概述
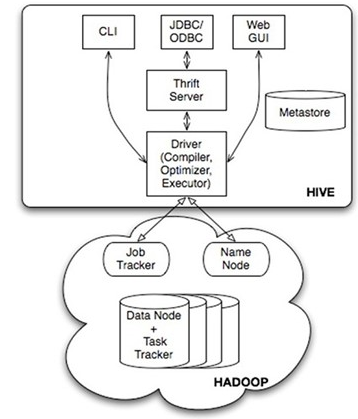
Hive 将作为我日后工作主要使用的工具,这里分享一些相关的技术。我想通过讲解hive体系结构来建立基础。这个部分非常重要,因为接下来的文章中我们会以这些概念来加深我们对HIve的认识。当我们执行一个查询时,在中最重要的组件有哪些,下面这张图片可以给大家一个概观的认识。
用户接口
Hive 自带以下几种用户接口。 CLI 就是Shell命令行JDBC/ODBC 是 Hive 的Java接口,与使用传统数据库JDBC的方式类似,WebGUI HWI 简单的网页界面,通过浏览器访问,还有JDBC,ODBC 以及Thrift服务器,这个后续会单独说明
命令执行
所有的命令和查询都会进入到Driver,通过这个模块进行解析编译,对需求的计算进行优化。然后按照指定的步骤执行(通常是启动多个MapReduce任务(JOB)来执行)。当需要启动 MapReduce任务(job)时,HIVE 本身不会生成Java MapReduve算法程序。相反,Hive通过一个表示“JOB执行计划”的。XML文件驱动执行内置的、原生的Mapper和Reducer模块。换句话说,这些通用的模块函数类似于微型的语言翻译程序,二驱动计算的“语言”是以XML形式编码的。Hive 通过和JobTracker通信来初始化MapReduve任务(job),而不必部署在JobTracker所在的管理节点上执行。要处理的数据文件是存储在HDFS中的,而HDFS是由NameNode进行管理的。
元数据
Metastore是一个独立的关系型数据库,通常使用MYSQL。Hive 会在其中保存表模式和其他系统元数据. 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等