在学习XPath之前你应该对XML的节点,元素,属性,原子值(文本),处理指令,注释,根节点(文档节点),命名空间以及对节点间的关系如:父(Parent),子(Children),兄弟(Sibling),先辈(Ancestor),后代(Descendant)等概念有所了解。这里不在说明。
一、路径表达式语法:
- 路径 = 相对路径 | 绝对路径
- XPath路径表达式 = 步进表达式 | 相对路径 "/"步进表达式。
- 步进表达式=轴 节点测试 谓词
说明:
- 其中轴表示步进表达式选择的节点和当前上下文节点间的树状关系(层次关系),节点测试指定步进表达式选择的节点名称扩展名,谓词即相当于过滤表达式以进一步过滤细化节点集。
- 谓词可以是0个或多个。多个多个谓词用逻辑操作符and, or连接。取逻辑非用not()函数。
请看一个典型的XPath查询表达式:/messages/message//child::node()[@id=0],其中/messages/message是路径(绝对路径以"/"开始),child::是轴表示在子节点下选择,node()是节点测试表示选择所有的节点。[@id=0]是谓词,表示选择所有有属性id并且值为0的节点。
二、相对路径与绝对路径:
如果"/"处在XPath表达式开头则表示文档根元素,(表达式中间作为分隔符用以分割每一个步进表达式)如:/messages/message/subject是一种绝对路径表示法,它表明是从文档根开始查找节点。假设当前节点是在第一个message节点【/messages/message[1]】,则路径表达式subject(路径前没有"/")这种表示法称为相对路径,表明从当前节点开始查找。具体请见下面所述的"表达式上下文"。
三、使用百度首页进行实践
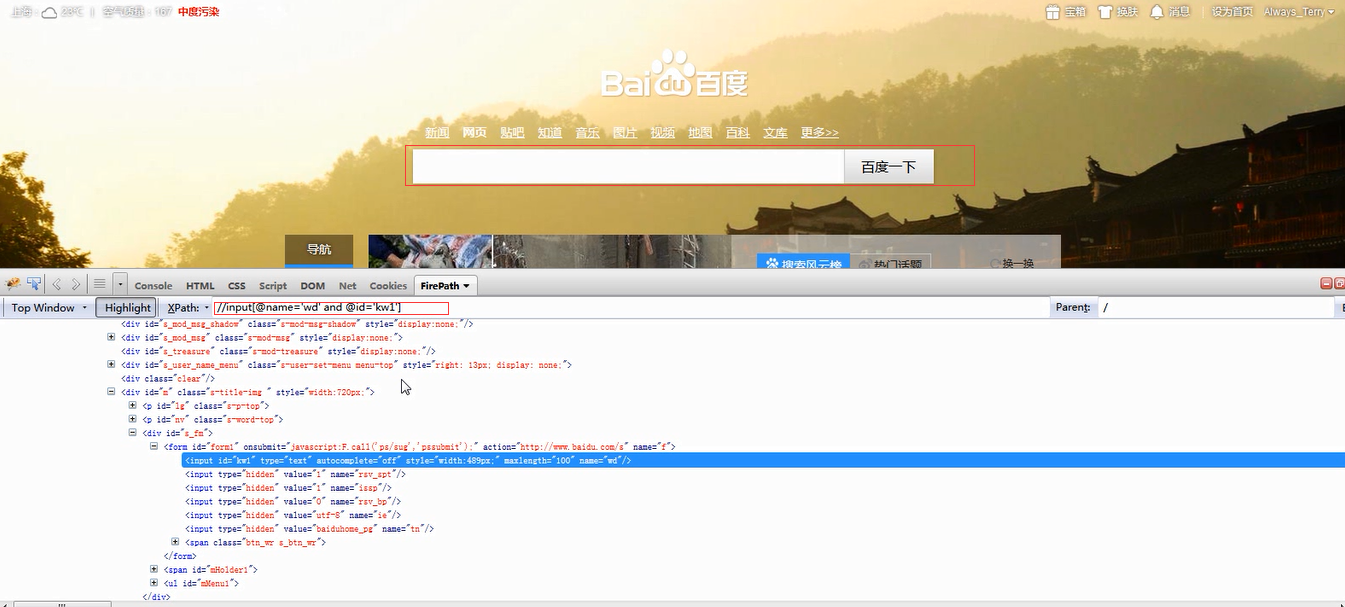
1.通过相对路径的属性值查找多个属性值使用and进行连接。
2.通过text函数进行查找,依旧可以和其他条件联合使用。记住函数是使用的()结尾
//a[text()='学术']
3.使用contains 属性值 text() 联合进行定位主要contains的方法不带等号
//a[contains(text(),'新闻') and contains(@href,'new') and @target='_blank' and text()='新闻']
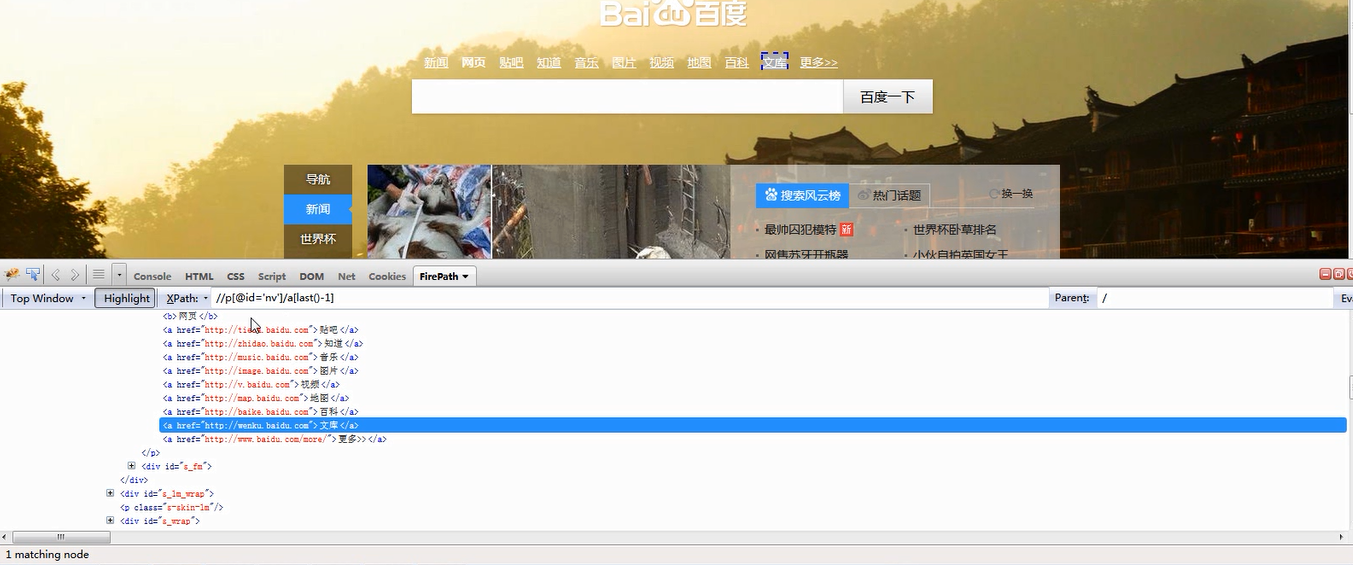
4.根据索引值进行定位使用last()函数。也可以直接赋索引值,因为标签个数有可能会变化,尽量使用函数进行加减
5使用xpath轴进行定位
|
轴名称 |
结果 |
|
ancestor |
选取当前节点的所有先辈(父、祖父等) |
|
ancestor-or-self |
选取当前节点的所有先辈(父、祖父等)以及当前节点本身 |
|
attribute |
选取当前节点的所有属性 |
|
child |
选取当前节点的所有子元素。 |
|
descendant |
选取当前节点的所有后代元素(子、孙等)。 |
|
descendant-or-self |
选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
|
following |
选取文档中当前节点的结束标签之后的所有节点。 |
|
namespace |
选取当前节点的所有命名空间节点 |
|
parent |
选取当前节点的父节点。 |
|
preceding |
直到所有这个节点的父辈节点,顺序选择每个父辈节点前的所有同级节点 |
|
preceding-sibling |
选取当前节点之前的所有同级节点。 |
|
self |
选取当前节点。 |
ancestor节点使用方法(descendant的使用方法也是如此):
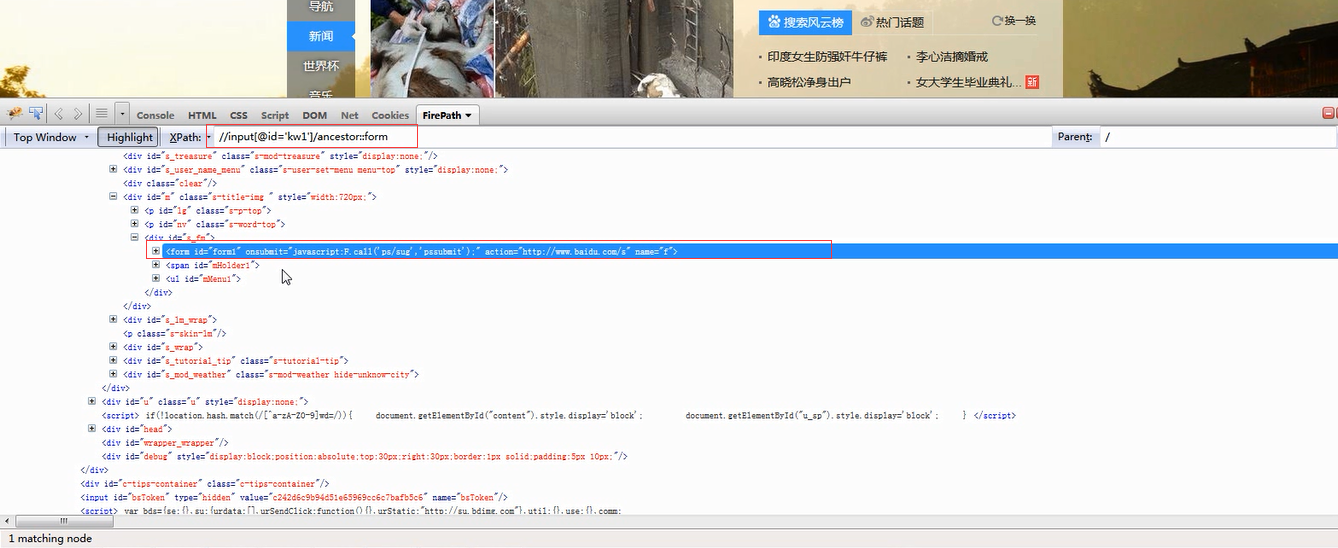
1.使用当前节点定位,找寻先辈的标签。
2.将祖辈是某个节点作为当前节点唯一祖辈
precedi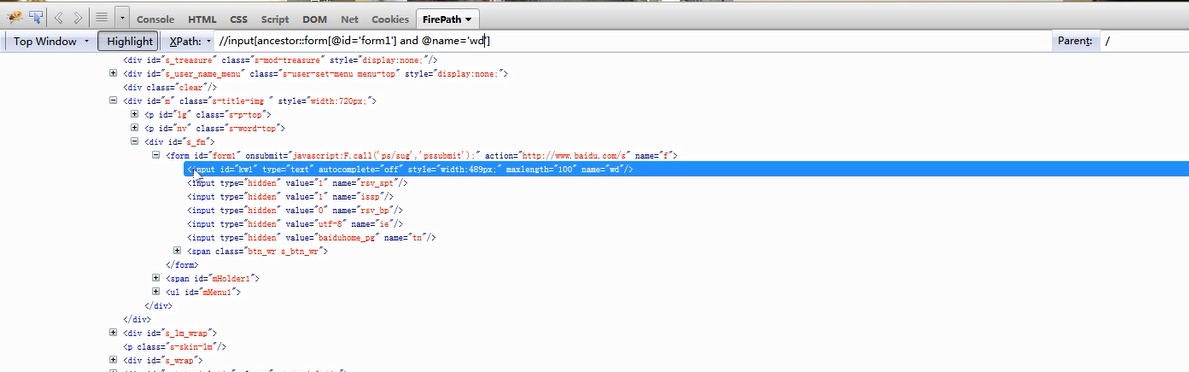 ng-sibling(following-sibling用法一致)
ng-sibling(following-sibling用法一致)
找到同级节点标签为input,属性为name=ie 并且,想要查找的节点的标签是input,name属性是tn
//input[preceding-sibling::input[@name='ie'] and @name='tn']
找到input标签属性name=ie的同级节点下input下属性name为f
//input[@name='ie']/preceding-sibling::input[@name='f']
parent和child用法类似,代表当前节点的父节点和子节点
其实看过好多博客,有人说xpath定位比较慢,用了这么长时间,感觉速度还好啊,个人感觉慢是相对的,1ms和50ms对于肉眼来说可以忽略不计的。