机器学习方法:有监督学习,无监督学习,强化学习
有监督学习:有标签有目标
无监督学习:无标签,无目标
强化学习:过程模拟和观察进行学习。
强化学习

策略:在特定状态下应该怎么采取行动。
目标:找到最佳策略,即能够获得最大奖励的策略。
数学模型:马尔可夫决策过程(MDP)
强化学习方法形式化为MDP,MDP是序列决策算法的一般数学框架
通常将MDP表示为四元组(S,A,P,R):

S是离散状态;A可能是离散,也可能是连续的;P通常用来描述模型。
马尔可夫假设:状态不断转移,随着时间可以写成St→St+1→St+2,而在St+2这个时间段时若给定了St+1状态,那么它跟St及以前的状态是没有关系的。
策略:在马尔可夫决策过程中,最终需要求解一个策略,它是行动和状态之间的映射,分为确定性策略和随机性策略:
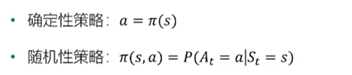
随机性:可能是一个概率取值。
确定性:非左即右。
目标:

多臂Tiger机问题(MAB):探索与利用的权衡
Tiger机有K个摇臂,每个摇臂以一定的概率吐出金币,投入硬币后只能选择其中一个摇臂,目的是通过一定的策略使自己的奖励最大,即得到更多的金币:
