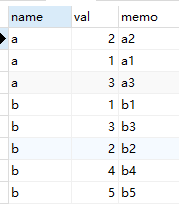
create table tb(name varchar(10),val int,memo varchar(20))
insert into tb values('a', 2, 'a2')
insert into tb values('a', 1, 'a1')
insert into tb values('a', 3, 'a3')
insert into tb values('b', 1, 'b1')
insert into tb values('b', 3, 'b3')
insert into tb values('b', 2, 'b2')
insert into tb values('b', 4, 'b4')
insert into tb values('b', 5, 'b5')
SELECT * from tb
方法1:分组中第二大的数据 思路是:先获取第二大的val,然后作为查询条件 进行关联自己,联表查询,使用linit可以获取结果中任意位置的数据
select a.* from tb a where val = (select val from tb where name = a.name ORDER BY val desc LIMIT 1,1) order by a.name
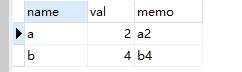
方法2:分组中第二大的数据 思路是先获取最大的值,然后进行关联自己,联表查询
SELECT a.* FROM tb a WHERE val = (SELECT MAX(val) FROM tb WHERE val < (SELECT MAX(val) from tb WHERE name = a.name) and a.name = name )
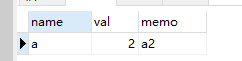
再来个简单的没有分组,获取第二大的数据
create table tb1(name varchar(10),val int,memo varchar(20))
insert into tb values('a', 2, 'a2')
insert into tb values('a', 1, 'a1')
insert into tb values('a', 3, 'a3')
SELECT * from tb1

//第二大的数据,不进行分组
SELECT a.* FROM tb1 a WHERE val = (SELECT MAX(val) FROM tb1 WHERE val < (SELECT MAX(val) from tb1))
参考:http://www.manongjc.com/article/1082.html