1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
2.用logiftic回归来进行实践操作,数据不限。
答:
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
防止过拟合办法:
①增加样本量;②如果数据稀疏,使用L1正则,其他情况,用L2要好,可自己尝试;③通过特征选择,剔除一些不重要的特征,从而降低模型复杂度;④检查业务逻辑,判断特征有效性,是否在用结果预测结果等。
最重要的,逻辑回归特有的防止过拟合方法:进行离散化处理,所有特征都离散化。
下图为正则化函数:
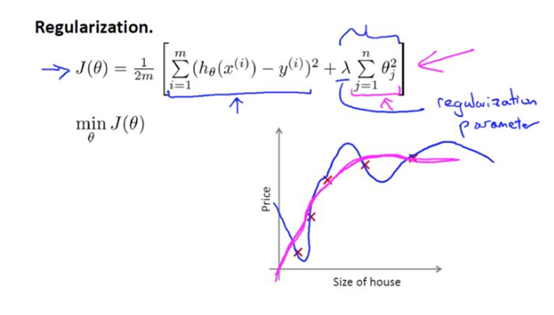
下面的这项就是一个正则化项:
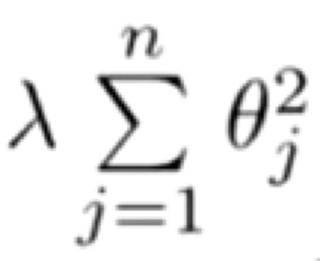
并且 λ 在这里我们称做正则化参数。
λ 要做的就是控制在两个不同的目标中的平衡关系。
第一个目标就是我们想要训练,使假设更好地拟合训练数据。我们希望假设能够很好的适应训练集。而第二个目标是我们想要保持参数值较小。(通过正则化项)
而 λ 这个正则化参数需要控制的是这两者之间的平衡,即平衡拟合训练的目标和保持参数值较小的目标。从而来保持假设的形式相对简单,来避免过度的拟合。
2.用logiftic回归来进行实践操作,数据不限。
应用葡萄酒数据,来预测葡萄酒的种类;

代码如下:
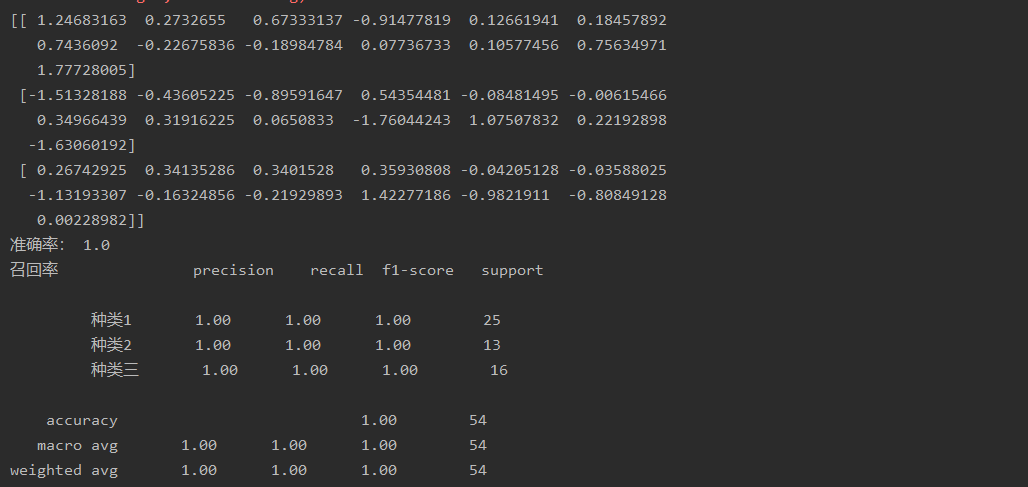
# -*- coding:utf-8 -*- from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import classification_report import numpy as np import pandas as pd from sklearn.datasets import load_wine load_wine().data.shape def logistic(): columns = ['Alcohol', 'Malic acid ', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols', 'Flavanoid', 'Nonflavanoid phenols', 'Proanthocyanins ', 'Color intensity ', 'Hue ', 'OD280/OD315 of diluted wines', 'Proline ', 'category'] #读取数据 data = pd.read_csv(r"C:Users25186PycharmProjects ask1code2020-04-26datawine_data.csv",names=columns) print(data) #缺失值处理 data = data.dropna(axis=0) #数据分割 x_train,x_test,y_train,y_test = train_test_split(data[columns[0:13]],data[columns[13]],test_size=0.3) # 进行标准化处理 std = StandardScaler() x_train = std.fit_transform(x_train) x_test = std.transform(x_test) #预测回归模型 LR_model = LogisticRegression() LR_model.fit(x_train,y_train) y_pre = LR_model.predict(x_test) print(LR_model.coef_) print("准确率:",LR_model.score(x_test,y_test)) print("召回率",classification_report(y_test,y_pre,target_names=["种类1","种类2","种类三"])) if __name__ == '__main__': logistic()
运行截图: