request的get方法
r=request.get(url)构造一个向服务器请求资源的Request对象,
返回一个包含服务器资源的Response对象。
Request对象由Request库自动生成的。
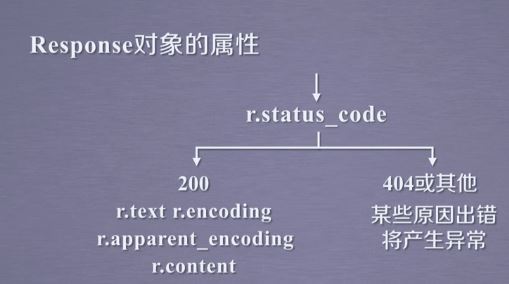
Response对象包含从服务器返回的所有相关资源
同时包含我们向服务器请求获得页面的request信息
request.get(url,params=None,**kwargs)
url:拟获取页面的url链接
params:url中的额外参数,字典或字节格式,可选
**kwargs:12个控制访问的参数
get方法源代码用request方法进行封装
request库提供了七个常用方法,除了第一个request方法是基础方法外
其他方法都是通过调用request方法来实现的
也可以这样认为:request库只由一个方法就是request方法
为了编写程序方便,提供了其他6个方法来调用request方法
request库的2个重要对象
r=requests.get(url)
使用request对象,返回response对象
response对象包含爬虫返回的全部内容
网络上的资源,他有他的编码
如果没有编码,我们将没办法用有效的解析方式使得人类可读这样的内容
r.encoding的编码方式是从Http header中charset字段获得的
如果Http header中有这样一个字段,说明我们访问的服务器对它资源的编码是有要求的
而这样的编码会获得回来存在r.encoding中
但不是所有的服务器对他的相关资源编码都是有这样的要求
如果header中不存在charset字段,则认为编码为ISO-8859-1
但是这样的编码并不能解析中文
所以Request库提供一个备选编码叫apparent_encoding
apparent_encoding做的事情是根据Http的内容部分(而不是头部分)
分析内容中出现文本的可能的编码形式
原则上来说,apparent_encoding比encoding更为准确
因为encoding并没有分析内容,他只是从header的相关字段中提取编码数
而apparent_encoding在分析内容且找到其中可能的编码
运用实例:
Python 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 17:00:18) [MSC v.1900 64 bit (AMD64)] on win32 Type "copyright", "credits" or "license()" for more information. >>> import requests >>> r = requests.get("http://www.baidu.com") >>> print(r.status_code) #在这里,如果返回的是200表示访问成功。如果不是200则出现了错误 200 >>> type(r) <class 'requests.models.Response'> >>> r.headers {'Server': 'bfe/1.0.8.18', 'Date': 'Thu, 03 May 2018 23:52:26 GMT', 'Content-Type': 'text/html', 'Last-Modified': 'Mon, 23 Jan 2017 13:27:32 GMT', 'Transfer-Encoding': 'chunked', 'Connection': 'Keep-Alive', 'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Pragma': 'no-cache', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Content-Encoding': 'gzip'} >>> r.text '<!DOCTYPE html> <!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>çx99¾åº¦ä后面不管是啥了,反正出现了乱码' #由于出现乱码,查看一下编码 >>> r.encoding 'ISO-8859-1' >>> r.apparent_encoding 'utf-8' #改一下r.encoding编码 >>> r.encoding='utf-8' >>> r.text '<!DOCTYPE html> <!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head>'乱码已修改好 >>>