前言:今天算是见到Scrapy的第二天,之前只是偶尔查了查,对于这个框架的各种解释,我-----都-----看------不------懂----,没办法,见面就是刚。
目的:如题,试水
目标:《伯乐在线》python版(不要问我怎么老是惹伯乐,好欺负)的“实践项目”的一页的文章标题和简介,导入Mysql数据库。
配置:win7+python3.4+Scrapy1.4+phpStudy(主要用它的mysql数据库)
完成时间:2017-7-27(历时2天)
作者:羽凡
-------------------------------------------------------------------无敌的-------------------------------------------------------------------------------------------------------------------------
正文:
scrapy的安装我就不说了,有事没事问度娘。。。。
第一步:创建项目,命令:scrapy startproject bole
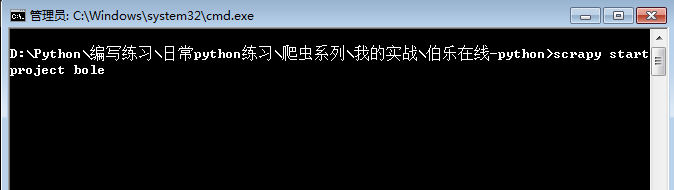
成功的话就生成了这些
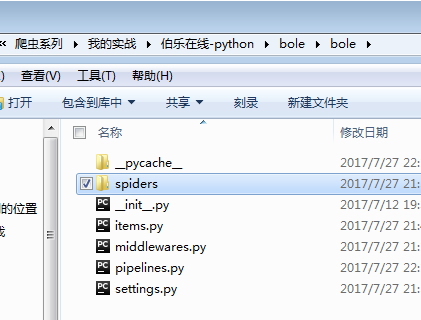
今天除了第三和第五个没用到,其他都有修改。
看看咋们的目标状态:
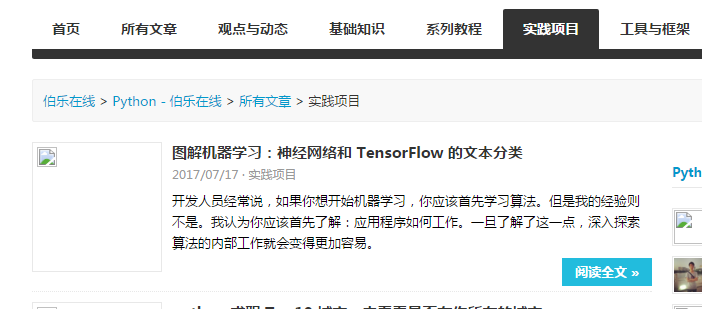
我要的是“图解机器学习。。。。”和“开发人员经常说。。。。”这两项(先简单点)
第二步:修改items.py文件
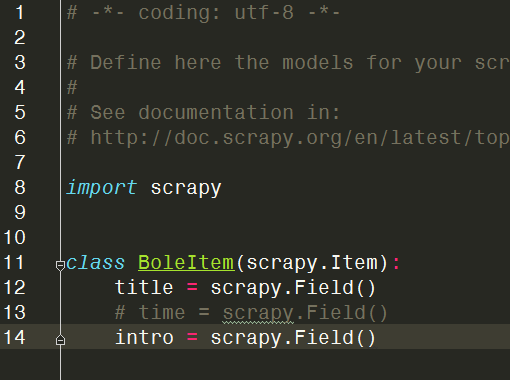
用过django的可能觉得熟悉这个东西,这就像个中转或是暂时仓库,你从网页上找到想要的东西总得放个地方吧,这里就为它们开辟了空间,这个空间在爬虫主体(spider文件夹里)会被引用(from ..items import BoleItem),空间开辟好了,items.py就改好了。
第三步:创建爬虫主体。命令:scrapy genspider -t basic Bole jobbole.com

关于命令中的有些参数我也不太清楚,genspider-生成爬虫 -t :不知道 basic:不知道 Bole:爬虫名字 jobbole.com:目标域名
该命令在spider文件夹下生成Bole.py
经过修改后的样子
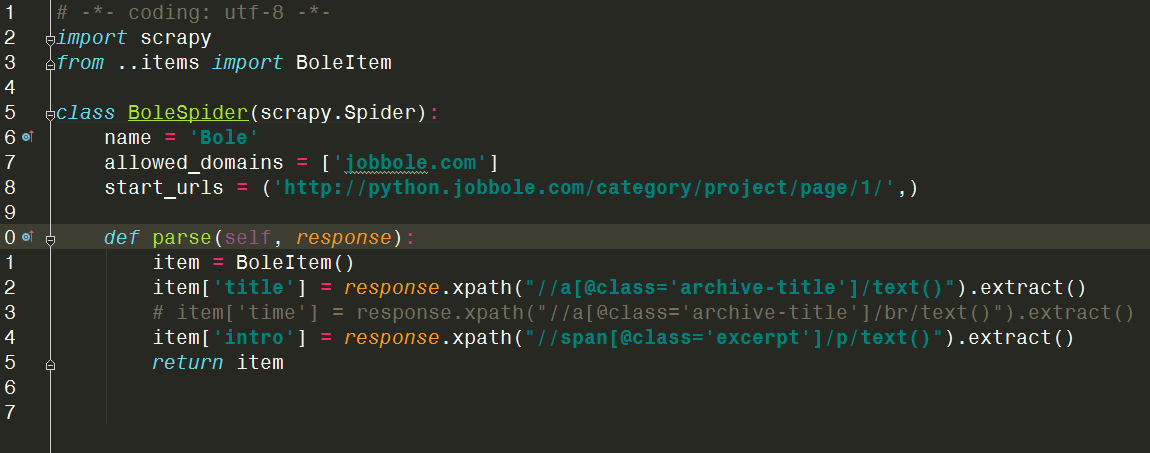
这里start_urls是第一页的网址。下面的parse函数是对返回结果的处理,我们需要的数据也是在这里产生的,这里用到了xpath来搜索数据,功能与re正则差不多,还可以看到在items.py中开辟的空间在这里用到了。(假如把return item 换成 print(item[‘title’])就可以看到抓到的标题了)
加餐第四步:数据导入mysql数据库(修改setting.py和pipelines.py文件)
先是pipelines.py:
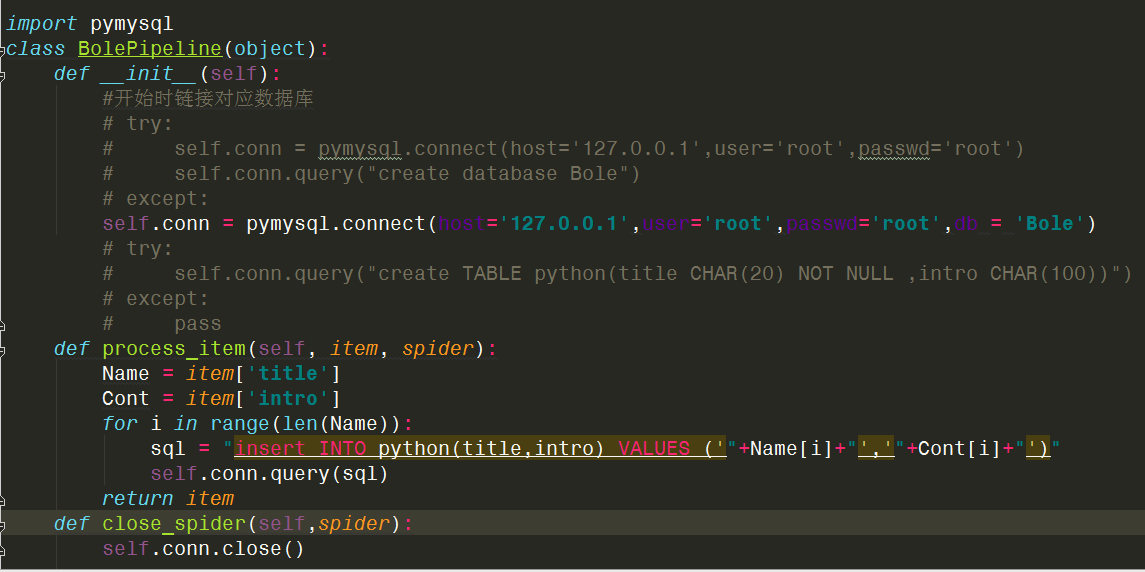
被我注释掉的是链接数据库并创建相应的库/表/项。如果你是手工用SQL来创建好的,就注释掉吧,要不然还要修改下,这里将中转的东西通过SQL指令导入数据库里了
接下来修改setting.py使上面的修改管用:
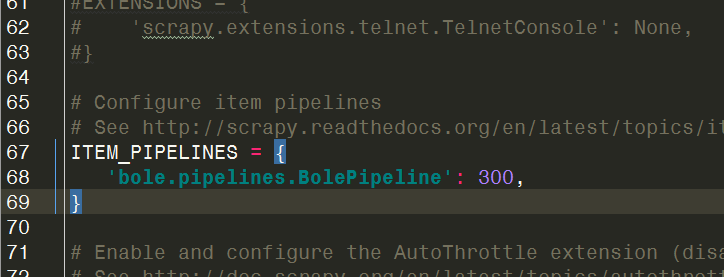
找到这行,并解除注释,就像开了水龙头。。。。
开启Mysql,运行爬虫:

--nolog是为了不打印一串日志记录,如果排查错误就不加。
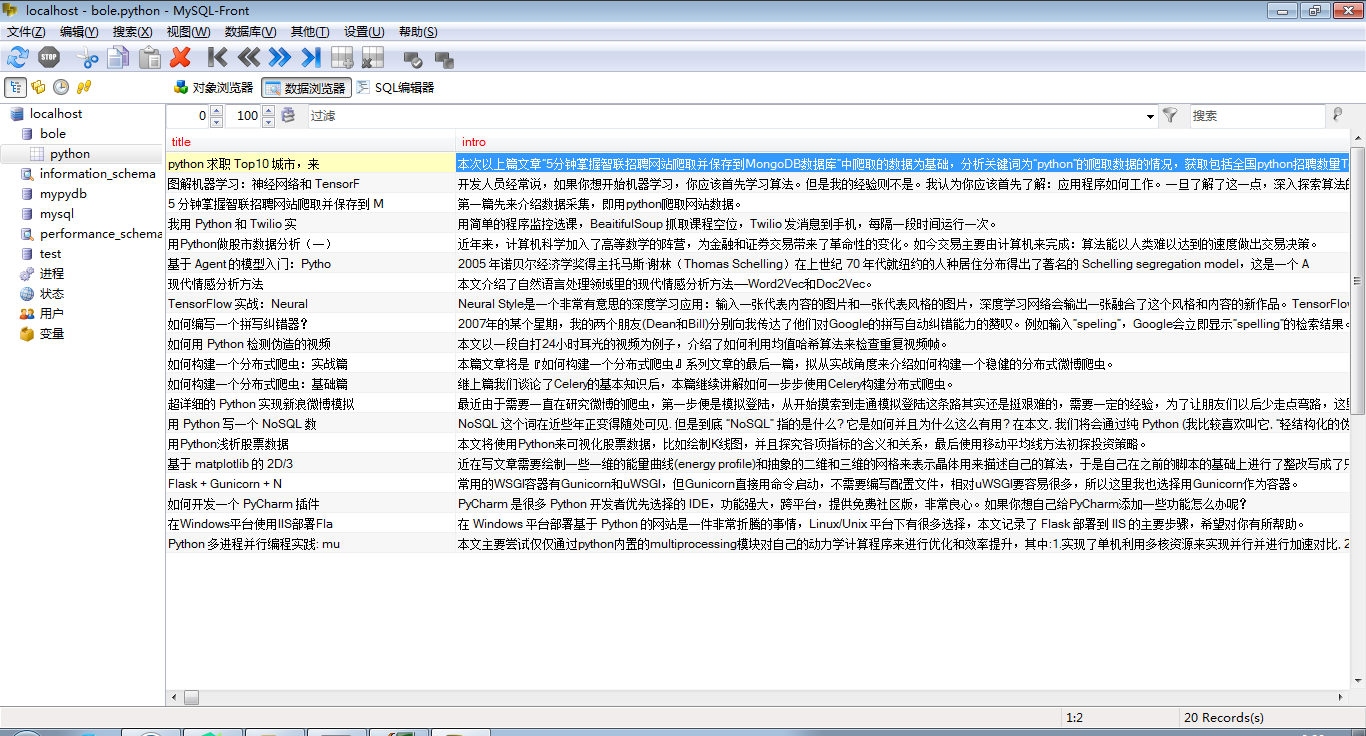
以上是结果。
-----------------------------------------------------------------------无敌的我-----------------------------------------------------------------------------------------------------------------------------------
是不是写的很水,我自己都尴尬了,没办法,才真正自学两天,明天,哦不,今天在理理思路,期待第二回早点写来。
困了,睡觉。 By:羽凡 2017-7-28-0:33