复制是Redis集群的基础,Redis主从节点在复制的时候即使从节点因为网络分区暂时无法继续复制,主节点也会继续工作,因此根据CAP理论Redis的集群符合A可用性,不符合C一致性。当网络分区恢复后从节点会继续复制,从而实现最终一致性。
以2.8版本为分水岭,Redis复制有两种实现。
15.1 旧版复制功能的实现
分为同步(sync)和命令传播(command propagate)两个过程,两个过程以master收到slave的slaveof指令的时间点为分界线。
- 主节点收到sync指令时,会对收到指令这个时间点之前的数据生成RDB快照。
- 主节点开始生成RDB快照、主节点发送RDB快照之间的主节点执行的指令会记录在buffer中。
- 从节点收到RDB快照、buffer并完成恢复主节点的数据后,开始进入命令传播阶段。
15.1.1 同步
- slaver执行slaverof指令时,会向master发送sync指令
- master收到sync后执行BGSAVE,在后台生成一个RDB文件
- 在执行BGSAVE同时用buffer记录在此期间执行的所有修改master数据的命令
- master发送RDB给slaver,slaver利用RDB同步数据
- master发送buffer给slaver,slaver利用buffer继续同步数据
整个同步过程slaver共收到两个master传来的数据:RDB文件和buffer
15.1.2 命令传播
master继续执行会造成主从不一致,所以主节点需要把命令传播给slaver来维护一致性。
15.2 旧版复制功能的缺陷
旧版的复制分为两种情况,这两种情况的划分不是根据复制的不同阶段,而是根据主从节点的通信状况即是否发生网络分区来的。
- 初次复制,slaver执行slaverof
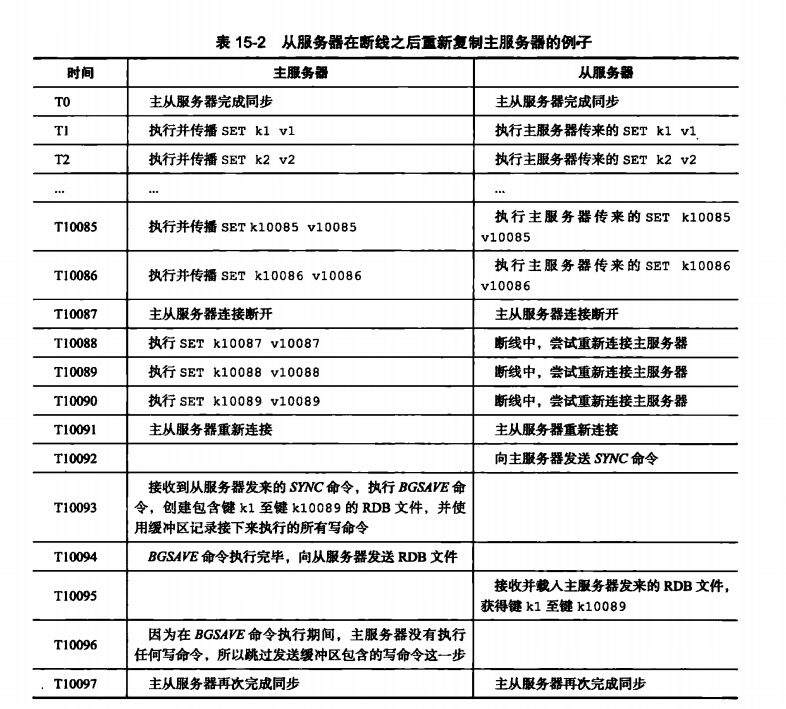
- 断线后重复制,处于命令传播阶段的主从服务器因为网络原因中断复制,此时主服务器继续响应请求,一段时间后从服务器重新连上主服务器,并继续复制。
当t10091时刻从服务器再次连上主服务器时,会发送一条sync指令,该指令会把t10091时刻之前主服务器所有数据生成RDB文件并传送过来,虽然这个过程并不是必须的,因为从服务器上有t10087前的所有数据。这种一旦断线重连就再次发送sync的策略带来的效率十分低下,因为需要复制的数据仅仅是t10087到t10091之间的数据,而且从节点从RDB中恢复数据十分的耗时。
而且sync是一个非常耗费资源的操作,资源耗费体现在三个方面
- 主服务器执行BGSAVA,会消耗CPU和带来大量的IO操作。
- 传输RDB文件耗费网络带宽。
- 从服务器恢复RDB文件的时候是阻塞的。
15.3 新版复制功能的实现
使用psync代替原有sync,p指的是partial部分。服务器断线后,只复制断线这一阶段没有同步的数据,解决了一旦断线就要全部同步的弊端。
15.4 部分重同步的实现
部分重同步针对命令传播阶段,在RDB同步阶段和旧版本相同。部分重同步依赖复制积压缓冲区、复制偏移量、服务器运行ID来实现。
在命令传播阶段,主节点维护一个被称为复制积压缓冲区的缓存,该缓存是一个固定长度的队列。主节点向从阶段每传播一个命令都会把该命令写到缓存区里,并且缓存区里每一个命令都有一个唯一的偏移量。主节点每发送N个字节的命令,就会有N个字节的命令写入缓存,同样从节点没收到N个命令,从节点的复制偏移量也会增大N。在理想的情况下,主从节点的复制偏移量应该是一直相等的。当主从节点断开连接并经过一段时间重新连上,从节点会把自己的复制偏移量发送给主节点,主节点会把收到的从节点发来的复制偏移量和自己维护的换缓冲区中的命令偏移量对比,如果收到的复制偏移量对应的命令在缓存区内,则重发该偏移量之后的命令。如果不在就执行一次全量同步。
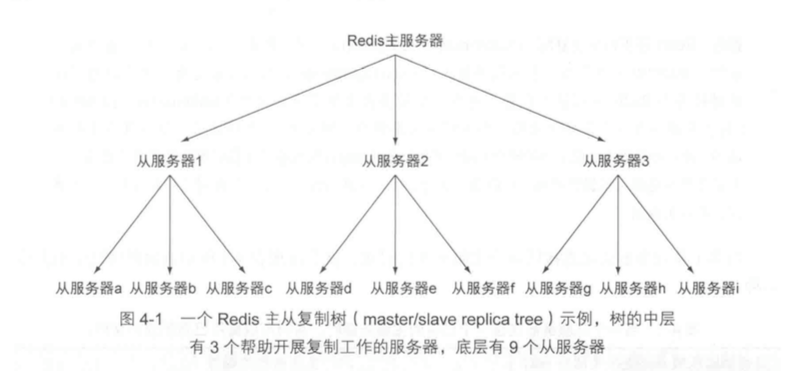
根据主从复制的特点,可以把Redis集群的拓扑结构分为两种:1、树状 2、一主多从。当Redis集群的写操作比较多时,主节点除了完成正常的业务写之外,还需要把命令传播给所有的从节点,如果采取一主多从的拓扑结构,会给主节点带来过大的压力,此时应该采用树状拓扑结构。但是从服务器再同步自己的从节点时,会断开和主节点的连接,并且在同步完成后恢复和主节点的连接,这种树状结构会造成一定的延迟。