_tuple(line,'GPS_LAT','GPS_LONG','GPS_SPEED','GPS_STATE','GPS_TIME','IMEI','after_oxygen_sensor','air_condion_state','bdoneNo_after_mileage','bdoneNo_zero_mileage','db_speed','direction_angle','front_oxygen_sensor','instant_fuel','speed','torque','total_fuel') from 2014test;
其他内置函数
ascii(strings) ->string 返回字符串首个ascii字符的整数值
base64(binary bin) ->string 将二进制bin转换成给予64位的字符串
binary(string s) -> binary / binary(binary s) -> binary 将字符串转换为二进制
case(<expr> as <type>) 将expr转换为type cast('1',bigint)
concat(binary s1,binary s2,…) 或者string类型,拼接为字符串最终都为sting类型
concat_ws(string sep,binary s1,string s2,...)用在指定分隔符sep将后面的拼接为字符串
hive (hdata)> select concat_ws('+','hello','world');
hello+world
decode(binary bin,string charset) 将二进制解码成字符串 'US-ASCII','IOS-8859-1','UTF-8','UTF-16BE', 'UTF-16LE', 'UTF-16'
encode(string src,string charset) 将字符串src编码成二进制
find_in_set(string s,string commaSeparatedString) 返回在以逗号分隔的字符串中s出现的位置
hive (hdata)> select find_in_set('a','ba,c,a,da,f');
3
format_number(number x,int d)->string x保留d位小数
in
if语句
hive> select if(a=a,'bbbb',111) fromlxw_dual;
bbbb
hive> select if(1<2,100,200) fromlxw_dual;
200
case when then语句
hive>select name,salary,
> case
> when salary<5000.0 then 'low'
> when salary>=5000.0 and salary<7000.0 then 'middle'
> when salary>=7000.0 and salary<10000.0 then 'high'
> else 'very high'
> end as bracket from employees;
避免进行MapReduce
本地模式可以不触发mapreduce
select * from employees
可以简单的读取对应存储目录下的文件,然后输出格式化内容到控制台
对于where语句中过滤条件只是分区字段这种情况也无需MapReduce
select * from employees where country='US'and state='CA'limit 100;
set hive.exec.mode.local.auto=true;尝试使用本地模式执行其他操作
where语句
hive (hdata)> select name, age agggge from tmg where agggge<20;
错误 where语句中不能有别名,改为嵌套查询
hive (hdata)> select e.* from (select name,age agggge from tmg) e
where e.agggge<20;
baby 18
yifei 19
谓词
A<=>B 如果A和B都为NULL,返回true,其他的和= 一致
a<>b, a!=b
a==b 错误语法 而是a=b来判断
a [not ] between b and c 三者任一为NULL,结果为NULLL, a>=b and a<=c
a is NULL
a is not null
a [not] like b b如果为'x%'表示必须以x开头,'%x'表示含有x即可
a rlike b / a regexp b b如果是a的正则表达式则返回true
浮点数注意
0.2转换成float为0.2000001 转换成double为0.200000000001
所以会出现where x>0.2 如果x为float的话,会选出0.2
解决方法1,存储时用double
方法2 where x>cast(0.2 as float)
正则表达式
rlike '.*(Chicago|Ontario).*' .代表任一字符 *重复左边字符0-无数次
like '%Chicago%'
group by
select year(ymd),avg(price_close) from stocks
where exchange='NASDAQ' and symbol='AAPL'
group by year(ymd);
having
允许用户通过一个简单的语法完成对group by的过滤任务
select year(ymd),avg(price_close) from stocks
where exchange='NASDAQ' and symbol='AAPL'
group by year(ymd)
having avg(price_close)>50.0;
不用having的话,需要对选出的表再用where筛选一遍,嵌套
select s2.year,s2.avg from(
select year(ymd) year,avg(price_close) avg from stocks
where exchange='NASDAQ' and symbol='AAPL'
group by year(ymd)) s2
where s2.avg>50.0;
Join语句
inner join
select a.ymd,a.price_close,b.price_close
from stocks a join stocks b on a.ymd =b.ymd
where a.symbol='AAPL'and b.symbol='IBM';
以下语句错误
select a.ymd,a.price_close,b.price_close
from stocks a join stocks b on a.ymd <=b.ymd
where a.symbol='AAPL'and b.symbol='IBM';
pig提供了交叉生产的功能,pig中可以实现
hive不支持on语句中使用or
大多数情况下hive会对每对join连接对象启动一个MapReduce任务
select a.ymd,a.price_close, b.price_close, c.price_close
from strocs a join stocks b on a.ymd = b.ymd
join stocks c on a.ymd =c.ymd
where a.symbol='AAPL'and b.symbol='IBM'and c.symbol='GE';
join优化,因为3张和更多的表连接时,使用同一个连接键,例如本例子中的a.ymd,只会产生一个MapReduce。
Hive同时假定查询中最后一个表是最大的,对每行记录连接后,尝试将其他表缓存起来,然后扫描最后的表进行计算。因此需要保证连续查询中的表的大小从左往右一次增大。
可以标记显式地告诉查询优化器那个表是最大的
select /*streamtable(s)*/ s.ymd,s.symbol,s.price_close,d.dividend
from stocks s join dividends d on s.ymd =d.ymd and s.symbol=d.symbol
where s.symbol='AAPL';
还有一个类似的优化map-side join
left outer join
左边中符合where的记录都会保留,右边没有符合on后面的连接条件的记录值会是null
select s.ymd,s.symbol,s.price_close,d.dividend
from stocks s left outer join dividends d on s.ymd =d.ymd and s.symbol=d.symbol
where s.symbol='AAPL';
outer join
where字句中增加分区过滤器可以加快查询速度,对exchange字段增加谓词限定
select s.ymd,s.symbol,s.price_close,d.dividend
from stocks s left outer join dividends d on s.ymd=d.ymd and s.symbol=d.symbol
where s.symbol='AAPL'
and s.exchange='NASDAQ'and d.exchange='NASDAQ';
但是这个结果和内连接一样,实际是先执行join语句,然后where过滤,此时d.exchange字段大多数为NULL,因此过滤掉了这些。
解决方法是去掉d.exchange
select s.ymd,s.symbol,s.price_close,d.dividend
from stocks s left outer join dividends d on s.ymd=d.ymd and s.symbol=d.symbol
where s.symbol='AAPL' and s.exchange='NASDAQ';
如果将where中的条件放在on语句中,可以工作,但是外链接会忽略分区过滤条件。不过内连接可以的
幸运的是,有一种适合所有种类连接的解决方案,嵌套select
select s.ymd,s.symbol,s.price_close,d.dividend
from
(select * from stocks where symbol='AAPL' and exchange='NASDAQ') s
left outer join
(select * from dividend where symbol='AAPL' and exchange='NASDAQ') d
on s.ymd=d.ymd;
right outer join 类似
full outer join
完全外连接
任一表中没有对应记录则null
Left-semi-join
首先满足on语句的连接条件,返回左边表的记录
不支持以下语句
select s.ymd,s.symbol,s.price_close from stocks s
where s.ymd,s.symbol in
(
select d.ymd,d.symboo from dividends d
);
可以用如下语句来达到同样目的
select s.ymd,s.symbol,s.price_close from stocks s
left semi join dividends d on s.ymd=d.ymd and s.symbol=d.symbol;
注意:select和where语句不能引用到右边表的字段。
不支持right-semi-join
半连接比内连接高效,对于左边表一条指定的记录,在右边表一旦找到匹配的记录,hive就会停止扫描。
笛卡尔乘积join
select * from stocks join dividends;
左边5行数据右边6行数据,结果30行数据
select * from stocks join dividends
where stock.symbol=dividends.symbol and stock.symbol='AAPL';
先进行笛卡尔乘积的运算,再进行where筛选,不过消耗很长时间。如果hive.mapred.mode设为true时,hive会阻止执行笛卡尔乘积。
map-side join
如果所有表只有一张是小表,那么可以在最大的表通过mapper时将小表完全放倒内存中。Hive可以在map端执行连接过程(称为map-side join过程),因而hive可以和内存中的小表进行逐一匹配,从而省略了常规连接操作所需要的reduce过程。
dividends表很小
select /*mapjoin(d)*/ s.ymd,s.symbol,s.price_close,d.dividend
from stocks s join dividends d on s.ymd=d.ymd and s.symbol=d.symbol
where s.symbol='AAPL';
如果不加mapjoin这个标记,用户可以设置属性hive.auto.convert.JOIN=true,来触发优化
属性可以设置在$HOME/.hiverc中
用户也可以配置能够使用的小表的大小 hive.mapjoin.smalltalbe.filesize=25000000
但是右外连接和圈外链接不支持这个优化
如果表中数据是分桶的,对于大表,特定情况下可以用这个优化。表中数据必须根据on语句中的键进行分桶,其中一张表的分桶个数必须为另一张表分桶个数的若干倍,因此hive可以再map阶段按照分桶数据进行连接。这种情况下不需要先获取表中所有内容才去和另一张表中每个分桶进行匹配连接。
这个优化默认没有开启, set hive.optimize.bucketmapJOIN=true;
如果涉及的分桶表都具有相同的分桶数,而且数据是按照连接键或桶的键进行排序的,hive可以执行一个更快的分类-合并sort-merge JOIN,如下设置
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
set hive.optimize.bucketmapjoin=true;
set hive.optimize.bucketmapjoin.sortedmerge =true;
order by 和 sort by
order by会对查询结果集执行一个全局排序。也就是会有一个所有的数据都通过一个reducer进行处理的过程,对于大数据集这个过程可能会消耗太过漫长的时间来执行。
而sort by,只会在每个reducer中对数据进行排序,也就是执行一个局部排序过程。这个可以保证每个reducer的输出数据都是有序的(但是并非全局有序),这样可以提高后面的全局排序的效率。
select s.ymd, s.symbol, s.price_close
from stocks s
order by s.ymd asc, s.symbol desc;
select s.ymd, s.symbol, s.price_close
from stocks s
sort by s.ymd asc, s.symbol desc;
含有sort by的distribute by
distribute by控制map的输出在reducer中是如何划分的,MapReduce job中传输的所有数据都是按照键值对的方式进行组织的,因此hive在将用户的查询语句转换成MapReduce job时必须在内部使用这个功能。
默认情况下,MapReduce会根据map输入的键计算相应的hash值,然后均匀分发到多个reducer。而这样就会在sort by时,不同的reducer输出的内容会有明显的重叠。
比如股票,希望具有相同股票交易码的数据在一起处理,我们可以使用distribute by来保证相同股票交易码的数据会分发到同一个reducer中去。
select s.ymd,s.symbol,s.price_close from stocks s
distribute by s.symbol
sort by s.symbol asc ,s.ymd asc;
group by 和 distribute by在控制着reducer接收数据记录方面类似,但是distribute by 要写在group by之前。
Cluster by
在上面的例子中,s.symbol 用在了distribute语句中,也用在了sort by语句中,如果这两个语句涉及到的列完全相同,并且采用的是升序过程(默认排序),那么cluster by就等价于这两个子句,
select s.ymd,s.symbol,s.price_close from stocks s
cluster by s.symbol;
distribute by …sort by 或者cluster by会剥夺sort by的并行性,然而这样可以实现输出文件的数据是全局排序的。
类型转换
Salary是string类型
select name,salary from employees
where cast(salary as float)<100000.0;
如果salary字段不合法,则返回NULL,但是浮点数转换成整数推荐round()或者floor()
类型转换binary值
Binary类型只支持转换为string类型,如果不确定其是否为数值,可以嵌套使用
b字段是binary类型
select (2.0*cast(cast(b as string) as double)) from src;
抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive可以通过对表进行分桶抽样来满足这个需求。
假设numbers 表只有number字段,其值为1~10,我们可以使用rand()函数进行抽样,这个函数会返回一个随机值,前两个查询都返回了两个不相等的值,而第三个查询语句无返回结果:
hive (hdata)> select * from tmg tablesample(bucket 2 out of 3 on rand()) s;
第一遍有输出
第二遍有输出
第三遍无输出
如果我们按照指定列而非rand()函数进行分桶的话,同一语句执行多次返回结果相同。
hive (hdata)> select * from tmg tablesample(bucket 2 out of 3 on age) s;
分桶语句中分母表示是数据将会被分散的桶个数,而分子表示将会选择的桶个数。
Hive 桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
数据块抽样
hive> select * from tmg tablesample(50 percent) s;
3个数据选出了2个
分桶的输入裁剪
select * from numbersflat where number % 2=0;
大多数表是这样的,但是如果tablesample语句指定的列和clustered by 语句中指定的列相同,那么tablesample查询就只会扫描涉及到的表的hash分区数据
create table number_bucketed(number int) clustered by(number) into 3 buckets;
set hive.enforce.bucketing=true;
insert overwrite table number_bucketed select number form numbers;
会有三个数据桶,下面语句查询可以高效地仅仅对其中一个数据桶进行抽样。
hive>select * from number_bucketed tablesample(bucket 2 out of 3 on number) s;
union all
可以将2个或多个表进行合并,每个union子查询都必须有相同的列,而且对应的每个字段的类型必须一致。例如,如果第二个字段是float类型,难么其他子查询的第二个字段必须是float类型。
select log.ymd,log.level,log.message
from(
select l1.ymd.l1.level,l1.message,'Log1' as source
from log1 l1
union all
select l2.ymd.l2.level,l2.message,'Log2' as source
from log2 l2
)log
sort by log.ymd asc;
union也可以对同一个源表的数据合并。便于将长的复杂where语句分割成2个或多个union子查询,不过除非源表建立了索引,否则,这个查询将会对同一份源数据进行多次的拷贝分发。
hive> select * from(
> select * from tmg where age<19
> union all
> select * from tmg where age>19) mg;
from(
from src select src.key,src.value where src.key<100
union all
from src select src.* where src.key>110
)unioninput
insert overwrite directory '/tmp/union.out' select unioninput.*;
视图
使用视图来降低查询复杂度,类似编程语言中使用的函数或者软件设计中的分层设计概念。
如下具有嵌套子查询的查询
from(
select * from people join cart
on(cart.people_id = people.id) where firstname='join'
)a select a.lastname where a.id=3;
因此可以创建一个视图
create view shorter_join as
select * from people join cart
on(cart.people_id = people.id) where firstname='join';
select lastname from shorter_join where id=3;
动态分区视图和map
create external table dynamictable(cols map<string,string>)
row format delimited
fields terminated by '�04'
collection items terminated by '�01'
map keys terminated by '�02'
stored as textfile;
视图1
create view orders(state, city, part) as
select cols["state"], cols["city"], cols["part"]
from dynamictable
where cols["type"]="request";
视图2
create view shipments(time, part) as
select cols["time"], cols["part"]
from dynamictable
where cols["type"]="request";
实际在优化方面,查询语句和视图语句可能会合并成一条单一的实际查询语句,但是这个概念视图仍然适用于视图和使用这个视图的查询语言都包含一个order by 或者一个limit字句的情况。
例如视图语句中有limit 100,用到视图的查询语句包含limit 200,则实际结果有100条记录。
如果 视图用到的列不存在,则失败。
create view if not exist shipments(time, part)
comment 'sfasdfsadfasdf'
tabproperties('creator'='me')
as
select cols["time"], cols["part"]
from dynamictable
where cols["type"]="request";
create table shipments2 like shipments; --复制视图
也可以加external 和location字句
删除视图 drop view if exists shipments;
查看视图 show tables; 没有show views
describe describe extended 来查看视图信息, table type会显示'virtual_view'
视图只能修改元数据中的tblproperties属性
alter view shipments set tblproperties('create_at'='some_timestamp');
模式设计
按天划分的表
应该分区,按天
partitioned by(day int);
alter table supply add partition(day=20110102);
但是在分区上,hdfs所能管理的文件总数有上限。但是MapR和Amazon S3文件系统没有限制。
MapReduce会将一个任务(job)转换为多个任务(task),默认情况下每个task都是一个新的jvm实例,都需要开启和销毁。对于小文件,每个文件都会对应于一个task。在一些情况jvm开启和销毁中销毁可能会比实际处理数据的时间销号要长。
所以,实际中应该是的每个目录下的文件足够大,应该是文件系统中块大小的若干倍。
可以找合适的时间粒度或者二级分区比如 再按照州来分区
可以考虑分桶表数据存储。
唯一键和标准化
Hive没有主键或者给予序列自增键的概念。尽量避免非标准化的数据进行join操作。
非标准化的数据允许被扫描或者写到大的、连续的磁盘存储区域,从而优化磁盘驱动器的I/O性能,然而,非标准化数据可能导致数据重复,而且有更大的导致数据不一致的风险。
create table employees(
name string,
salary float,
subordinates array<string>, --下属
deductions map<string,float>, --扣薪纪录
address struct<street:sting,city:sting,state:string,zip:int>); --地址
这个例子数据模型从很多方面打破了传统的设计原则。
首先,我们非正式的使用了name作为主键,但是name往往是不唯一的。一个关系模型中如果使用name作为主键,那么从一个员工记录到经理记录应该有唯一的一个外键关系。这里我们用另一种方式来表达这个关系,在subordinates数组中保存了该员工所有下属的名字。
其次,每名员工来说,各项税收扣除都是不同的,但是map的键都是一样的,员工表和税收扣除项之间是一对多的关系。
最后,有些雇员可能住在同一个地址,每个员工都有一个住址,而不是单独一个住址表。
同一份数据多种处理
如下两个操作
insert overwrite table sales
select * from history where action='purchased';
insert overwrite table credits
select * from history where action='returned';
如下改造可以扫描一次history表
from history
insert overwrite sales select * from history where action='purchased'
insert overwrite table credits select * where action='returned';
对于每个表的分区
中间表可以防止出错重跑
hive –hiveconf dt=2011-01-01
insert overwrite table distinct_ip_in_logs
select distinct(ip) as ip from weblogs
where hit_date='${hiveconf:dt}';
create table state_city_for_day (state string,city string);
insert overwrite state_city_for_day
select distinct(state,city) from distinct_ip_in_logs
join geodata on (distinct_ip_in_logs.ip=geodata.ip);
这种方法是有效的,不过当计算某一天的数据时会导致前一天的数据被insert overwrite覆盖掉。而且如果同时运行这两个实例,用于处理不同日期的数据会相互影响到对方的数据。
一个更具鲁棒性的方法是在整个过程中使用分区。这样就不会存在同步问题,同时还能带来一个好处,就是可以允许用户对中间数据按日期进行比较。
hive –hiveconf dt=2011-01-01
insert overwrite table distinct_ip_in_logs
partition(hit_date=${dt})
select distinct(ip) as ip from weblogs
where hit_date='${hiveconf:dt}';
create table state_city_for_day (state string, city string)
partitioned by(hit_date string);
insert overwrite state_city_for_day partition(${hiveconf:dt})
select distinct(state, city) from distinct_ip_in_logs
join geodata on (distinct_ip_in_logs.ip=geodata.ip)
where (hit_date='${hiveconf:dt}');
这种做法有一个缺点,用户需要管理中间表并删除旧分区,不过也很容易实现自动化。
分桶表数据存储
分区提供了一个格力数据和优化查询的便利的方式。但是,并非所有的数据集都可以形成合理的分区,况且还有要划分合适大小的问题存在。
分桶是将数据集分解成更容易管理的若干部分的另一个技术。
例如,假设有个表的一级分区是dt,代表日期,二级分区是user_id,那么这种方式会形成太多的小分区。如果用户使用动态分区来创建这些分区的话,那么默认情况下,hive会限制动态分区可以创建的最大分区数,用来避免创建太多的分区导致超过了分布式文件系统的处理能力。所以有user_id来分区语句可能失败。
不过我们对weblog进行分桶,并使用user_id字段作为分桶字段,则字段值会根据用户指定的值进行哈希分发到桶中,同一个user_id下的记录会存储到同一个桶内。假设用户数比桶数多得多,那么每个桶内就会有多个用户记录。
create table weblog(user_id int,url string,source_ip string)
partitioned by(dt string)
clustered by (user_id) into 96 buckets;
set hive.enforce.bucketing=true; 强制hive为目标表的分桶初始化过程设置一个正确的reducer数量
from raw_logs
insert overwrite table weblog
patition(dt='2009-02-21')
select user_id,url,souce_ip where dt=' 2009-02-21';
如果我们没有设置hive.enforce.bucketing属性,就需要自己设置与分桶个数相适应的reducer个数,例如set mapred.reduce.tasks=96,然后在insert 语句中需要在select后增加cluster by语句。
分桶同时有利于高效的map-side join。
为表增加列
create table weblogs(version long, url string)
partitioned by(hit_date int)
row format delimited
fields terminated by ' ';
load data local inpath 'log1.txt' into weblogs partition(20110101);
select * from weblogs;
1 /toys 20110101
alter table weblogs add culumns(user id string);
load data local inpath 'log2.txt' into weblogs partition(20110102);
1 /mystuff 20110101 NULL
1 /toys 20110101 NULL
1 /cars 20110101 bob
1 /stuff 20110101 terry
这种方式无法在已有的字段的开始或者中间增加新字段
使用列存储表
Hive通常使用行式存储,不过也提供了一个列式SerDe来混合列式存储信息。
重复数据
假设有足够多的行,像state字段和age字段这样的列将会有很多重复的数据。这样的数据如果使用列式存储会非常好。
多列
如果一个表有非常多的字段。查询通常会使用到一个字段或者很少的一组字段,列式存储会使分析表数据执行更快。
调优
使用explain
hive (hdata)> select sum(age) from tmg;
hive (hdata)> explain select sum(age) from tmg;
Explain
STAGE DEPENDENCIES:
Stage-1 is a root stage --stage-1包含了这个job的大部分处理过程,而且会触发一个MapReducejob
Stage-0 depends on stages: Stage-1
TablesScan以这个表为输入,然后会产生一个只有字段number的输出。
Group By Operator会应用到sum(number),然后会产生一个输出字段_col0(临时结果按照规则起的字段名)。这些都是发生在job的map过程。
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: tmg
Statistics: Num rows: 8 Data size: 35 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: age (type: int)
outputColumnNames: age
Statistics: Num rows: 8 Data size: 35 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: sum(age)
mode: hash
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
sort order:
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
value expressions: _col0 (type: bigint)
Reduce Operator Tree:
Group By Operator
aggregations: sum(VALUE._col0)
mode: mergepartial
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1 --这个job没有limit语句
Processor Tree:
ListSink
使用explain extended
会多出一些文件路径
限制调整
Limit语句是需要执行整个查询语句,然后返回结果的,比较浪费,hive有一个属性可以开启,当使用limit时可以对源数据进行抽样。
Hive.limit.optimize.enable的值为true,那么还会有两个参数可以控制这个操作,hive.limit.row.max.size 和hive.limit.optimize.limit.file 可以设数值
但是这个有个问题是,可能输入的有用的数据永远不可能被处理到。重要的是理解。
Join优化
map-side join 优化
一个表足够小,完全载入内存,hive可以执行一个map-side join, 减少reduce过程,有时可以减少某些map task任务。
本地模式
有时hive的输入数据量很小,大多数情况下,hive可以通过本地模式在单台计算机上处理所有任务。
set oldjobtracker=${hiveconf:mapred.job.tracker};
set mapred.job.tracker=local;
set mapred.tmp.dir=/home/edward/tmp;
select * from people where firstname=bob;
...
Set mapred.job.tracker=${ oldjobtracker };
用户可以设置hive.exec.mode.local.auto=true 来让hive在适当的时候自动启动这个优化。用户也可以永久写在$HOME/.hiverc中
见P141
并行执行
Hive会将一个查询转化成一个或多个阶段,可以使MapReduce阶段、抽样阶段、合并阶段、limit阶段或者其他阶段。默认情况下,hive一次只执行一个阶段,但是有些阶段可能并非完全相互依赖,可以并行。
严格模式
hive.mapred.mode=strict 可以禁止3中类型的查询
-
分区表,除非where有分区字段过滤条件,否则不允许执行
-
对于使用了order by语句的限制,必须使用limit语句。排序过程将所有数据的结果发到同一个reducer中进行处理,强制limit可以防止reducer额外执行很长时间。
-
限制笛卡尔积的查询。必须有on。
调整mapper和reducer的个数
确定最佳的mapper和reducer个数,并行性。
Hive是按照输入的数据量大小来确定reducer个数的。我们可以通过dfs –count来计算输入量大小,类似Linux的du –s命令,可以计算指定目录下所有数据的总大小。
$hadoop dfs –count /user/media6/fracture/ins/* | tail -4
Hive.exec.reducers.bytes.per.reducer 默认值为1GB,如果调整为750MB,reducer数目就会增多为4个。
Hive默认reducer个数为3,通过设置属性 mapred.reduce.tasks 不同来确定reducer数量对时间的影响。
当在共享集群中处理大任务时,控制资源利用情况,hive.exec.reducers.max 非常重要,一个hadoop集群可以提供的map和reducer资源个数称为插槽是固定的。通过hive.exec.reducers.max属性设置可以阻止某个查询消耗过多的reducer资源,可以配置到$HIVE_HOME/conf/hive-site.xml
(集群总Reduce插槽个数*1.5)/(执行中的查询平均个数)