1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
(1)启动hadoop
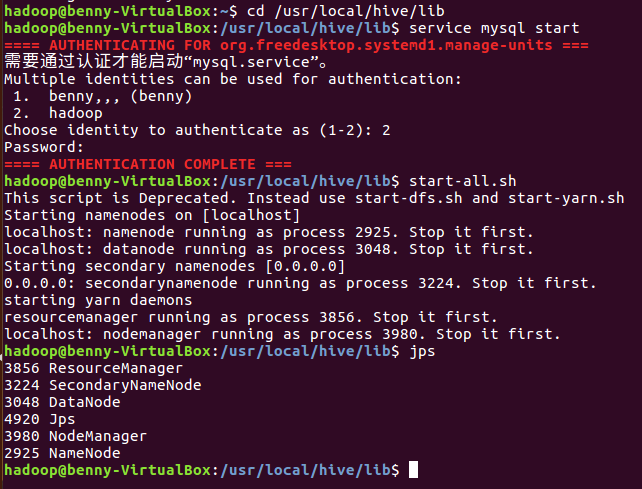
ssh localhost cd /usr/local/hive/lib service mysql start start-all.sh
(2)Hdfs上创建文件夹
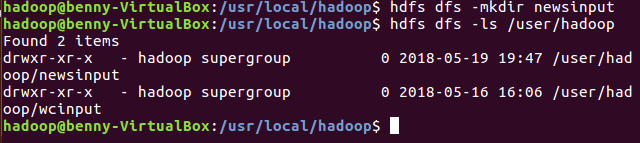
hdfs dfs -mkdir newsinput
hdfs dfs -ls /user/hadoop
(3)上传文件至hdfs
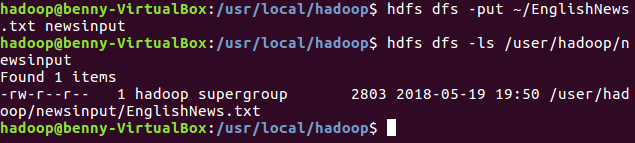
hdfs dfs -put ~/EnglishNews.txt newsinput
hdfs dfs -ls /user/hadoop/newsinput
(4)启动Hive,创建原始文档表

create table news(line string);
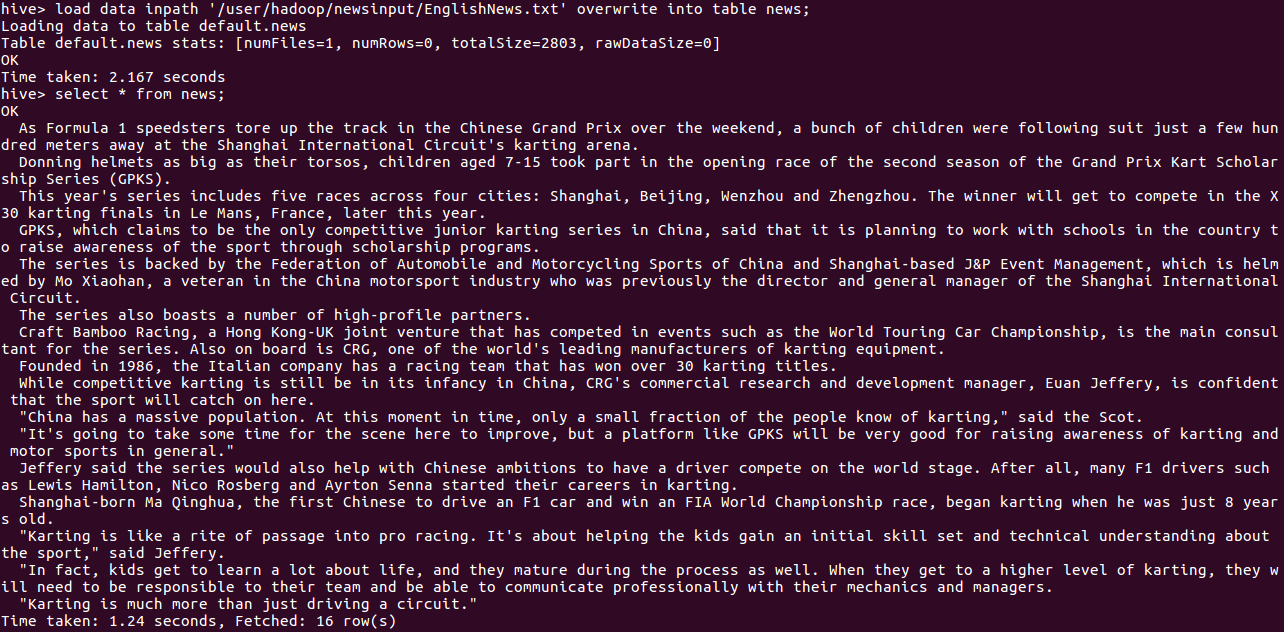
(5)导入文件内容到表docs并查看
load data inpath '/user/hadoop/newsinput/EnglishNews.txt' overwrite into table news;
(6)用HQL进行词频统计,结果放在表word_count里
create table word_count as select word,count(1) as count from (select explode (split(line,' ')) as word from news) word group by word order by word;
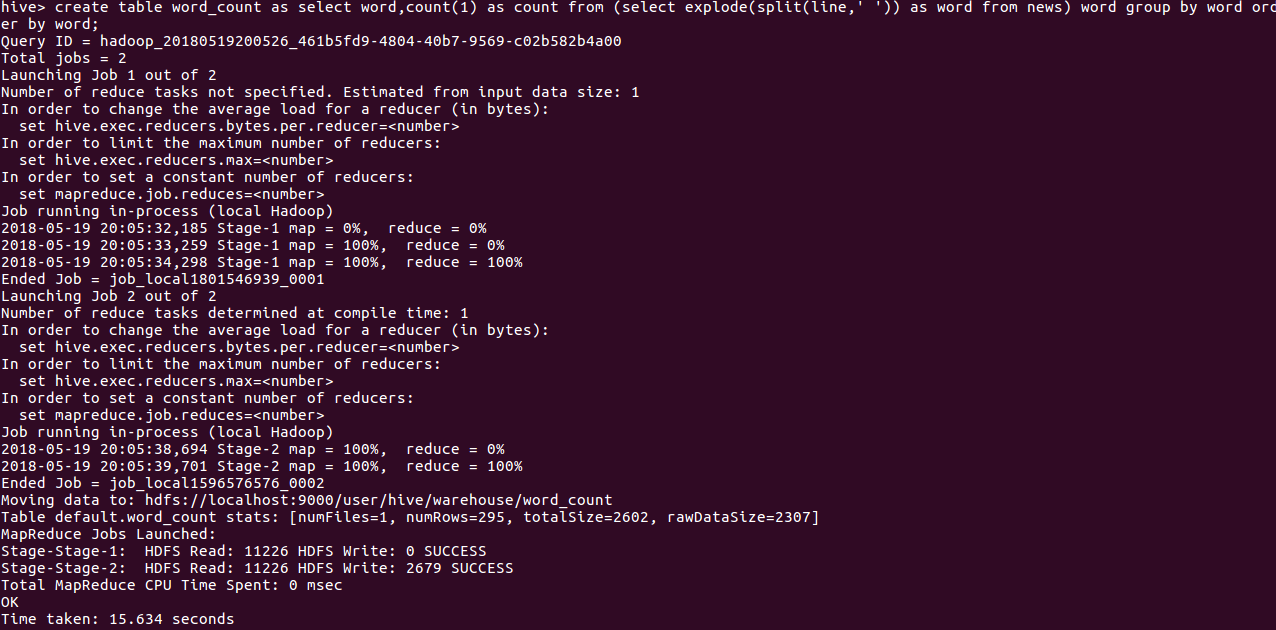
(7)查看统计结果
show tables;

2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
(1) 将爬虫大数据得到的结果导入到Ubuntu
ssh localhost cd /home/hadoop/下载 ls cd /usr/local sudo mkdir bigdatacase sudo chown -R hadoop:hadoop ./bigdatacase cd bigdatacase mkdir dataset ls
ls dataset
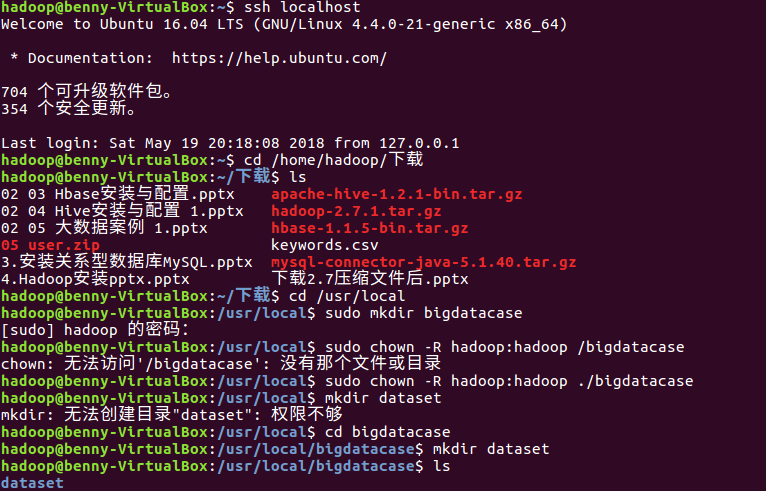
将下载好的数据移动到 /usr/local/bigdatacase/dataset 文件夹里

(2) 在本地查看数据集
cd /usr/local/bigdatacase/dataset
head -15 keywords.csv
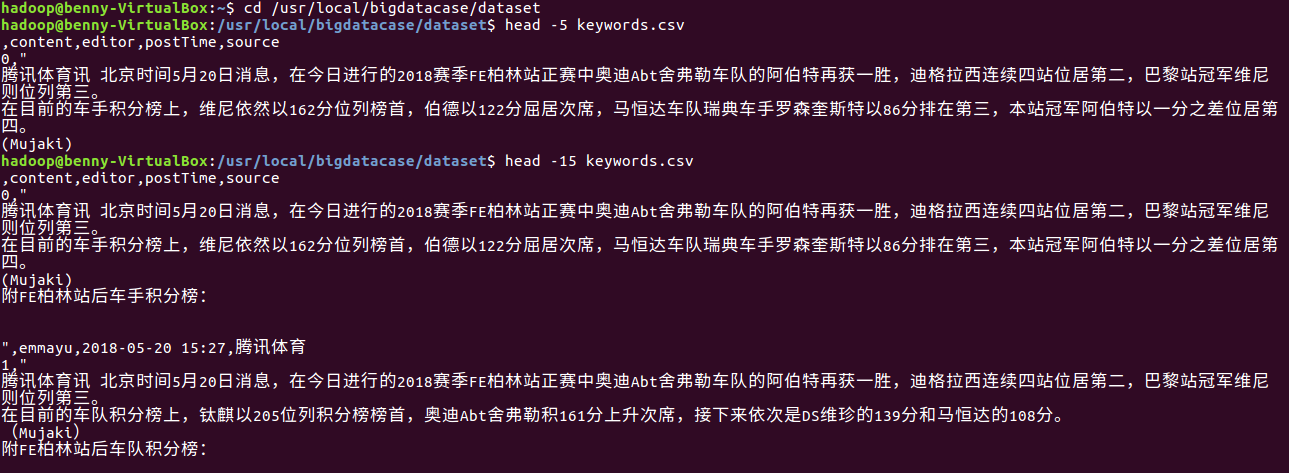
(3) 数据集的预处理
1)删除第一行记录,即字段名称
sed -i '1d' keywords.csv
head -15 keywords.csv
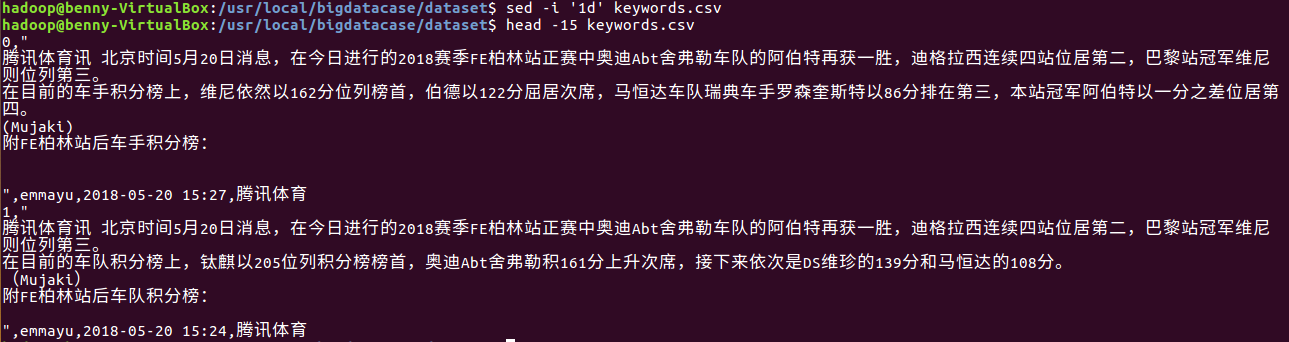
2)对字段进行预处理
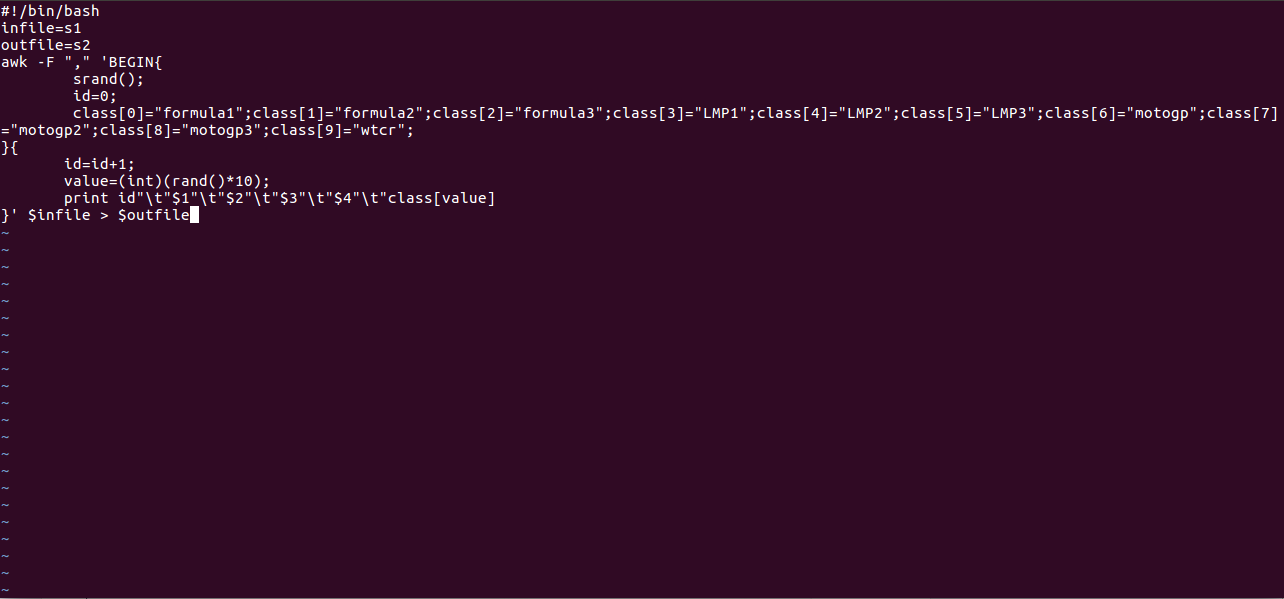

3)查看生成的news.txt
bash ./pre_deal.sh keywords.csv news.txt
head news.txt

(4) 把news.txt中的数据导入到HDFS中
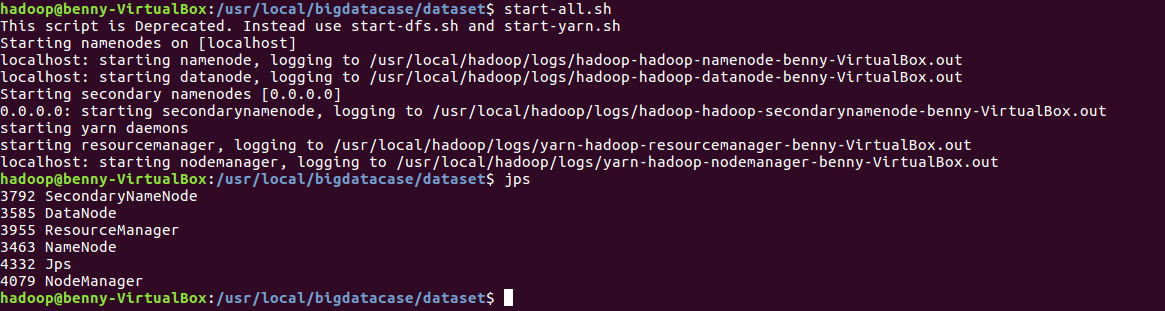
1)启动HDFS
start-all.sh
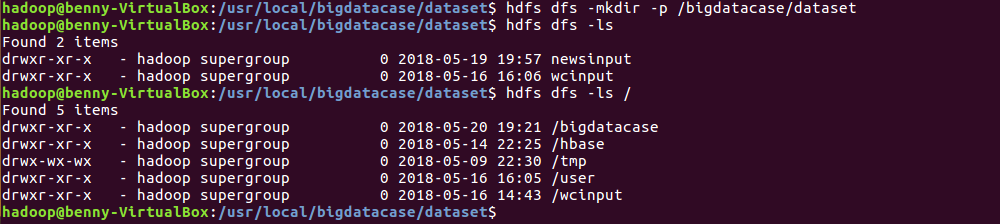
2)在HDFS上建立bigdatacase/dataset文件夹
hdfs dfs -mkdir -p /bigdatacase/dataset hdfs dfs -ls hdfs dfs -ls /
3) 把news.txt上传到HDFS中
hdfs dfs -put ./news.txt /bigdatacase/dataset

4)查看HDFS中的news.txt的前10条记录
hdfs dfs -cat /bigdatacase/dataset/news.txt | head -10

(5)把HDFS中的数据最终导入到数据仓库Hive中
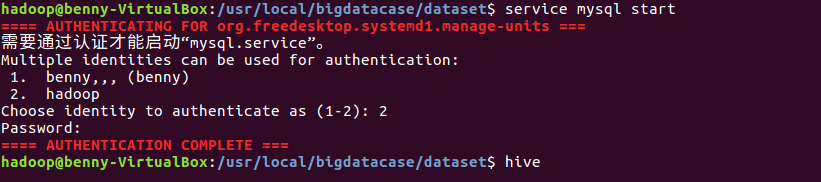
1)启动Mysql数据库及Hive
service mysql start
hive
2) 在hive中创建数据库dblab,创建外部表并查看
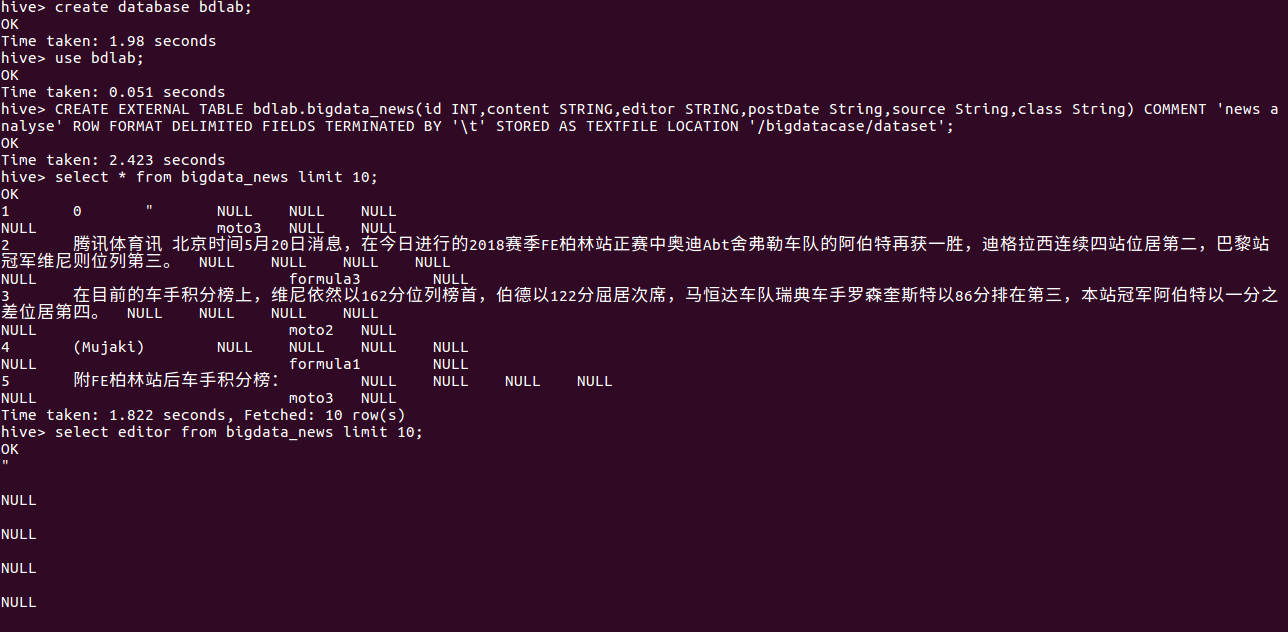
create database bdlab; CREATE EXTERNAL TABLE bdlab.bigdata_news(id INT,content STRING,editor STRING postDate STRING source STRING,class STRING) COMMENT 'news analyse' ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/bigdatacase/dataset'; select editor from bigdata_news limit 10;
(6)对数据进行分析
由于我爬的是新闻类的网站,所以我想看一下一共有多少个人担任过责任编辑
select count(distinct editor) from bigdata_news;
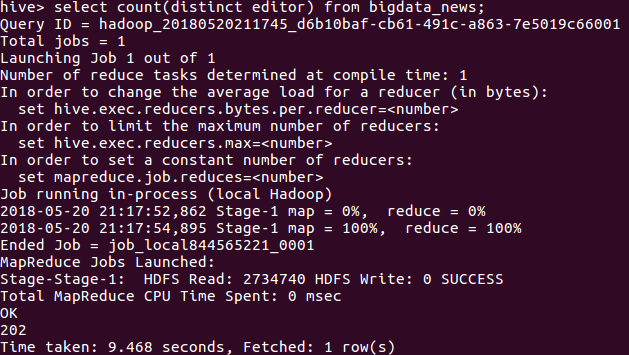
由此可以看出,一共有202个人担任过责任编辑.
(7) 总结
由于我爬的是腾讯赛车频道,是一个新闻类的网站,可以用来分析的数据并不多,所以只分析了下有多少个人担任过责任编辑。
通过这个大作业,我对如何进行大数据分析有一定的了解,对使用hadoop,hive等有一定的了解。