本章的内容是开发一个简单的、多用户数据库的C函数库。调用此函数库提供的C语言函数,其他程序可以读取和存储数据库中的记录。绝大部分商用数据库函数库提供多进程同时更新数据库所需要的并发控制,采用建议记录锁、B+树、动态散列实现数据库。
1、函数库
开发类似ndbm函数库,增加了并发控制机制,从而允许多进程同时更新同一数据库。函数接口如下:
1 #include "apue_db.h"
2 DBHANDLE db_open(const char *pathname, int oflag, .../* int mode */); //返回值:若成功则返回数据库句柄,若出错则返回NULL
3 int db_close(DBHANDLE db); //关闭数据库
4 in db_store(DBHANDLE db, const char *key, const char*data, int flag); //向数据库中加条新的记录
5 char* db_fetch(DBHANDlE db, const char *key);//若成功则返回指向数据的指针,若记录没有找到则返回NULL。
6 int db_delete(DBHANDLE db, const char *key);//返回值:若成功则返回0, 若记录没有找到则返回-1。
7 void db_rewind(DBHANDLE db); //回滚到数据库第一条记录
8 char* db_nextrec(DBHANDLE db, char *key);//返回值:若成功则返回指向数据的指针,若到达数据库的结尾则返回NULL
2、实现概述
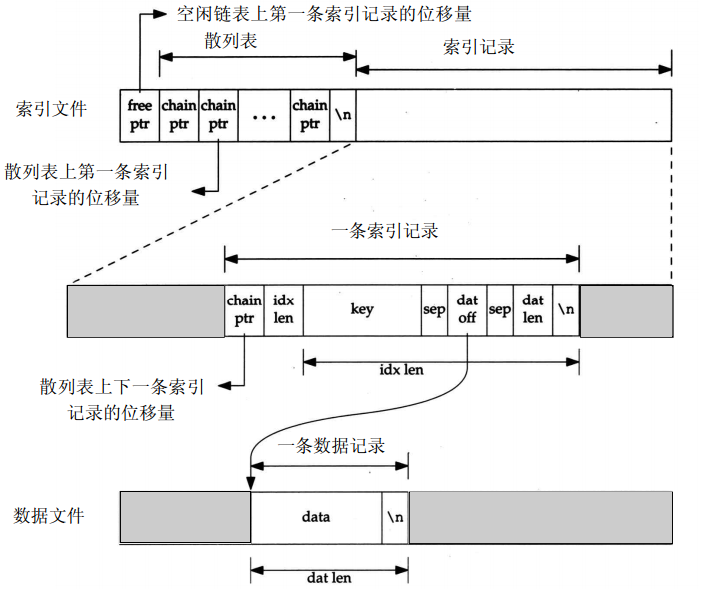
大多数访问数据库的函数库使用两个文件来存储信息:一个索引文件和一个数据文件。数据库实现结构如下图所示:
索引文件和数据文件结构
3、集中式和非集中式
(1)集中式:由一个进程作为数据库管理者,所有的数据库访问工作由此进程完成,其他进程通过IPC机制与此中心进程进行联系。
(2)非集中式:每个函数库独立申请并发控制(加锁),然后调用自己的I/O函数。调用数据库库函数执行I/O操作的用户进程是合作进程,使用字节范围锁机制实现并发访问。
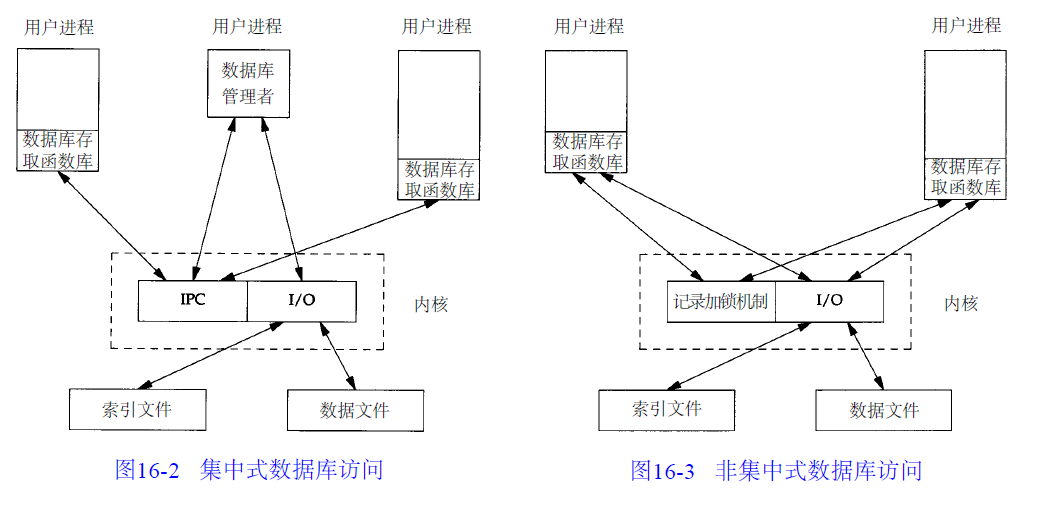
非集中式避免使用IPC机制,速度一般比集中式要快。集中式的优点是能够根据需要来对操作模式进行调整,恢复要比非集中式方法容易。
4、并发
(1)粗锁(coarse-grained locking):将索引文件和数据文件中的一个作为整个数据库的锁,并要求调用者在对数据库进行操作前必须获得这个锁。缺点是限制了最大程度的并发。
(2)细锁(fine-grained locking):要求一个读进程或写进程在操作一条记录前必须先获得此记录所在散列链的读锁或写锁。允许对一条散列链同时可以有多个读进程,而只能有一个写进程。另外,一个写进程在操作空闲区链表(如dbdelete或dbstore)前,必须获得空闲区链表的写锁。最后,当dbstore向索引文件或数据文件加一条新记录时,必须获得对应文件相应区域的写锁。