7.3 Hardware Prefetching 《Speculative Execution in High Performance Computer Architectures》
本节主要介绍硬件数据预取,数据预取分为2个端,处理器端和内存端,处理器端主要在主要在L1或者L2实现预取,内存端主要在内存控制器中实现。预取算法也有3种:顺序或者步长预取(Stride and Sequential Prefetching),关联性预取(Correlation Prefetching),内容关联性预取(Content-Based Prefetching)
顺序或者步长预取(Stride and Sequential Prefetching)
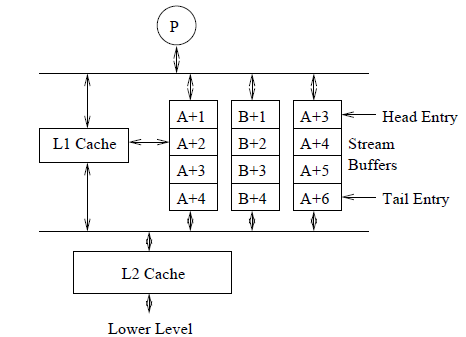
预取的规则:
1.如果请求的line在cache中,不会发生任何操作。
2.如果line没有被cache,但是在stream buffer的头部找到,line就会被启动到cache中,head会被移动到下一个。
3.如果都没有,会分配一个新的stream buffer。并且该line的预取被放入stream buffer
缺点,有可能引起途中一样的问题,有重复的stream buffer 出现原因是非单元步长的访问。
关联性预取(Correlation Prefetching)
为了解决顺序或者步长预取,引入了关联性预取,关联性预取引入了一个关联表,里面记录了某个miss之后的联系miss。当miss再次发生就回去关系表中的所有的行。
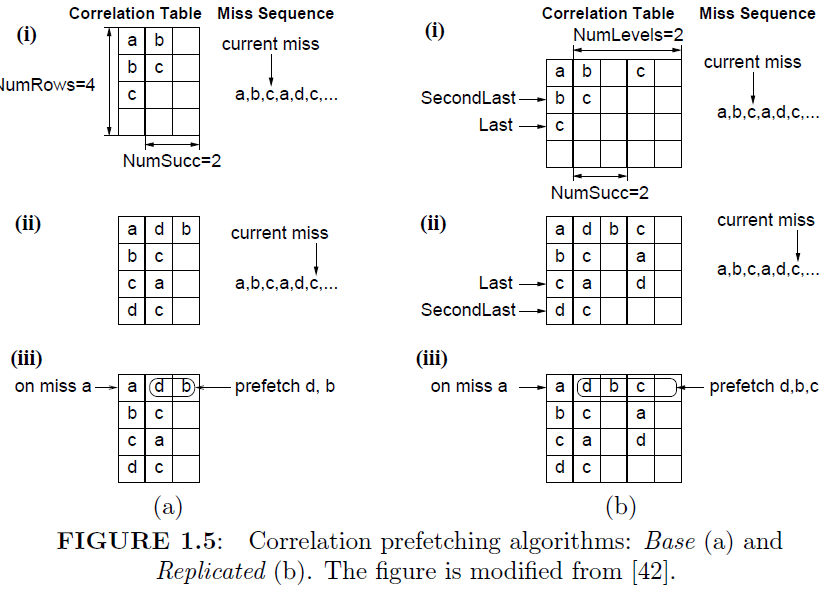
预取分为了2中1.base方式,2.Relicated方式。看图上的步骤就清楚2个的区别了。
缺点:需要大量的缓存来存这个关系表,大概需要1-2M的SRAM十分的昂贵
内容关联性预取(Content-Based Prefetching)
这种方式,是通过检查内容查看是不是指针或者地址,并且感觉马上就要被访问了,如果是就预取进来。

启发规则是根据cacheline分为多个4字节的块。块被分为了好几个段
1.比较miss地址和其他地址的compare bits,如果匹配预取的是同一个基地址的数据。
2.compare bits都是0,就检查filter bits如果非0,就是相似的地址。若compare bits都是1 filter bits 都是0 也认为是相似地址
3.align bits 要为00 才可以
缺点:预取是根据上一次的miss的内容来发送的,所以有可能会变成每个都miss的情况,间接矩阵和以下标的形式并不起作用