How can we see a histogram of movies on IMDB with a particular rating? Or how much movies grossed at the box office each month? Or how many movies there are of each genre? These are examples of data aggregation questions, and this lesson will teach us how to answer them.
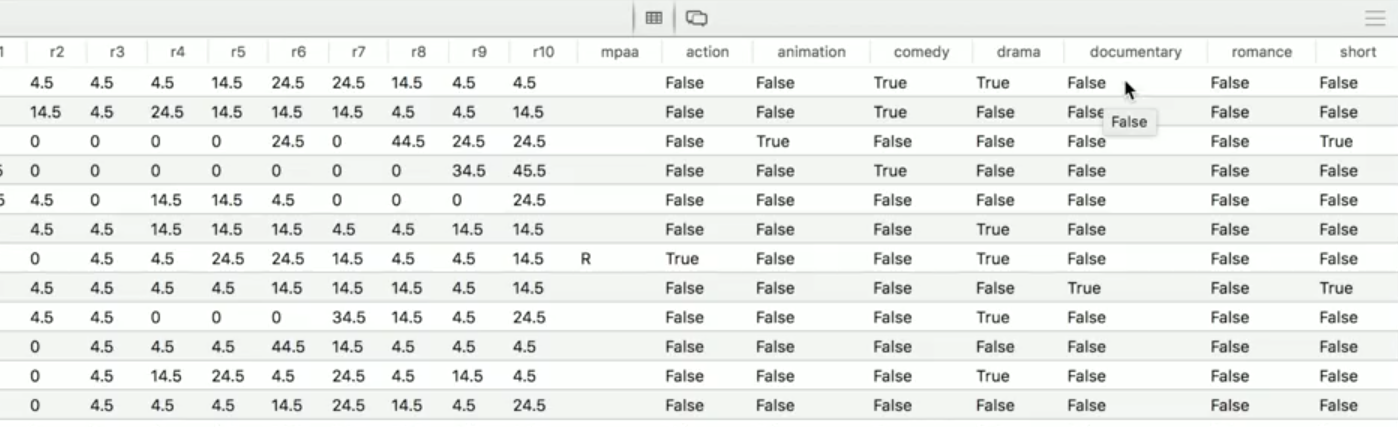
In the table we have 'action', 'animation'... 'short' categories. They all use 'true' of 'false'.
What if we want to use those by its categoreis not just ture of false?
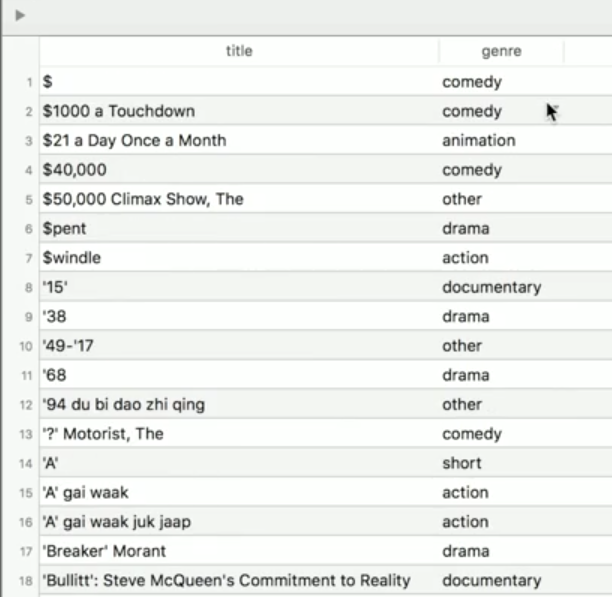
We can use 'CASE' in Postgres.
SELECT CASE WHEN action=true THEN 'action' WHEN animation=true THEN 'animation' WHEN comedy=true THEN 'comedy' WHEN drama=true THEN 'drama' WHEN short=true THEN 'short' ELSE 'other' END AS genre, title FROM movies LIMIT 100
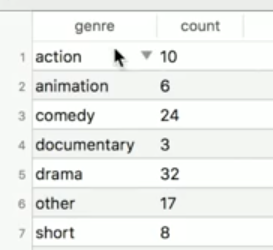
And now we want to get "how many movies for each category" from previous result.
What we can do is using "GROUP BY" and "WITH":
WITH genres AS( SELECT CASE WHEN action=true THEN 'action' WHEN animation=true THEN 'animation' WHEN comedy=true THEN 'comedy' WHEN drama=true THEN 'drama' WHEN short=true THEN 'short' ELSE 'other' END AS genre, title FROM movies LIMIT 100 ) SELECT genre, COUNT(*) FROM genres GROUP BY genre;