KMP算法
基本概念
1、s[ ]是模式串,即比较长的字符串(要去匹配上的字符串)。
2、p[ ]是模板串,即比较短的字符串。(用来去匹配的字符串)
3、“非平凡前缀”:指除了最后一个字符以外,一个字符串的全部头部组合(前面连续的部分)。
4、“非平凡后缀”:指除了第一个字符以外,一个字符串的全部尾部组合。(后面会有例子,均简称为前/后缀)
注意:KMP算法中前后缀指的都是非平凡,即不包括整个串。
5、“部分匹配值”:前缀和后缀的最长共有元素的长度。
6、next[ ]是“部分匹配值表”,即next数组,它存储的是每一个下标对应的“部分匹配值”,是KMP算法的核心。(后面作详细讲解)
next数组的含义、手动模拟及求解
用p[x,y]来表示p串中位置起于x位置,终于y位置的子串。
对于任意一个j,且j小于等于p串的长度
有这么一个定义,next[j]表示的是p[1,j]子串中前缀和后缀相同的最大子串的长度。
为了算法的方便,KMP算法中字符串p的下标从1开始
按照定义,对于位置j,有这么一个性质,p[1,next[j]]=p[j-next[j]+1,j](即前缀等于后缀)
比如,abaaba,我们可以对它进行手动模拟
手动模拟
| p | a | b | a | a | b |
|---|---|---|---|---|---|
| 下标 | 1 | 2 | 3 | 4 | 5 |
| nextp[下标+1] | 0 | 0 | 1 | 1 | 2 |
对于next[1]来说,p串下标1前是没有任何元素的
| 子串 | a |
|---|---|
| 非平凡前缀 | (empty) |
| 非平凡后缀 | (empty) |
| next[1] | 0 |
对于next[2]来说,
| 子串 | ab |
|---|---|
| 非平凡前缀 | {a} |
| 非平凡后缀 | {b} |
| next[2] | 0 |
对于next[3]来说,
| 子串 | aba |
|---|---|
| 非平凡前缀 | {a,ab} |
| 非平凡后缀 | {a,ba} |
| next[3] | 1 |
对于next[4]来说,
| 子串 | abaa |
|---|---|
| 非平凡前缀 | {a,ab,aba} |
| 非平凡后缀 | {b,ba,baa} |
| next[4] | 1 |
对于next[5]来说,
| 子串 | abaab |
|---|---|
| 非平凡前缀 | {a,ab,aba,abaa} |
| 非平凡后缀 | {b,ab,aab,baab} |
| next[5] | 2 |
经过手动的模拟,我们有了大概的对KMP算法next数组的求解规律的感觉。
next数组的求解
-
有模式串去生成next数组
-
在已经知道next[j]的前提下,尝试去求next[j+1],可以发现next[j+1]<=next[j]+1.
-
由于求的是非平凡前后缀,所以KMP算法的求next数组的起始位置要从2开始。
-
由于是求一个前缀和一个后缀,故而,需要两个指针来完成任务。(一个用来确定前缀,一个用来确定后缀)。
-
因为p[1,next[j]]=p[j-next[j]+1,j],设前子串为a,后子串为b,由于前后子串相等,且a子串内部也有对应的next[ a.length() ] ,且它会和b子串对应上。
-
这个性质在KMP快速匹配的时候非常有用(可以看成前缀和后缀各自裂开,最终形成了四个相同部分),比如说这一句(i代表新加入来的点,而j代表的是原来为加入i这个点时的串p[1,i-1]的next[i-1])。
while(j&&p[i]!=p[j+1])j=next[j];大致流程





代码理解,如果有必要的话就做一个裂开处理,然后裂开完后,再做进一步的确认
for(int i = 2, j = 0; i <= m; i++)
{
while(j && p[i] != p[j+1]) j = next[j];
if(p[i] == p[j+1]) j++;
next[i] = j;
}
处理好产生于较小长度的p串的next数组后,就可以拿着这个next数组再s串中进行匹配。
匹配
这里也是需要分两个指针,指针i和指针j,指针i用来在s串中扫,指针j用来在p串中扫。
同时在匹配过程中,如果没有出现什么意外(匹配不上)的话,匹配量就会一直加一加一,并且
for(int i = 1 , j=0;i<=s.length();i++)
{
while(j && s[i]!=p[j+1]) j=ne[j];
if(s[i]==p[j+1]) j++;
if(j==m)//匹配成功
{
printf("%d",i-m+1)
j = ne[j];
}
}
重新开始匹配之旅且借助next数组快速开局(重生之我是kmp匹配)
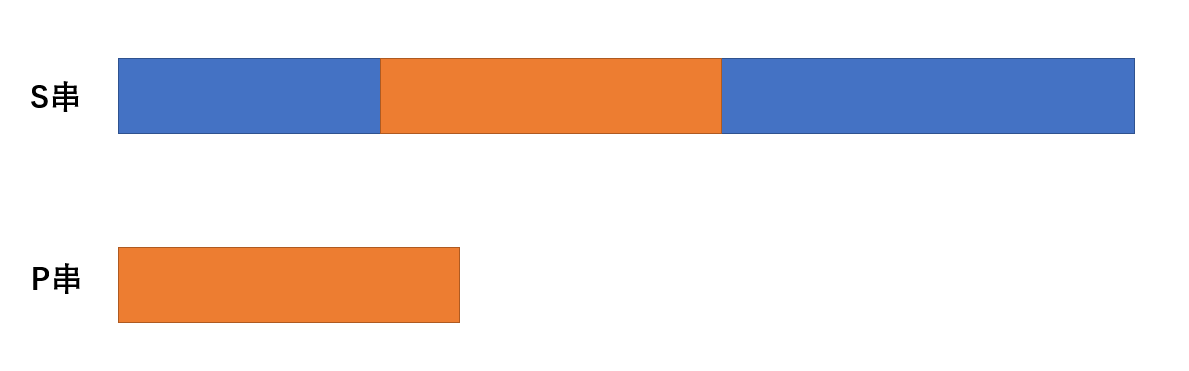
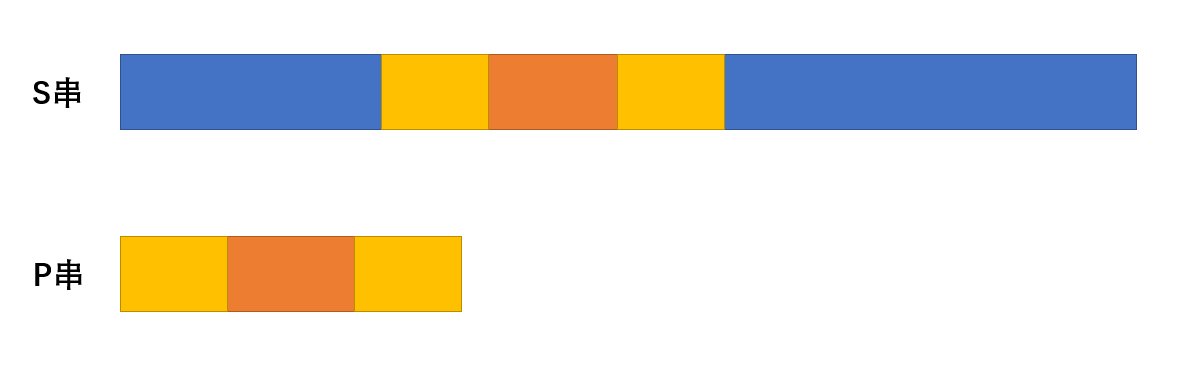
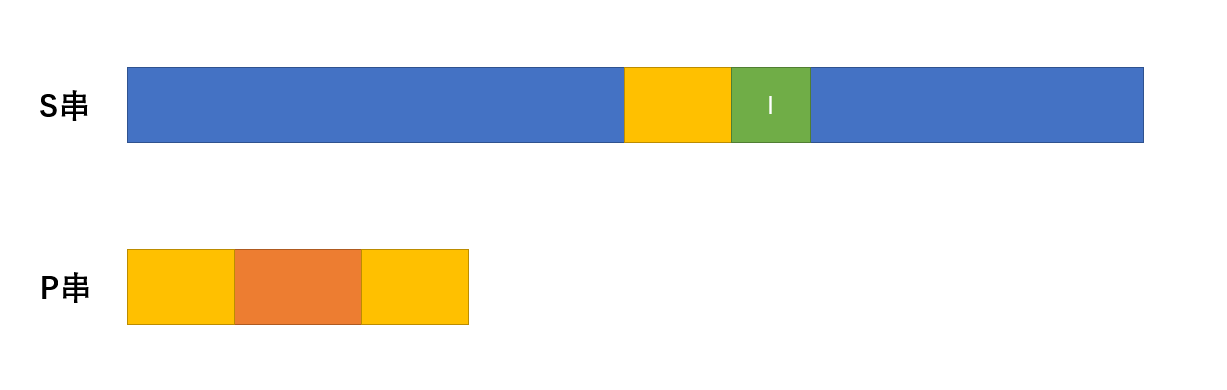
#include <bits/stdc++.h>
using namespace std;
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9')
{
if(ch=='-')
f=-1;
ch=getchar();
}
while(ch>='0' && ch<='9')
x=x*10+ch-'0',ch=getchar();
return x*f;
}
const int N = 1E6+10, M =1E5+10;
int n,m;
int ne[M];
char s[N],p[M];
int main()
{
m = read();
cin>>p+1;
n = read();
cin>>s+1;
for(int i=2,j=0;i<=m;i++)
{
while(j&&p[i]!=p[j+1]) j = ne[j];
if(p[i]==p[j+1]) j++;
ne[i] = j;
}
for(int i=1,j=0;i<=n;i++)
{
while(j&&s[i]!=p[j+1]) j=ne[j];
if(s[i]==p[j+1]) j++;
if(j==m)
{
printf("%d ",i-m);
j = ne[j];
}
}
return 0;
}