<dependency> <groupId>com.janeluo</groupId> <artifactId>ikanalyzer</artifactId> <version>2012_u6</version> </dependency>
首先引入 ikanalyzer相关jar包
/** * @Description: * @Author: lizhang * @CreateDate: 2018/7/31 22:35 * @UpdateDate: 2018/7/31 22:35 * @Version: 1.0 */ import org.wltea.analyzer.core.IKSegmenter; import org.wltea.analyzer.core.Lexeme; import java.io.IOException; import java.io.StringReader; import java.util.*; public class Test { /** * 对语句进行分词 * @param text 语句 * @return 分词后的集合 * @throws IOException */ private static Map segment(String text) throws IOException { Map<String,Integer> map = new HashMap<String,Integer>(); StringReader re = new StringReader(text);
IKSegmenter ik = new IKSegmenter(re, false);//true 使用smart分词,false使用最小颗粒分词
Lexeme lex; while ((lex = ik.next()) != null) { if(lex.getLexemeText().length()>1){ if(map.containsKey(lex.getLexemeText())){ map.put(lex.getLexemeText(),map.get(lex.getLexemeText())+1); }else{ map.put(lex.getLexemeText(),1); } } } return map; } public static void main(String[] args) throws IOException { Map<String,Integer> map = segment("中国,中国,我爱你"); System.out.println(map.toString()); } }
输出结果:
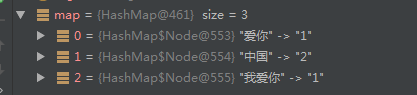
分词Utl:
