1 爬虫,爬虫攻防
2 下载html
3 xpath解析html,获取数据和深度抓取(和正则匹配)
4 多线程抓取
熟悉http协议
提供两个方法Post和Get
public static string HttpGet(string url, Encoding encoding = null, Dictionary<string,string> headDic=null) { string html = string.Empty; try { HttpWebRequest request = HttpWebRequest.Create(url) as HttpWebRequest;//模拟请求 request.Timeout = 30 * 1000; request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36"; request.ContentType = "text/html; charset=utf-8"; if (headDic != null) { foreach (var item in headDic) { request.Headers.Add(item.Key, item.Value); } } if(encoding==null) encoding = Encoding.UTF8; // 如果是乱码就改成 utf-8 / GB2312 else encoding=Encoding.GetEncoding("GB2312"); using (HttpWebResponse response = request.GetResponse() as HttpWebResponse) { if (response.StatusCode != HttpStatusCode.OK) { log.Warn(string.Format("抓取{0}地址返回失败,response.StatusCode为{1}", url, response.StatusCode)); } else { try { StreamReader sr = new StreamReader(response.GetResponseStream(), encoding); html = sr.ReadToEnd();//读取数据 sr.Close(); } catch (Exception ex) { log.Error(string.Format("DownloadHtml抓取{0}保存失败", url), ex); html = null; } } } } catch (WebException ex) { if (ex.Message.Equals("远程服务器返回错误: (306)。")) { log.Error("远程服务器返回错误: (306)。", ex); return null; } } catch (Exception ex) { log.Error(string.Format("DownloadHtml抓取{0}出现异常", url), ex); html = null; } return html; }
/// <summary> /// Post 调用借口 /// </summary> /// <param name="url">接口地址</param> /// <param name="value">接口参数</param> /// <returns></returns> public static string HttpPost(string url, string value) { string param = value; Stream stream = null; byte[] postData = Encoding.UTF8.GetBytes(param); try { HttpWebRequest myRequest = (HttpWebRequest)WebRequest.Create(url); myRequest.Method = "POST"; myRequest.ContentType = "application/x-www-form-urlencoded"; myRequest.ContentLength = postData.Length; stream = myRequest.GetRequestStream(); stream.Write(postData, 0, postData.Length); HttpWebResponse myResponse = (HttpWebResponse)myRequest.GetResponse(); if (myResponse.StatusCode == HttpStatusCode.OK) { StreamReader sr = new StreamReader(myResponse.GetResponseStream(), Encoding.UTF8); string rs = sr.ReadToEnd().Trim(); sr.Close(); return rs; } else { return "失败:Status:" + myResponse.StatusCode.ToString(); } } catch (Exception ex) { return "失败:ex:" + ex.ToString(); } finally { if (stream != null) { stream.Close(); stream.Dispose(); } } }
下载Html
StreamWriter sw = new StreamWriter("路径.txt", true, Encoding.GetEncoding("utf-8")); sw.Write("爬取的html字符串"); sw.Close();
xpath
http://www.cnblogs.com/zhaozhan/archive/2009/09/09/1563617.html
http://www.cnblogs.com/zhaozhan/archive/2009/09/09/1563679.html
http://www.cnblogs.com/zhaozhan/archive/2009/09/10/1563703.html
正则匹配
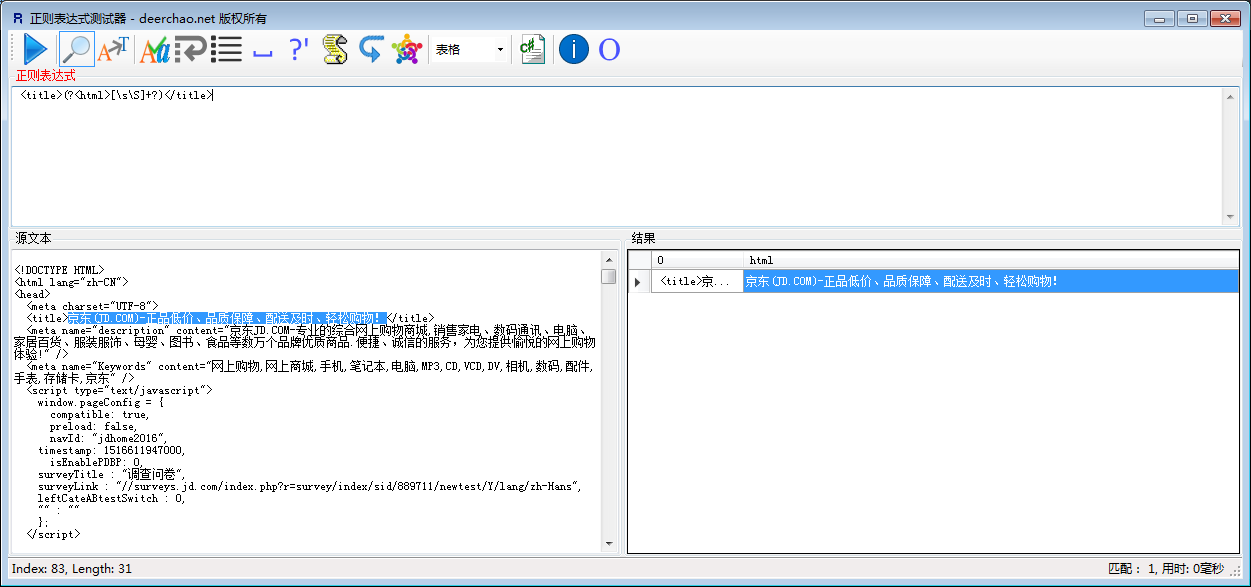
目前使用起来最好用的正则
<title>(?<html>[sS]+?)</title> 意思是匹配 <title> *********</title>标签里面的任意字符串
Regex reTitle = new Regex(@"<title>(?<html>[sS]+?)</title>"/>"); string title = reTitle.Match(html).Groups["html"].Value;
多个选择
Regex rgInfo = new Regex(@"<td align=""left"">(?<company>[^<>]+)</td><td align=""center"">(?<id>[dA-Z]+)</td><td align=""center"">(?<cat>[^<>]+)</td><td align=""center"">(?<grade>[A-Z]+)</td><td align=""center"">(?<date>[^s&]*)"); MatchCollection mchInfos = rgInfo.Matches(strHtml); foreach (Match m in mchInfos) { string strCompany = m.Groups["company"].Value; string strId = m.Groups["id"].Value; string strCat = m.Groups["cat"].Value.Replace(" ", ""); string grade = m.Groups["grade"].Value; string date = m.Groups["date"].Value; }
多线程
List<Task> taskList = new List<Task>(); TaskFactory taskFactory = new TaskFactory(); for(int i=0;i<100;i++) { taskList.Add(taskFactory.StartNew(Crawler));//将一个执行Crawler方法的线程放到集合里面,创建并启动 任务 if (taskList.Count > 15) //线程池启动15个线程 { taskList = taskList.Where(t => !t.IsCompleted && !t.IsCanceled && !t.IsFaulted).ToList(); Task.WaitAny(taskList.ToArray());//有线程执行完毕 } } Task.WaitAll(taskList.ToArray());//100个线程全部执行完成 Console.WriteLine("抓取全部完成 - -", DateTime.Now);
该文档只是自己记录,纯属记事本