开始的时候,就是利用规则,但是有瓶颈,后来就有了基于统计学的方向,建立模型,让机器基于模型的规则,进行数据的拟合,模型里有很多参数,有可变化的东西,是机器自己学习的,效果有超过规则的可能,两个学派,基于规则,基于数学(统计学),后来机器学习慢慢后来居上,机器学习慢慢发展出很多的算法,逻辑树、决策树很早就有,神经网络雏形是比较早有的。
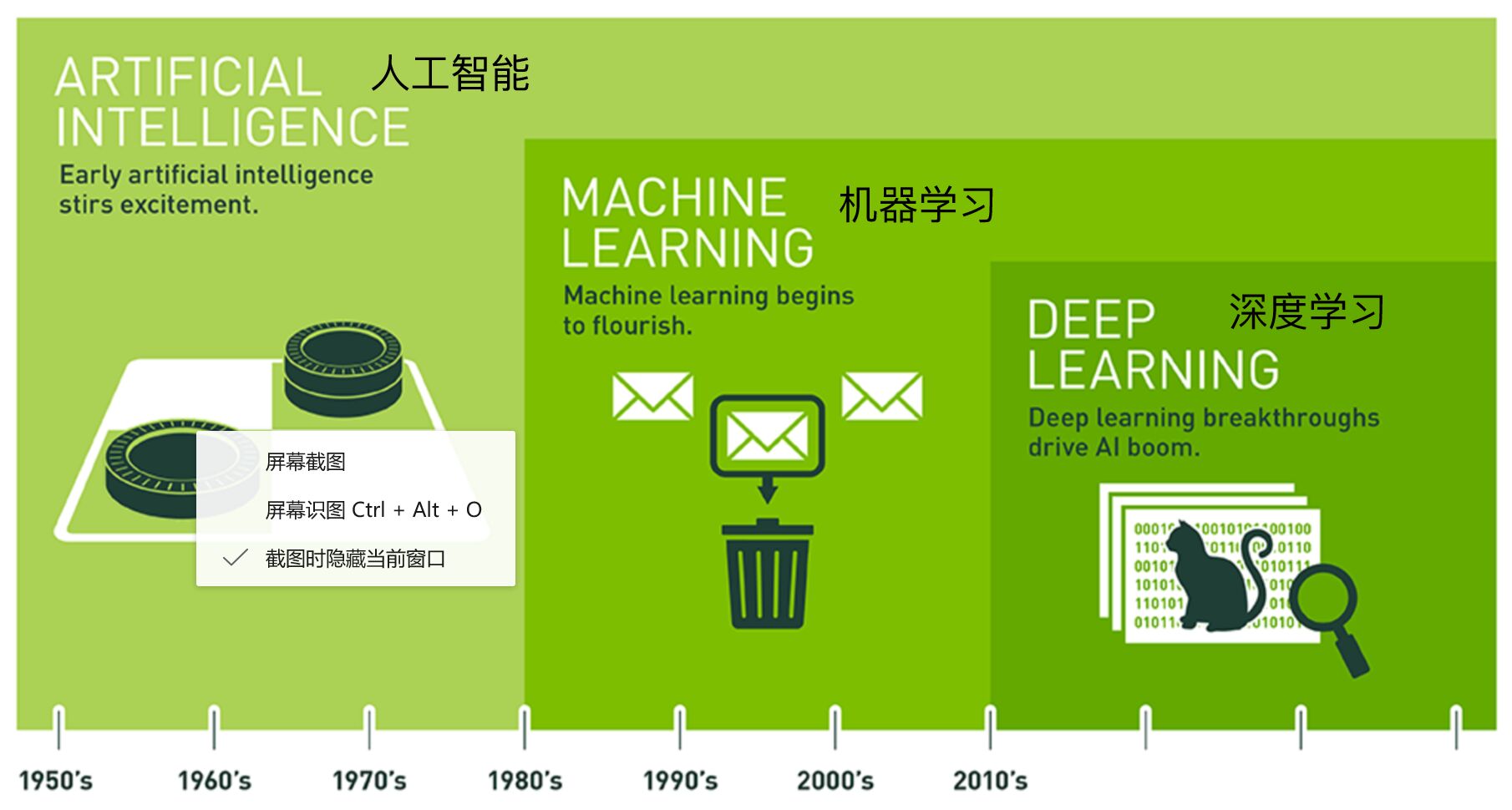
深度学习是机器学习里一个算法,就是神经网络,是比较璀璨的一个算法,开始的时候有限制,因为当时的计算机算力比较低,第二刚刚开始发展,数据量不是很大,神经网络模型复杂,需要海量的数据,现在数据量大,算力也提高,所以这个算法开始重新火起来,隐藏层很多,所以也叫深度学习,深度神经网络。
应用领域:自然语言处理(天气预报等)、计算机视觉(图像识别):人脸识别;无人车(虚拟世界中的学习);识别癌症(医生的辅助手段)、GAN(影视制作)、推荐系统(电商、电影等等,搜索引擎下一代东西)……
深度学习常用框架:……大部分都支持Python的调用,Python和机器学习结合比较好。

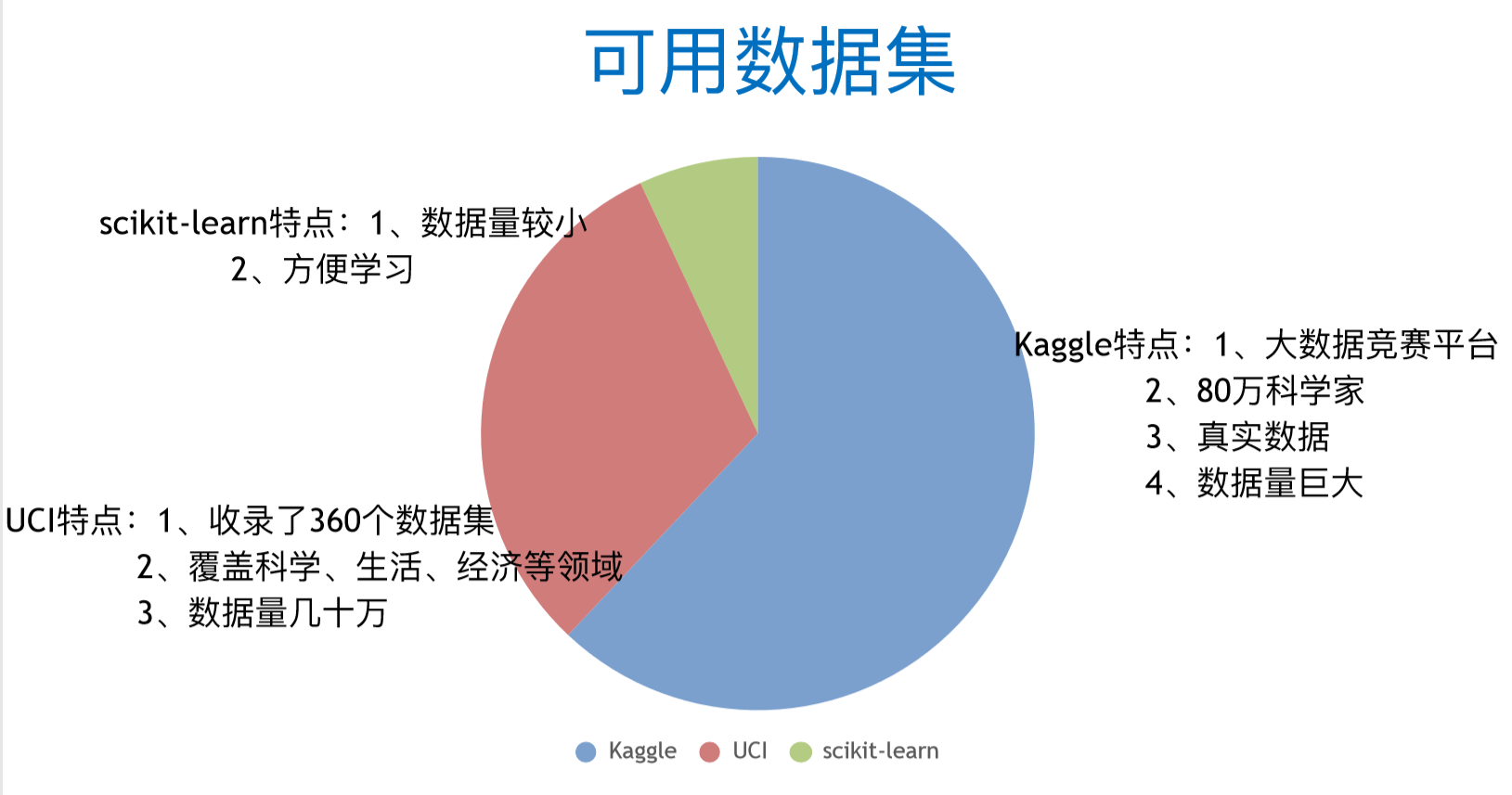
https://scikit-learn.org/stable/
需要我们掌握算法的原理,在调参的时候理解原理会有帮助(不仅仅是调包),从定性的角度理解即可,结合案例学习。
企业现状分析:行业在上升,涌入的人在增加,因此不容易入行了,比如算法工程师,要求越来越高了,但是整体行业的岗位在增加,企业对数据分析的价值认识在提高。
一、机器学习概述
1、什么是机器学习


二、数据来源与类型
企业日积月累的大量数据,尤其是互联网公司;政府掌握的各种数据;科研机构的实验数据……
大数据在中国发展的优势是中国的人多。
离散型数据和连续性数据,非常重要,理解它们的区分。最终带入模型的就是这两种数据,模型接受的是数

数据的类型会是机器学习不同问题的不同处理依据吗?
国家统计局、世界银行、联合国……
也有需要花钱的,我国的数据交易中心建立在贵阳
https://github.com/awesomedata/awesome-public-datasets
谷歌也有数据集的搜索……
常用数据集数据的结构组成:特征值+目标值。每一行数据是一个样本,这些列两部分,一部分是预测用,叫特征值,另外就是基于特征值做出的预测结果,就是目标值。