锁
获取操作acquire()方法是通过执行带有NX选项的SET命令来实现的,如果返回true则表示获取成功
文章字数统计和预览:
使用range方法得到字符串的长度
存储日志:
将一天的日志存储到一个键中,日期为键,时间和日志内容为值,多条之间用回车拼接
id生成器:
利用incr生成递增的id,使用setnx可以设置从指定的位置开始生成,而且只能在没有使用过递增的时候才能用,如果使用过递增产生数,则setnx不会成功,所有不能再设置值
计数器:
INCRBY命令和DECRBY命令对计数器的值执行加法操作和减法操作
GETSET方法来清零计数器并取得清零之前的旧值
限速器
限制每个IP地址在固定时间段内能够访问的页面数量,如一分钟30个页面,超过后需要进行身份验证
输入密码次数限制
def set_max_execute_times(self, max_execute_times):
"""
设置操作的最大可执行次数。
"""
self.client.set(self.key, max_execute_times)
def still_valid_to_execute(self):
"""
检查是否可以继续执行被限制的操作。
是的话返回 True ,否则返回 False 。
"""
num = self.client.decr(self.key)
return (num >= 0)
def remaining_execute_times(self):
"""
返回操作的剩余可执行次数。
"""
num = int(self.client.get(self.key))
if num < 0:
return 0
else:
return num
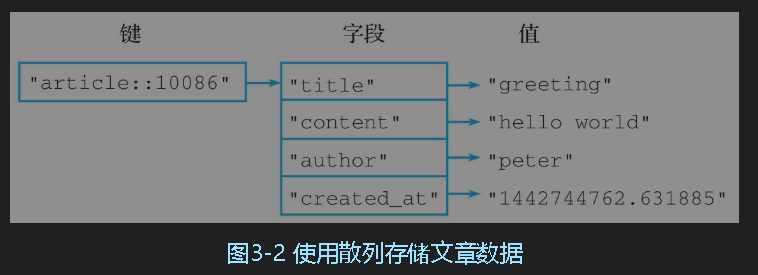
散列(hash)
- 字符串键实现的文章存储程序中,程序会为每篇文章创建4个字符串键,并把文章的标题、内容、作者和创建时间分别存储到这4个字符串键里面
这样会导致键太多,进行批量操作时比较麻烦
为此需要将多个字符串存为一组,就是hash了
hset:
如果给定字段并不存在于散列当中,那么这次设置就是一次创建操作,命令将在散列里面关联起给定的字段和值,然后返回1。
如果给定的字段原本已经存在于散列里面,那么这次设置就是一次更新操作,命令将使用用户给定的新值去覆盖字段原有的旧值,然后返回0。
hsetnx:
HSETNX命令在字段不存在并且成功为它设置值时返回1,在字段已经存在并导致设置操作未能成功执行时返回0
hget: hget article:1000
获取字段的值
- 短网址生成可以用散列表表示

from base36 import base10_to_base36
ID_COUNTER = "ShortyUrl::id_counter"
URL_HASH = "ShortyUrl::url_hash"
class ShortyUrl:
def __init__(self, client):
self.client = client
def shorten(self, target_url):
"""
为目标网址创建并储存相应的短网址 ID 。
"""
# 为目标网址创建新的数字 ID
new_id = self.client.incr(ID_COUNTER)
# 通过将 10 进制数字转换为 36 进制数字来创建短网址 ID
# 比如说,10 进制数字 10086 将被转换为 36 进制数字 7S6
short_id = base10_to_base36(new_id)
# 把短网址 ID 用作字段,目标网址用作值,
# 将它们之间的映射关系储存到散列里面
self.client.hset(URL_HASH, short_id, target_url)
return short_id
def restore(self, short_id):
"""
根据给定的短网址 ID ,返回与之对应的目标网址。
"""
return self.client.hget(URL_HASH, short_id)
如果我们在新浪微博中发言时输入网址http://redisdoc.com/geo/index.html,那么微博将把这个网址转换为相应的短网址http://t.cn/RqRRZ8n,
当用户访问这个短网址时,微博在后台就会对这次点击进行一些数据统计,然后再引导用户的浏览器跳转到http://redisdoc.com/geo/index.html上面
十进制转换成36进制可以有效缩短数字的长度
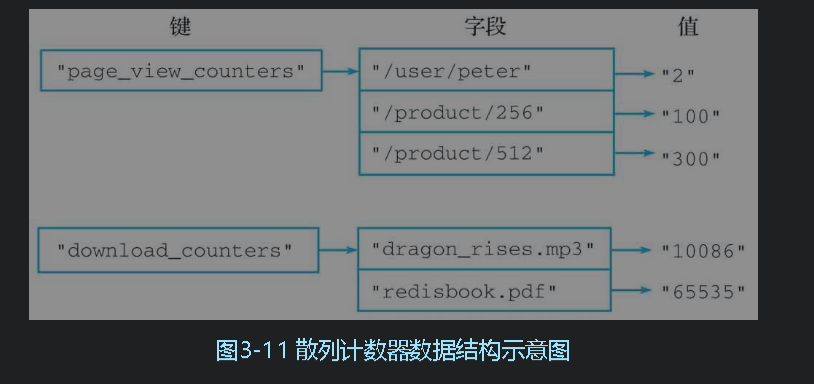
HINCRBY:hincrby article:10086 view_count 1
- 使用散列实现的计数器:可以实现多个计数器不受影响,多个关联的计数器集中管理
HSTRLEN获取字符串长度: eg:hstrlen article:10086 title
HEXISTS:检查字段是否存在
HDEL命令: 用于删除散列中的指定字段及其相关联的值:
HLEN: 获取散列包含的字段数量
- 实现用户登录会话:使用两个散列表,一个存用户的token,一个存过期时间
def generate_token():
"""
生成一个随机的会话令牌。
"""
random_string = str(random.getrandbits(256)).encode('utf-8')
return sha256(random_string).hexdigest()
class LoginSession:
def __init__(self, client, user_id):
self.client = client
self.user_id = user_id
def create(self, timeout=DEFAULT_TIMEOUT):
"""
创建新的登录会话并返回会话令牌,
可选的 timeout 参数用于指定会话的过期时间(以秒为单位)。
"""
# 生成会话令牌
user_token = generate_token()
# 计算会话到期时间戳
expire_timestamp = time()+timeout
# 以用户 ID 为字段,将令牌和到期时间戳分别储存到两个散列里面
self.client.hset(SESSION_TOKEN_HASH, self.user_id, user_token)
self.client.hset(SESSION_EXPIRE_TS_HASH, self.user_id, expire_timestamp)
# 将会话令牌返回给用户
return user_token
def validate(self, input_token):
"""
根据给定的令牌验证用户身份。
这个方法有四个可能的返回值,分别对应四种不同情况:
1. SESSION_NOT_LOGIN —— 用户尚未登录
2. SESSION_EXPIRED —— 会话已过期
3. SESSION_TOKEN_CORRECT —— 用户已登录,并且给定令牌与用户令牌相匹配
4. SESSION_TOKEN_INCORRECT —— 用户已登录,但给定令牌与用户令牌不匹配
"""
# 尝试从两个散列里面取出用户的会话令牌以及会话的过期时间戳
user_token = self.client.hget(SESSION_TOKEN_HASH, self.user_id)
expire_timestamp = self.client.hget(SESSION_EXPIRE_TS_HASH, self.user_id)
# 如果会话令牌或者过期时间戳不存在,那么说明用户尚未登录
if (user_token is None) or (expire_timestamp is None):
return SESSION_NOT_LOGIN
# 将当前时间戳与会话的过期时间戳进行对比,检查会话是否已过期
# 因为 HGET 命令返回的过期时间戳是字符串格式的
# 所以在进行对比之前要先将它转换成原来的浮点数格式
if time() > float(expire_timestamp):
return SESSION_EXPIRED
# 用户令牌存在并且未过期,那么检查它与给定令牌是否一致
if input_token == user_token:
return SESSION_TOKEN_CORRECT
else:
return SESSION_TOKEN_INCORRECT
def destroy(self):
"""
销毁会话。
"""
# 从两个散列里面分别删除用户的会话令牌以及会话的过期时间戳
self.client.hdel(SESSION_TOKEN_HASH, self.user_id)
self.client.hdel(SESSION_EXPIRE_TS_HASH, self.user_id)
HMSET:一次为多个字段设置值

可以将多条命令合并为一条命令发送,节省时间
HMGET:一次获取多个字段的值
HKEYS、HVALS、HGETALL:获取所有字段、所有值、所有字段和值
列表
LPUSH:将元素推入列表左端
RPUSH:将元素推入列表右端
LPUSHX命令只会在列表已经存在的情况下,将元素推入列表左端。
RPUSHX命令只会在列表已经存在的情况下,将元素推入列表右端
其中lpushx和rpushx每次只能推入一个元素
LPOP:弹出列表最左端的元素
RPOP:弹出列表最右端的元素
RPOPLPUSH:将右端弹出的元素推入左端 eg: rpoplpush list1 list2,将list1右边的元素弹出,放入list2的左边
- 先进先出队列
把用户的购买操作都放入先进先出队列里面,然后以队列方式处理用户的购买操作,这样程序就可以在不使用锁或者事务的情况下实现秒杀系统,
并且得益于先进先出队列的特性,这种秒杀系统可以按照用户执行购买操作的顺序来判断哪些用户可以成功执行购买操作,因此它是公平的
LLEN:获取列表的长度
LINDEX:获取指定索引上的元素
LRANGE:获取指定索引范围上的元素
- 应用例子: 分页
LSET:为指定索引设置新元素
LINSERT:将元素插入列表 通过使用LINSERT命令,用户可以将一个新元素插入列表某个指定元素的前面或者后面
- 应用实例:待办事项列表
class TodoList:
def __init__(self, client, user_id):
self.client = client
self.user_id = user_id
self.todo_list = make_todo_list_key(self.user_id)
self.done_list = make_done_list_key(self.user_id)
def add(self, event):
"""
将指定事项添加到待办事项列表中。
"""
self.client.lpush(self.todo_list, event)
def remove(self, event):
"""
从待办事项列表中移除指定的事项。
"""
self.client.lrem(self.todo_list, 0, event)
def done(self, event):
"""
将待办事项列表中的指定事项移动到已完成事项列表,
以此来表示该事项已完成。
"""
# 从待办事项列表中移除指定事项
self.remove(event)
# 并将它添加到已完成事项列表中
self.client.lpush(self.done_list, event)
def show_todo_list(self):
"""
列出所有待办事项。
"""
return self.client.lrange(self.todo_list, 0, -1)
def show_done_list(self):
"""
列出所有已完成事项。
"""
return self.client.lrange(self.done_list, 0, -1)
BLPOP:阻塞式左端弹出操作 eg: blpop list 5 阻塞5秒 BRPOP:阻塞式右端弹出操作
- 使用例子: 带有阻塞功能的消息队列
例如,为了验证用户身份的有效性,有些网站在注册新用户的时候,会向用户给定的邮件地址发送一封激活邮件,
用户只有在点击了验证邮件里面的激活链接之后,新注册的账号才能够正常使用
可以在发送邮件的时候将邮件推送到队列中发送,然后前端马上返回邮件已发送,请查收
集合
列表可以存储重复元素,而集合只会存储非重复元素
列表以有序方式存储元素,而集合则以无序方式存储元素
集合其实是无序的列表
SADD:将元素添加到集合 eg: sadd a a
SREM:从集合中移除元素
SMOVE:将元素从一个集合移动到另一个集合
SMEMBERS:获取集合包含的所有元素
SCARD:获取集合包含的元素数量
SISMEMBER:检查给定元素是否存在于集合
- 实例:唯一计数器
记录网站的用户量,需要根据ip去重后得到的计数,适合用set存 - 实例:打标签
比如论坛可能会允许用户为帖子添加标签,这些标签既可以对帖子进行归类,又可以让其他用户快速地了解到帖子要讲述的内容。
一个图书分类网站可能会允许用户为自己收藏的每一本书添加标签,使得用户可以快速地找到被添加了某个标签的所有图书,
并且网站还可以根据用户的这些标签进行数据分析,从而帮助用户找到他们可能感兴趣的图书
购物网站也可以为自己的商品加上标签,比如“新上架”“热销中”“原装进口”等,方便顾客了解每件商品的不同特点和属性
def make_tag_key(item):
return item + "::tags"
class Tagging:
def __init__(self, client, item):
self.client = client
self.key = make_tag_key(item)
def add(self, *tags):
"""
为对象添加一个或多个标签。
"""
self.client.sadd(self.key, *tags)
def remove(self, *tags):
"""
移除对象的一个或多个标签。
"""
self.client.srem(self.key, *tags)
def is_included(self, tag):
"""
检查对象是否带有给定的标签,
是的话返回 True ,不是的话返回 False 。
"""
return self.client.sismember(self.key, tag)
def get_all_tags(self):
"""
返回对象带有的所有标签。
"""
return self.client.smembers(self.key)
def count(self):
"""
返回对象带有的标签数量。
"""
return self.client.scard(self.key)

点赞功能
class Like:
def __init__(self, client, key):
self.client = client
self.key = key
def cast(self, user):
"""
用户尝试进行点赞。
如果此次点赞执行成功,那么返回 True ;
如果用户之前已经点过赞,那么返回 False 表示此次点赞无效。
"""
return self.client.sadd(self.key, user) == 1
def undo(self, user):
"""
取消用户的点赞。
"""
self.client.srem(self.key, user)
def is_liked(self, user):
"""
检查用户是否已经点过赞。
是的话返回 True ,否则的话返回 False 。
"""
return self.client.sismember(self.key, user)
def get_all_liked_users(self):
"""
返回所有已经点过赞的用户。
"""
return self.client.smembers(self.key)
def count(self):
"""
返回已点赞用户的人数。
"""
return self.client.scard(self.key)
投票
使用两个集合来分别存储投支持票的用户以及投反对票的用户,然后通过对这两个集合执行命令来实现投票、取消投票、统计投票数量、获取已投票用户名单等功能
def vote_up_key(vote_target):
return vote_target + "::vote_up"
def vote_down_key(vote_target):
return vote_target + "::vote_down"
class Vote:
def __init__(self, client, vote_target):
self.client = client
self.vote_up_set = vote_up_key(vote_target)
self.vote_down_set = vote_down_key(vote_target)
def is_voted(self, user):
"""
检查用户是否已经投过票(可以是赞成票也可以是反对票),
是的话返回 True ,否则返回 False 。
"""
return self.client.sismember(self.vote_up_set, user) or
self.client.sismember(self.vote_down_set, user)
def vote_up(self, user):
"""
让用户投赞成票,并在投票成功时返回 True ;
如果用户已经投过票,那么返回 False 表示此次投票无效。
"""
if self.is_voted(user):
return False
self.client.sadd(self.vote_up_set, user)
return True
def vote_down(self, user):
"""
让用户投反对票,并在投票成功时返回 True ;
如果用户已经投过票,那么返回 False 表示此次投票无效。
"""
if self.is_voted(user):
return False
self.client.sadd(self.vote_down_set, user)
return True
def undo(self, user):
"""
取消用户的投票。
"""
self.client.srem(self.vote_up_set, user)
self.client.srem(self.vote_down_set, user)
def vote_up_count(self):
"""
返回投支持票的用户数量。
"""
return self.client.scard(self.vote_up_set)
def get_all_vote_up_users(self):
"""
返回所有投支持票的用户。
"""
return self.client.smembers(self.vote_up_set)
def vote_down_count(self):
"""
返回投反对票的用户数量。
"""
return self.client.scard(self.vote_down_set)
def get_all_vote_down_users(self):
"""
返回所有投反对票的用户。
"""
return self.client.smembers(self.vote_down_set)
- 实例: 社交关系
微博、Twitter以及类似的社交网站都允许用户通过加关注或者加好友的方式,构建一种社交关系。这些网站上的每个用户都可以关注其他用户,
也可以被其他用户关注。通过正在关注名单(followinglist),用户可以查看自己正在关注的用户及其人数;通过关注者名单(follower list),
用户可以查看有哪些人正在关注自己,以及有多少人正在关注自己。
●程序为每个用户维护两个集合,一个集合存储用户的正在关注名单,而另一个集合则存储用户的关注者名单。
●当一个用户(关注者)关注另一个用户(被关注者)的时候,程序会将被关注者添加到关注者的正在关注名单中,并将关注者添加到被关注者的关注者名单里面。
●当关注者取消对被关注者的关注时,程序会将被关注者从关注者的正在关注名单中移除,并将关注者从被关注者的关注者名单中移除
def following_key(user):
return user + "::following"
def follower_key(user):
return user + "::follower"
class Relationship:
def __init__(self, client, user):
self.client = client
self.user = user
def follow(self, target):
"""
关注目标用户。
"""
# 把 target 添加到当前用户的正在关注集合里面
user_following_set = following_key(self.user)
self.client.sadd(user_following_set, target)
# 把当前用户添加到 target 的关注者集合里面
target_follower_set = follower_key(target)
self.client.sadd(target_follower_set, self.user)
def unfollow(self, target):
"""
取消对目标用户的关注。
"""
# 从当前用户的正在关注集合中移除 target
user_following_set = following_key(self.user)
self.client.srem(user_following_set, target)
# 从 target 的关注者集合中移除当前用户
target_follower_set = follower_key(target)
self.client.srem(target_follower_set, self.user)
def is_following(self, target):
"""
检查当前用户是否正在关注目标用户,
是的话返回 True ,否则返回 False 。
"""
# 如果 target 存在于当前用户的正在关注集合中
# 那么说明当前用户正在关注 target
user_following_set = following_key(self.user)
return self.client.sismember(user_following_set, target)
def get_all_following(self):
"""
返回当前用户正在关注的所有人。
"""
user_following_set = following_key(self.user)
return self.client.smembers(user_following_set)
def get_all_follower(self):
"""
返回当前用户的所有关注者。
"""
user_follower_set = follower_key(self.user)
return self.client.smembers(user_follower_set)
def count_following(self):
"""
返回当前用户正在关注的人数。
"""
user_following_set = following_key(self.user)
return self.client.scard(user_following_set)
def count_follower(self):
"""
返回当前用户的关注者人数。
"""
user_follower_set = follower_key(self.user)
return self.client.scard(user_follower_set)
SRANDMEMBER:随机获取集合中的元素 eg: srandmember a 从集合随机取出一个元素,但是集合里的元素不清楚,srandmember a 5返回指定数量的元素,超出则返回全部
SPOP:随机地从集合中移除指定数量的元素 spop a 2
SPOP命令和SRANDMEMBER命令的主要区别在于,SPOP命令会移除被随机选中的元素,而SRANDMEMBER命令则不会移除被随机选中的元素
实例: 抽奖
而商家则需要从所有参加抽奖的消费者中选出指定数量的获奖者,并向他们赠送物品、金钱或者其他购物优惠。
class Lottery:
def __init__(self, client, key):
self.client = client
self.key = key
def add_player(self, user):
"""
将用户添加到抽奖名单当中。
"""
self.client.sadd(self.key, user)
def get_all_players(self):
"""
返回参加抽奖活动的所有用户。
"""
return self.client.smembers(self.key)
def player_count(self):
"""
返回参加抽奖活动的用户人数。
"""
return self.client.scard(self.key)
def draw(self, number):
"""
抽取指定数量的获奖者。
"""
return self.client.srandmember(self.key, number)
SINTER、SINTERSTORE:对集合执行交集计算
SUNION、SUNIONSTORE:对集合执行并集计算
SDIFF、SDIFFSTORE:对集合执行差集计算
- 示例:共同关注与推荐关注
共同关注:要实现共同关注功能,程序需要做的就是计算出两个用户的正在关注集合之间的交集,这一点可以通过前面介绍的SINTER命令和SINTERSTORE命令来完成
推荐关注:从用户的正在关注集合中随机选出指定数量的用户作为种子用户,然后对这些种子用户的正在关注集合执行并集计算,最后从这个并集中随机地选出一些用户作为推荐关注的对象
def following_key(user):
return user + "::following"
def recommend_follow_key(user):
return user + "::recommend_follow"
class RecommendFollow:
def __init__(self, client, user):
self.client = client
self.user = user
def calculate(self, seed_size):
"""
计算并储存用户的推荐关注数据。
"""
# 1)从用户关注的人中随机选一些人作为种子用户
user_following_set = following_key(self.user)
following_targets = self.client.srandmember(user_following_set, seed_size)
# 2)收集种子用户的正在关注集合键名
target_sets = set()
for target in following_targets:
target_sets.add(following_key(target))
# 3)对所有种子用户的正在关注集合执行并集计算,并储存结果
return self.client.sunionstore(recommend_follow_key(self.user), *target_sets)
def fetch_result(self, number):
"""
从已有的推荐关注数据中随机地获取指定数量的推荐关注用户。
"""
return self.client.srandmember(recommend_follow_key(self.user), number)
def delete_result(self):
"""
删除已计算出的推荐关注数据。
"""
self.client.delete(recommend_follow_key(self.user))
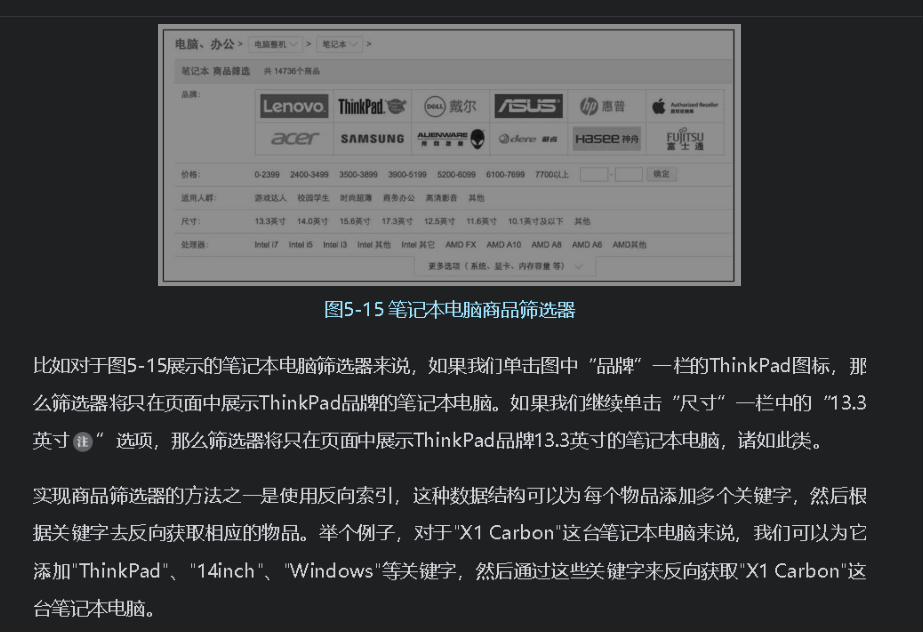
- 实例: 使用反向索引构建商品筛选器

有序集合
Redis的有序集合(sorted set)同时具有“有序”和“集合”两种性质
这种数据结构中的每个元素都由一个成员和一个与成员相关联的分值组成
这个集合也是不允许重复,只是多了一个分数记录顺序
ZADD:添加或更新成员 eg: zadd salary 100 a 200 b 300 c 每个元素需要带一个分数
ZREM:移除指定的成员 eg: zrem salary a
ZSCORE:获取成员的分值 eg: zscore salary b
ZINCRBY:对成员的分值执行自增或自减操作,如果不存在则直接添加 eg: zincrby salary 20000 b
ZCARD:获取有序集合的大小eg: zcard salary
ZRANK、ZREVRANK:获取成员在有序集合中的排名,分别是升序和降序 eg: zrank salary b
- 通过ZRANGE命令和ZREVRANGE命令,用户可以以升序排列或者降序排列方式,从有序集合中获取指定索引范围内的成员
- withscores获取分数: zrange salary 0 2 withscores
- 实例:排行榜
ZRANGEBYSCORE、ZREVRANGEBYSCORE:获取指定分值范围内的成员 eg: zrangebyscore salary 0 500
ZCOUNT:统计指定分值范围内的成员数量 eg: zcount salary 0 300
- 示例:时间线
博客系统会按照文章发布时间的先后,把最近发布的文章放在前面,而发布时间较早的文章则放在后面,这样访客在浏览博客的时候,就可以先阅读最新的文章,然后再阅读较早的文章。
ZUNIONSTORE、ZINTERSTORE:有序集合的并集运算和交集运算
PFADD:对集合元素进行计数
第一次 pfadd alphabets a b c 返回1
第二次 pfadd alphabets a 返回0 说明a已经被计数过了
然后pfcount alphabets 可以得到总数,但是只是返回近似的基数不一定准确
- 返回并集的近似基数: pfcount aa bb

与集合实现的唯一计数器相比,使用HyperLogLog实现的唯一计数器并不会因为被计数元素的增多而变大,因此它无论是对10万个、100万个还是1000万个唯一IP进行计数,计数器消耗的内存数量都不会发生变化。与此同时,这个新计数器即使在每天唯一IP数量达到1000万个的情况下,记录一年的唯一IP数量也只需要4.32MB内存,这比同等情况下使用集合去实现唯一计数器所需的内存要少得多。 - 示例:检测重复信息
在构建应用程序的过程中,我们经常需要与广告等垃圾信息做斗争。因为垃圾信息的发送者通常会使用不同的账号、在不同的地方发送相同的垃圾信息,
所以寻找垃圾信息的一种比较简单、有效的方法就是找出那些重复的信息:如果两个不同的用户发送了完全相同的信息,
或者同一个用户重复地发送了多次完全相同的信息,那么这些信息很有可能就是垃圾信息
为了降低鉴别重复信息所需的复杂度,我们可以使用HyperLogLog来记录所有已发送的信息——每当用户发送一条信息时,
程序就使用PFADD命令将这条信息添加到HyperLogLog中:
●如果命令返回1,那么这条信息就是未出现过的新信息。
●如果命令返回0,那么这条信息就是已经出现过的重复信息
因为HyperLogLog使用的是概率算法,所以即使信息的长度非常长,HyperLogLog判断信息是否重复所需的时间也非常短。
另外,因为HyperLogLog并不会随着被计数信息的增多而变大,所以程序可以把所有需要检测的信息都记录到同一个HyperLogLog中,
这使得实现重复信息检测程序所需的空间极大地减少
class DuplicateChecker:
def __init__(self, client, key):
self.client = client
self.key = key
def is_duplicated(self, content):
"""
在信息重复时返回 True ,未重复时返回 False 。
"""
return self.client.pfadd(self.key, content) == 0
def unique_count(self):
"""
返回检查器已经检查过的非重复信息数量。
"""
return self.client.pfcount(self.key)
PFMERGE:计算多个HyperLogLog的并集
PFMERGE命令可以对多个给定的HyperLogLog执行并集计算,然后把计算得出的并集HyperLogLog保存到指定的键中 实现每周/月度/年度计数器
● 通过对一周内每天的唯一访客IP计数器执行PFMERGE命令,我们可以计算出那一周的唯一访客IP数量。
● 通过对一个月内每天的唯一访客IP计数器执行PFMERGE命令,我们可以计算出那一个月的唯一访客IP数量。
● 年度甚至更长时间的唯一访客IP数量也可以按照类似的方法计算。
● HyperLogLog是一个概率算法,它可以对大量元素进行计数,并计算出这些元素的近似基数。
● 无论被计数的元素有多少个,HyperLogLog只使用固定大小的内存,其内存占用不会因为被计数元素增多而增多。
● 在有需要的情况下,用户可以使用PFMERGE命令代替针对多个HyperLogLog的PFCOUNT命令调用,从而避免重复执行相同的并集计算。
● HyperLogLog不仅可以用于计数问题,还可以用于去重问题。
- 用户行为记录器, 可以使用位图来计算
def make_action_key(action):
return "action_recorder::" + action
class ActionRecorder:
def __init__(self, client, action):
self.client = client
self.bitmap = make_action_key(action)
def perform_by(self, user_id):
"""
记录执行了指定行为的用户。
"""
self.client.setbit(self.bitmap, user_id, 1)
def is_performed_by(self, user_id):
"""
检查给定用户是否执行了指定行为,是的话返回 True ,反之返回 False 。
"""
return self.client.getbit(self.bitmap, user_id) == 1
def count_performed(self):
"""
返回执行了指定行为的用户人数。
"""
return self.client.bitcount(self.bitmap)
使用lua脚本实现的分布式锁
class IdentityLock:
def __init__(self, client, key):
self.client = client
self.key = key
def acquire(self, identity, timeout):
"""
尝试获取一个带有身份标识符和最大使用时限的锁,
成功时返回 True ,失败时返回 False 。
"""
result = self.client.set(self.key, identity, ex=timeout, nx=True)
return result is not None
def release(self, input_identity):
"""
根据给定的标识符,尝试释放锁。
返回 True 表示释放成功;
返回 False 则表示给定的标识符与锁持有者的标识符不相同,释放请求被拒绝。
"""
script = """
-- 使用局部变量储存锁键键名以及标识符,提高脚本的可读性
local key = KEYS[1]
local input_identity = ARGV[1]
-- 获取锁键储存的标识符
-- 当标识符为空时,Lua 会将 GET 返回的 nil 转换为 false
local lock_identity = redis.call("GET", key)
if lock_identity == false then
-- 如果锁键储存的标识符为空,那么说明锁已经被释放
return true
elseif input_identity == lock_identity then
-- 如果给定的标识符与锁键储存的标识符相同,那么释放这个锁
redis.call("DEL", key)
return true
else
-- 如果给定的标识符与锁键储存的标识符并不相同
-- 那么说明当前客户端不是锁的持有者,拒绝本次释放请求
return false
end
"""
# 因为 Redis 会将脚本返回的 true 转换为数字 1
# 所以这里通过检查脚本返回值是否为 1 来判断解锁操作是否成功
result = self.client.eval(script, 1, self.key, input_identity)
return result == 1
redis+lua实现分布式限流
限流脚本
local key = "req.rate.limit:" .. KEYS[1] --限流KEY
local limitCount = tonumber(ARGV[1]) --限流大小
local limitTime = tonumber(ARGV[2]) --限流时间
local current = tonumber(redis.call('get', key) or "0")
if current + 1 > limitCount then --如果超出限流大小
return 0
else --请求数+1,并设置1秒过期
redis.call("INCRBY", key,"1")
redis.call("expire", key,limitTime)
return current + 1
end
springboot中的lua配置
@Configuration
public class LuaConfiguration {
@Bean
public DefaultRedisScript<Number> redisScript() {
DefaultRedisScript<Number> redisScript = new DefaultRedisScript<>();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("req_ratelimit.lua")));
redisScript.setResultType(Number.class);
return redisScript;
}
}
设置注解
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface RateLimiter {
/**
* 限流唯一标识
* @return
*/
String key() default "";
/**
* 限流时间
* @return
*/
int time();
/**
* 限流次数
* @return
*/
int count();
}
注解内容
@Aspect
@Configuration
@Slf4j
public class RateLimiterAspect {
@Autowired
private RedisTemplate<String, Serializable> redisTemplate;
@Autowired
private DefaultRedisScript<Number> redisScript;
@Around("execution(* com.sunlands.zlcx.datafix.web ..*(..) )")
public Object interceptor(ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
Class<?> targetClass = method.getDeclaringClass();
RateLimiter rateLimit = method.getAnnotation(RateLimiter.class);
if (rateLimit != null) {
HttpServletRequest request = ((ServletRequestAttributes) RequestContextHolder.getRequestAttributes()).getRequest();
String ipAddress = getIpAddr(request);
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(ipAddress).append("-")
.append(targetClass.getName()).append("- ")
.append(method.getName()).append("-")
.append(rateLimit.key());
List<String> keys = Collections.singletonList(stringBuffer.toString());
Number number = redisTemplate.execute(redisScript, keys, rateLimit.count(), rateLimit.time());
if (number != null && number.intValue() != 0 && number.intValue() <= rateLimit.count()) {
log.info("限流时间段内访问第:{} 次", number.toString());
return joinPoint.proceed();
}
} else {
return joinPoint.proceed();
}
throw new RuntimeException("已经到设置限流次数");
}
public static String getIpAddr(HttpServletRequest request) {
String ipAddress = null;
try {
ipAddress = request.getHeader("x-forwarded-for");
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getHeader("Proxy-Client-IP");
}
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getHeader("WL-Proxy-Client-IP");
}
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getRemoteAddr();
}
// 对于通过多个代理的情况,第一个IP为客户端真实IP,多个IP按照','分割
if (ipAddress != null && ipAddress.length() > 15) {
// "***.***.***.***".length()= 15
if (ipAddress.indexOf(",") > 0) {
ipAddress = ipAddress.substring(0, ipAddress.indexOf(","));
}
}
} catch (Exception e) {
ipAddress = "";
}
return ipAddress;
}
}
使用注解
@RestController
@Slf4j
@RequestMapping("limit")
public class RateLimiterController {
@Autowired
private RedisTemplate redisTemplate;
@GetMapping(value = "/test")
@RateLimiter(key = "test", time = 10, count = 1)
public ResponseEntity<Object> test() {
String date = DateFormatUtils.format(new Date(), "yyyy-MM-dd HH:mm:ss.SSS");
RedisAtomicInteger limitCounter = new RedisAtomicInteger("limitCounter", redisTemplate.getConnectionFactory());
String str = date + " 累计访问次数:" + limitCounter.getAndIncrement();
log.info(str);
return ResponseEntity.ok(str);
}
}
持久化
RDB持久化
RDB持久化是Redis默认使用的持久化功能
SAVE:阻塞服务器并创建RDB文件
收到SAVE命令的Redis服务器将遍历数据库包含的所有数据库,并将各个数据库包含的键值对全部记录到RDB文件中。
在SAVE命令执行期间,Redis服务器将阻塞,直到RDB文件创建完毕为止。
如果Redis服务器在执行SAVE命令时已经拥有了相应的RDB文件,那么服务器将使用新创建的RDB文件代替已有的RDB文件
BGSAVE:以非阻塞方式创建RDB文件
1)创建一个子进程。2)子进程执行SAVE命令,创建新的RDB文件。
3)RDB文件创建完毕之后,子进程退出并通知Redis服务器进程(父进程)新RDB文件已经完成。
4)Redis服务器进程使用新RDB文件替换已有的RDB文件。
- 虽然从技术上来说,用户可以在每次执行写命令之后都执行一次SAVE命令,以此来保证数据处于绝对安全的状态,但这样一来Redis服务器的性能将下降至无法正常使用的水平。
相反,用户如果想要保证服务器的性能处于合理水平,就不能过于频繁地创建RDB文件,这样一来,也就不可避免地会出现因为停机而丢失大量数据的情况
AOF持久化
与全量式的RDB持久化功能不同,AOF提供的是增量式的持久化功能,
这种持久化的核心原理在于:服务器每次执行完写命令之后,都会以协议文本的方式将被执行的命令追加到AOF文件的末尾。
这样一来,服务器在停机之后,只要重新执行AOF文件中保存的Redis命令,就可以将数据库恢复至停机之前的状态
- 设置AOF文件的冲洗频率
appendfsync选项拥有always、everysec和no 3个值可选,
它们代表的意义分别为:
●always——每执行一个写命令,就对AOF文件执行一次冲洗操作。
●everysec——每隔1s,就对AOF文件执行一次冲洗操作。
●no——不主动对AOF文件执行冲洗操作,由操作系统决定何时对AOF进行冲洗。
AOF重写: 用户可以通过执行BGREWRITEAOF命令显式地触发AOF重写操作
RDB-AOF混合持久化
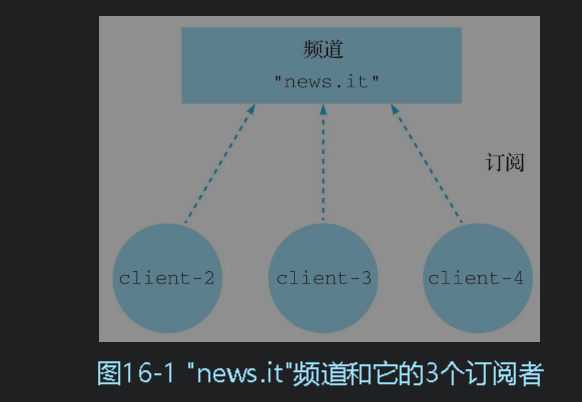
发布与订阅