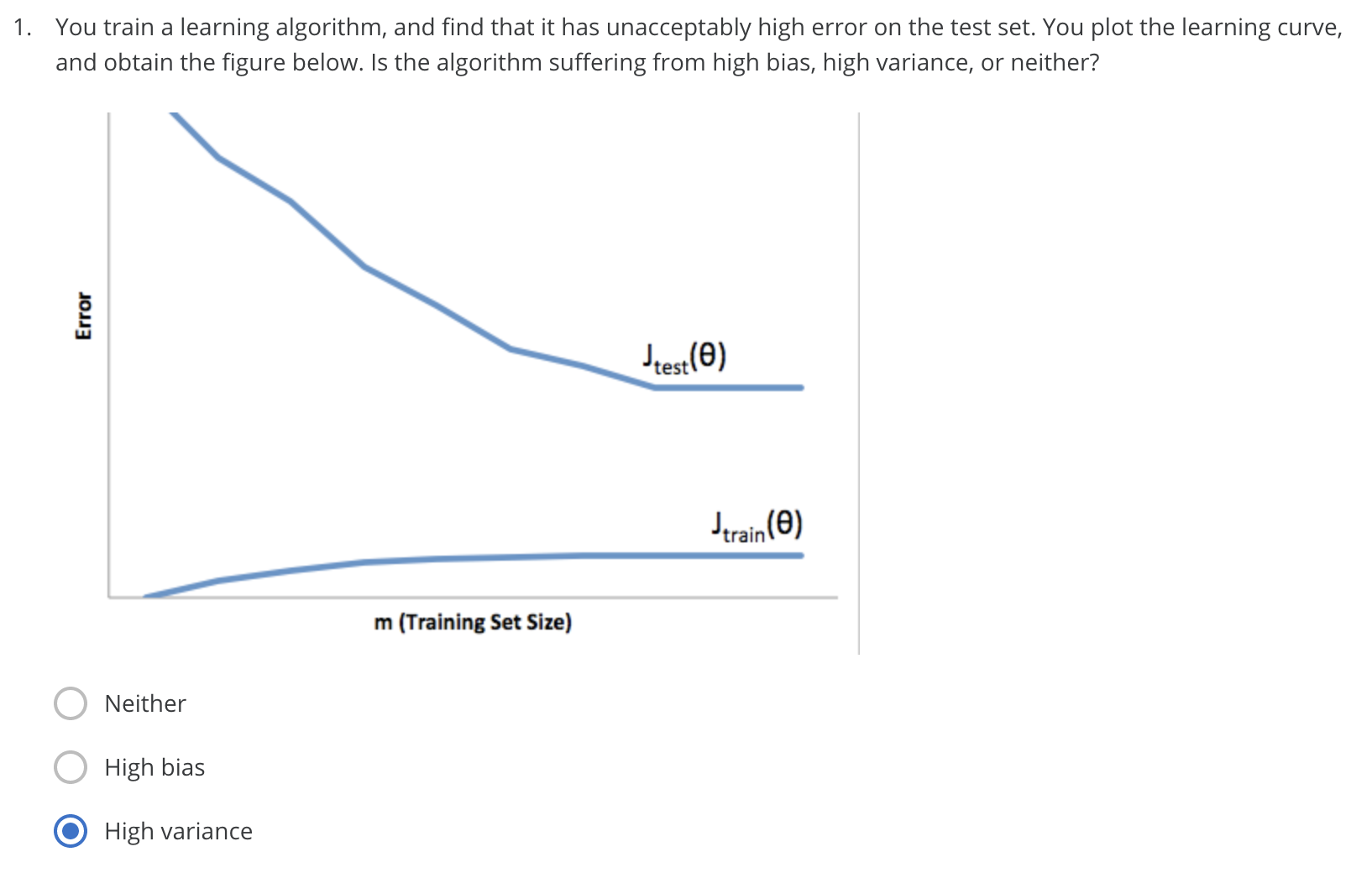
This learning curve shows high error on the test sets but comparatively low error on training set, so the algorithm is suffering from high variance.
The gap in errors between training and test suggests a high variance problem in which the algorithm has overfit the training set. Adding more training data will increase the complexity of the training set and help with the variance problem.
The gap in errors between training and test suggests a high variance problem in which the algorithm has overfit the training set. Reducing the feature set will ameliorate the overfitting and help with the variance problem

The poor performance on both the training and test sets suggests a high bias problem. Adding more complex features will increase the complexity of the hypothesis, thereby improving the fit to both the train and test data.
Decreasing the regularization parameter will improve the high bias problem and may improve the performance on the training set.

You should not use the test set to choose the regularization parameter, as you will then have an artificially low value for test error and it will not give a good estimate of generalization error.
You should not use training error to choose the regularization parameter, as you can always improve training error by using less regularization (a smaller value of ). But too small of a value will not generalize well onthe test set.
The cross validation lets us find the “just right” setting of the regularization parameter given the fixed model parameters learned from the training set.
The learning algorithm finds parameters to minimize training set error, so the performance should be better on the training set than the test set.
