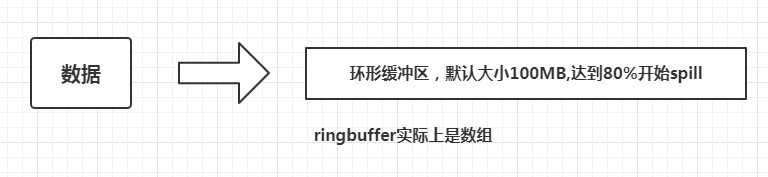
【Hadoop】mapreduce环形缓冲区 mapreduce过程解析 数据在map中怎么写入磁盘? 数据:经过map逻辑处理过后的数据(key,value)… 磁盘:本地磁盘 环形缓冲区 1.为什么要环形缓冲区? 答:使用环形缓冲区,便于写入缓冲区和写出缓冲区同时进行。 2.为什么不等缓冲区满了再spill? 答:会出现阻塞。 3.数据的分区和排序是在哪完成的? 答:分区是根据元数据meta中的分区号partition来分区的,排序是在spill的时候排序。 环形缓冲区详解 不同方向写入数据 图示: