1.bin/hdfs namenode -format
** 注意事项
1.在配置好了配置文件之后,首次启动之前,做初始化操作
2.在后续启动的时候,不需要再初始化
3.初始化的一些影响
一.初始化操作
@_为什么要初始化,它到底做了哪些事情?
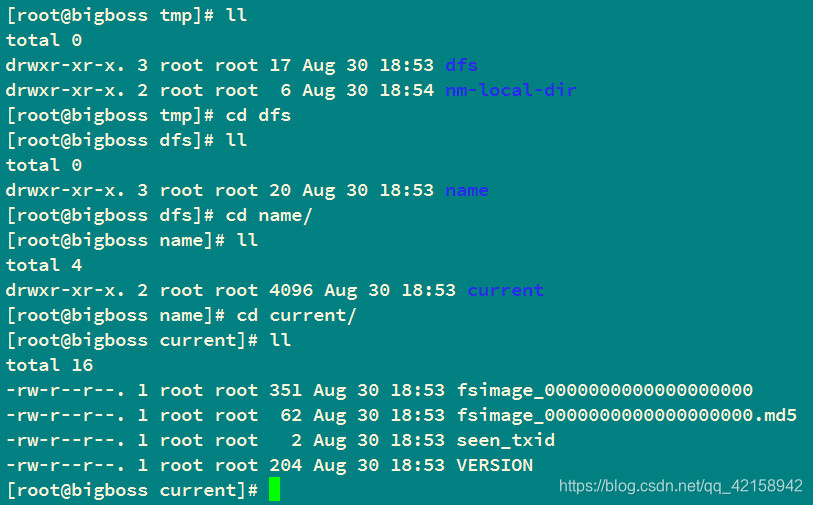
答:初始化的时候,会新建文件夹,dfs/name,文件夹的名字是dfs,在他下面会新建一个文件夹,名字是name
×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××
初始化之前,建议先把之前的版本信息全部删除
[root@bigboss hadoop-2.6.0]# rm -rf data/tmp/*
[root@bigboss hadoop-2.6.0]# hdfs namenode -format
初始化成功:
Storage directory /opt/programs/hadoop-2.6.0/data/tmp/dfs/name has been successfully formatted.
×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××
2.初始化的作用
1.生成namenode的文件目录结构
--------in_use.lock是在使用中才会生成
--------和edits相关的也是在开始使用之后,才会生成
2.确定了三个ID,namespaceID、clusterID、blockpoolID

3.生成了文件系统镜像fsimage_0000000000000000000
3.只启动namenode
$ sbin/hadoop-daemon.sh start namenode

1.会生成锁文件,in_use.lock
2.会生成edits相关文件edits_inprogress_0000000000000000001,
并且seen_txid会改变成和edits_inprogress文件后面的编号id一样
[root@bigboss current]# cat seen_txid
1
4.启动datanode
$ sbin/hadoop-daemon.sh start datanode
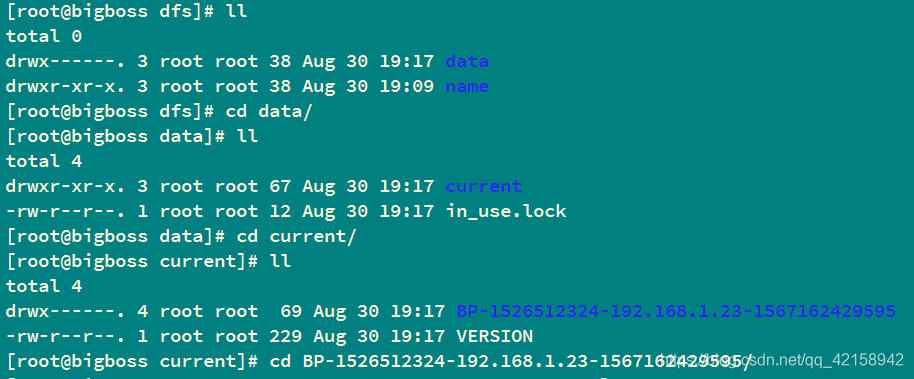
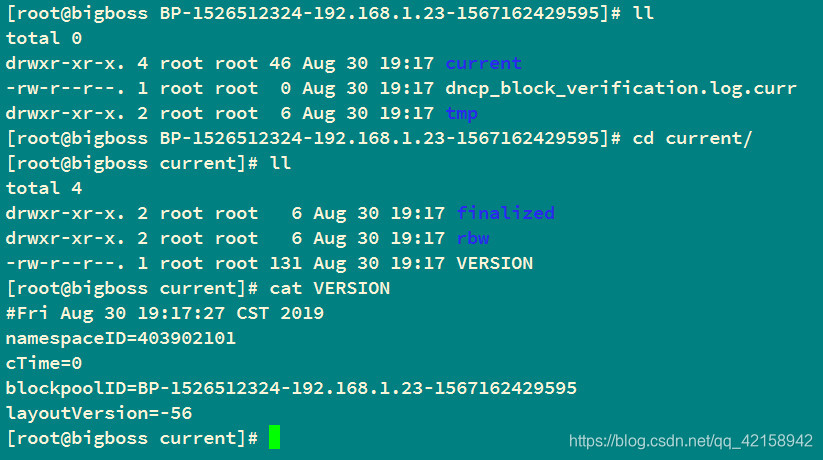
@_图中tmp/,finalized/,rbw/为空
1.会生成datanode的文件目录结构
current文件夹和锁文件in_user.lock是一起生成的
2.会生成块池id对应的文件夹和VERSION文件
为什么会自动配对?
答:slaves文件规定hadoop集群的所有从节点的主机,默认值是localhost,所以伪分布式可以配对成功
**hadoop的从节点类型不止一种
@hdfs的从节点 datanode
@yarn的从节点 nodemanager
为什么要这样设计?
3.三个配对id的位置
1.namespaceID在 BP…里面的current文件夹下的VERSION文件里面
2.blockpoolID 在BP…里面的current文件夹下的VERSION文件里面
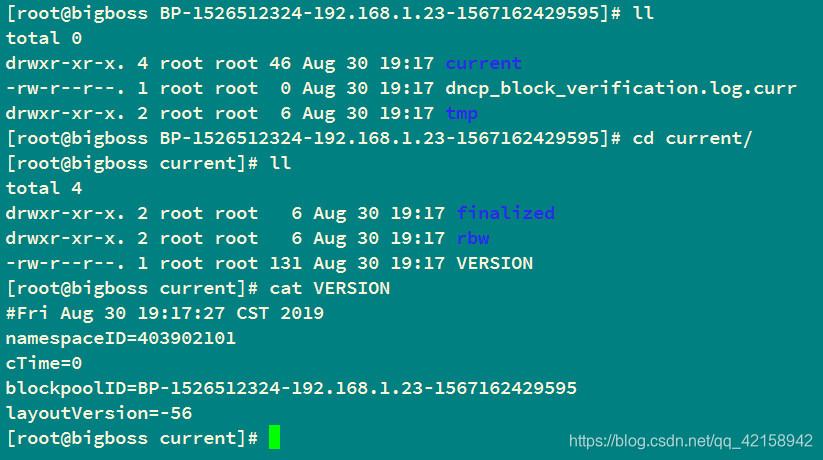
3.clusterID 在BP…同级的VERSION文件里面

5.没有操作任何的hdfs的时候
/opt/programs/hadoop-2.6.0/data/tmp/dfs/data/current/BP-1003710699-192.168.1.211-1567039419296/current/finalized
下是空的,跟hdfs上保存数据相关的所有内容,都保存在这个文件夹下
二.hadoop的配置
1.伪分布式
2.分布式配置
------在伪分布式的基础上
1.所有节点都要安装jdk,ssh免密登录
2.确定各个节点上运行的服务
1个namenode
3个datanode
1个secondarynamenode
1个resourcemanager
3个nodemanager
3.修改配置文件
core-site.xml:
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigboss:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/programs/hadoop-2.6.0/data/tmp</value>
</property>
</configuration>
hdfs-site.xml:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigboss_c:50090</value>
</property>
</configuration>
mapred-site.xml:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigboss_b:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>bigboss_b:10020</value>
</property>
yarn-site.xml:
注意
<value>192.168.1.24</value>写成<value>bigboss_b</value>可能会导致resourcemanager启动失败,原因未知,已确认ip与主机名映射的hosts文件无误,之前使用也没有任何问题,但是在这里出问题了。老师和其他同学用hadoop2主机名没有出现问题,我bigboss_b和同桌caixunkun2都出问题了。。。辣鸡玩意儿!!!
<name>yarn.resourcemanager.hostname</name>
<value>bigboss_b</value>
正文:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.1.24</value>
</property>
<!-- 日志聚集功能开启 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志文件保存的时间,以秒为单位 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
4.把hadoop应用程序拷贝到其他节点
hadoop分布式系统,每个节点的配置要完全一样
5.删除data/tmp/*
6.启动服务
为什么不能用start-all.sh?
答:使用这个命令,需要hdfs和yarn的主节点都在当前节点上,才可以统一启动
使用start-dfs.sh和start-yarn.sh来代替它
start-dfs.sh 这个命令要在namenode所在的节点执行,才能正常启动hdfs服务
start-yarn.sh 这个命令要在resourcemanager所在的节点执行,才能正常启动yarn服务
7.测试是否能正常运行
1.webui
2.能使用服务的功能
1.hdfs上面新建文件夹
主要是集群内部的节点,都可以使用hdfs的shell命令
bin/hdfs dfs -mkdir /datanode
2.yarn的测试
配置好了hadoop的默认文件系统是hdfs之后,会把相关的操作都默认为是基于hdfs的操作
1.在hdfs上创建文件夹
2.上传文件
3.运行任务
8.添加配置项
上面配置文件中已经设置了~
日志聚集和任务历史服务
三.hdfs的细节
1.fsimage到底是干嘛的
文件系统镜像,把文件系统的某一时刻的状态持久化到磁盘
某一时刻的状态:namenode某一时刻内存中存在的hdfs相关的信息,元数据
secondarynamenode帮助namenode进行更新fsimage
2.edits是干嘛的
edits 编辑操作记录
根据操作记录,可以推断出namenode内存保存的元数据信息
四.fsimage里面保存的信息是完整的内存结构吗?
答:fsimage是内存信息镜像,包括所有的元数据信息,除了每个块所在的节点信息
所以每次启动之后,namenode再重构了元数据之后,他会接受每个datanode的汇报信息
汇报的信息就是自己上面有哪些块
需要时间把块和节点的映射补充完整,在补充完整之前,namenode不会对外提供服务,这一段时间就是安全模式
在安全模式下,只能做查询的操作,不能增删改
退出安全模式的条件:所有hdfs上的块的信息,跟主机的映射达到了99.999%之后会退出安全模式
五.安全模式
1.不是只有在启动的时候才可以有安全模式
可以手动开启或结束安全模式
2.一般手动进入安全模式的场景
不能提供服务,不会修改元数据,namenode直接保存元数据到磁盘,形成fsimage
3.下一次checkpoint的时候,sn会怎么做
1.会拷贝fsimage和edits
会造成sn上的edits的缺失
2.只会拷贝edits,会造成sn上面没有namenode紧急保存的fsimage
sn会造成fsimage的缺失
六.md5加密的必要性
在传输结束之后,验证文件的完整性和正确性