貌似 Pig 的安装/使用 相对于 hadoop 简单多了..
1. 官网下载: http://pig.apache.org/releases.html
我下载的是 .tar 包, 直接解压就ok了:
tar -zxvf pig-x.x.x
环境变量: /etc/profile ,只要设置 JAVA_HOME 和 HADOOP_HOME 就够了,namenode 和 job 会自动寻找. 到此就结束安装了.
export JAVA_HOME=/usr/java/jdk1.6.0_33 export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=/usr/local/hadoop-0.20.205.0 export PATH=$PATH:$HADOOP_HOME/bin
2. 运行:
首先启动hadoop,然后直接运行: bin/pig , pig会自动连接hadoop. 成功之后,将会进入到一个 grunt 命令行.

3. 第一个简单的例子(提取出日志里的ip地址):
需要分析的日志元数据:
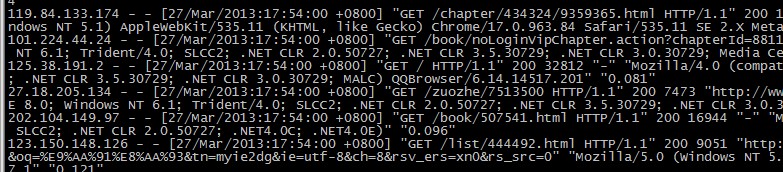
ip 和后面的信息中间是以 空格 分开的... 所以只要把日志行按照空格切分,第一个就是ip了.
代码:
ips = load 'www.17k.com.log' using PigStorage(' ') as (ip:chararray); //加载hdfs里的 www.17k.com.log 日志文件,利用 空格 切分日志.只保存 ip一个字段,以字符串的形式保存
dump ips; //在控制台输出 ip 列表
结果:

ok,到此就大功告成了...