TextBoxes
论文关键idea
本文和SegLink一样,也是在SSD的基础上进行改进的.相比SSD做了以下的改进:
- 修改了default box的apect ratio,分别为[1 2 3 5 7 10],目的是适应文本行长度比较长,宽度比较短的特性,也就是说现在的default box是长条形
- 提出了text-box层,修改classifier卷积核的大小为
,而SSD中卷积核的大小为
,这样做的目的是更适合文本行的检测,避免引入非文本噪声
- 提出了端到端的训练框架.在训练的时候,输入图像由单尺度变成了多尺度
- 增加文本识别来提高文本行检测的效果,印象当中,白翔老师好像在一个报告中说过,增加文本识别在可以提高文本行检测的准确率
知乎:https://zhuanlan.zhihu.com/p/43545190
TextBoxes ++
一、文本检测与传统目标检测的区别:

1.文本检测有比较大的长宽比
2.一般的convolutional filter 无法全部检测到
可能的解决方案:
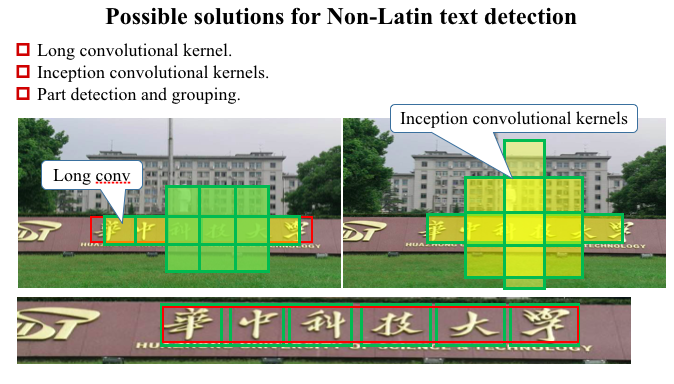
1.长的卷积核
2.inception结构的卷积核
3.局部检测然后组合
二、textboxes 对SSD的改进
1.把ssd的defaultbox 的比例改成(1,2,3,5,7,10)的长矩形
2.看下面图你会发现黄色虚线与SSD的区别 把原先的作为分类的卷积核3*3改成了1*5,更适合文字这样的对象
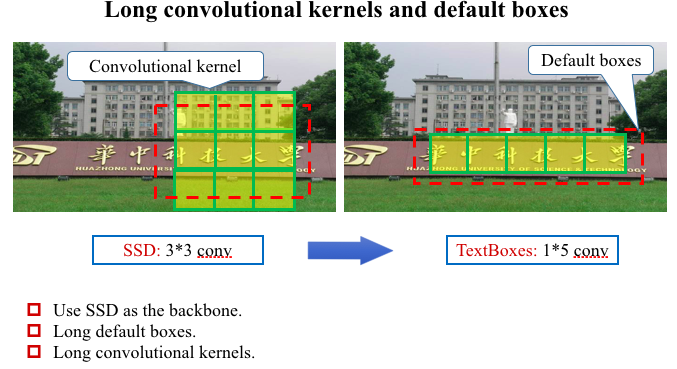
长卷积核与长的defaultbox
3.从多尺度变换成单尺度(这里就奠定了textboxes系列的算法对尺度的依赖的严重性,亲测对不同尺度图片,要调整相应的不同尺度,效果才最好)
 textboxes网络结构
textboxes网络结构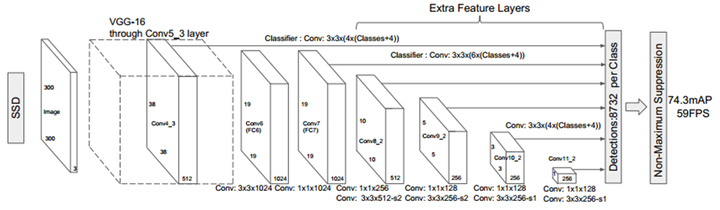 SSD网络结构
SSD网络结构
三,我们来看看textbox++有哪些改进
https://arxiv.org/pdf/1801.02765.pdf 论文所在地
https://github.com/MhLiao/TextBoxes_plusplus 代码所在地
大家可以一起讨论,如下图片红线的 是不是应该少了一个y4。另外 cpu有些问题,建议大家用gpu跑
 问题图片
问题图片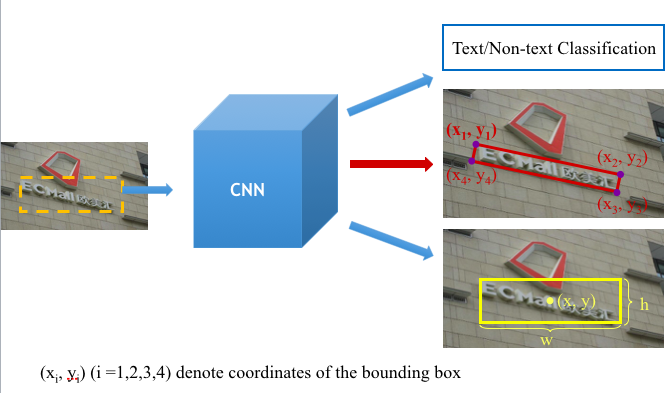 textboxes++的多方向文本检测
textboxes++的多方向文本检测
那么有哪些改进呢?
- 首先就是对于文本框的表示方式发生了变化。论文中讨论了两种表示方式:分别是4个点坐标8个数字(x1,y1,x2,y2,x3,y3,x4,y4)和左上和右上两个点四个坐标外加四边形的高(x1,y1,x2,y2,h)。但论文推荐使用四个坐标的表示方式。

2.NMS采用了级联的方式提高效率,并且用了不同的计算overlap的方式。
通过1的改进提然提示我的有一个奇思妙想,就像人脸关键点识别一样。我给一行文字16点坐标或者32个点坐标 是不是可以使用更多形状的文字呢?比如环形的 比如波浪形的等等。
3.同时由于现在很多都是用IOU来评价当前的好坏。但是文字检测和物体检测的区别是看下图

abc具有用一样的iou那么这样的情况还是要通过crnn来一起判断当前的框是不是最好的!
知乎:https://zhuanlan.zhihu.com/p/34131821
https://zhuanlan.zhihu.com/p/33723456
感谢!仅为记录学习之用,侵删。