Chapter ONE 统计学习及监督学习概论
统计学习是概率论,统计学,信息论,计算理论,最优化理论及计算机科学等多个领域的交叉学科
统计学习由监督学习,无监督学习和强化学习等组成。有时还包括半监督学习和主动学习。
统计学习三要素:模型,策略和算法。
1.监督学习
从标注数据中学习预测模型的机器学习问题。
输入空间和输出空间
每个具体的输入是一个实例(instance),通常由特征向量(feature vector)表示。
所有特征向量存在的空间为特征空间。
监督学习从训练数据集合中学习模型,对测试数据进行预测。
联合概率分布
监督学习假设输入与输出的随机变量X和Y遵循联合概率分布P(X,Y)。P(X,Y)表示分布函数,或者分布密度函数。
假设空间
模型属于由输入空间到输出空间的映射的集合,这个集合就是假设空间(hypothesis space)
监督学习的模型可以是概率模型或者非概率模型
由条件概率分布P(Y|X)或决策函数(decision function)Y=f(X)表示。
问题的形式化
监督学习由学习和预测两个过程
输入x_N+1,由模型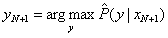
或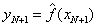
给出相应的输出y_N+1
在监督学习中,假设训练数据与测试数据是依照联合概率分布P(X,Y)独立同分布产生的
2.无监督学习
无监督学习是从无标注数据中学习预测模型的机器学习。
预测模型表示数据的类别、转换或者概率
3.强化学习(reinforcement learning)
假设智能系统与环境的互动基于马尔科夫决策过程,智能系统观测到的是与环境互动得到的数据序列。强化学习的本质是学习最优的序贯决策。
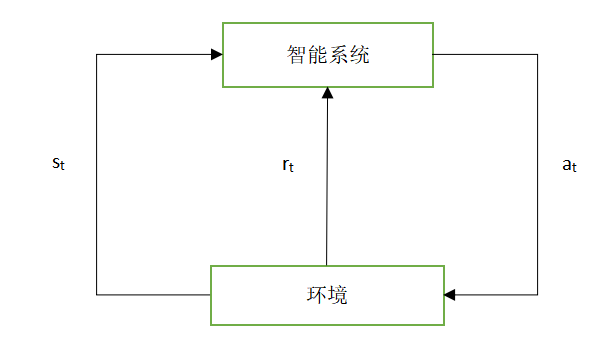
强化学习的马尔科夫决策过程是状态,奖励,动作序列上的随机过程,由五元组 组成
S是有限状态(state)的集合
A是有限动作(action)的集合
P是状态转移概率(transition probability)函数
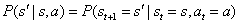
r是奖励函数(reward function):
γ是衰减系数(discount factor):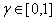
价值函数(value function)或状态价值函数(state value function)定义为策略π从某一个状态s开始的长期累积奖励的数学期望:

动作价值函数(action value function)定义为策略π的从某一个状态s和动作a开始的长期累积奖励的数学期望:

强化学习的目标是在所有可能的策略中选出价值函数最大的策略
强化学习方法中有基于策略的,基于价值的,这两者属于无模型的方法,还有模型的方法,试图直接学习马尔科夫决策过程的模型,包括转移概率函数和奖励函数
4.半监督学习与主动学习
半监督学习:利用标注数据和未标注数据学习预测模型的机器学习问题
主动学习:目标是找出对学习最有帮助的实例让教师标注,以最小的标注代价,达到较好的学习效果。