注释:
1、书名:Mastering OpenCV with Practical Computer Vision Projects
2、章节:Chapter 3:Marker-less Augmented Reality
3、书中源代码的最新更新可以参考网址:https://github.com/MasteringOpenCV/code
特征提取算子,特征描述符以及特征匹配器,什么鬼?
特征提取内容很广,这里的主要应用图像处理中的特征点提取算法了,计算机对一幅图的关键点提取,死板,死板,很死板,这就是人工智能问题的雏形了,如何让计算机自主并准确辨识图片。
特征描述符,作为一种特征提取算子的补充或是重建。主要解决提取出来的特征点过去单薄,不足以表示内容丰富的图像特征的缺点。那么它无非是把特征点的信息扩大到一定的区域,3*3,9*9,15*15 等等大小的区域,或者以3,5 ,9等等个像素为半径的圆形区域,并计算区域的方向、灰度值、梯度等信息,这样可以增加一副图像的可识别度,完善特征点提取出来的鲁棒性或者健壮性。
特征匹配器,一是一,二是二,一个萝卜一个坑。那么解决匹配中遇到的问题,就需要大家仔细,小心的思考和解决了。主要采用的方法里面,我知道的是蛮力匹配,快速近似最近邻的FLANN匹配。
来看一下项目中如何使用的;
class PatternDetector { public: PatternDetector(Ptr<FeatureDetector> detector = new ORB(1000), //使用orb提取算子 Ptr<DescriptorExtractor> extractor = new FREAK(false, false), //使用freak算子提取特征向量 Ptr<DescriptorMatcher> matcher = new BFMatcher(NORM_HAMMING, true), //使用暴力匹配 bool enableRatioTest = false); //默认不适用比率测试 void train(const Pattern& pattern); //训练模式 void buildPatternFromImage(const Mat &image, Pattern &pattern)const; //从图像中建立模式 bool findPattern(const Mat &image, PatternTrackingInfo &info); bool enableRatioTest; //是否进行比例测试 bool enableHomographyRefinement; //是否进行变换矩阵精细 float homographyReprojectionThreshold; //变换矩阵阈值 protected: bool extractFeatures(const Mat& image, vector<KeyPoint>&keypoints, Mat &descriptors)const; //特征提取包括关键点和特征向量 void getMatches(const Mat& queryDescriptors, vector<DMatch>&matches); //进行匹配 static void getGray(const Mat &image, Mat &gray); //获取灰度图 static bool refineMatchesWithHomography( const vector<KeyPoint>& queryKeypoints, //查询图关键点 const vector<KeyPoint>&trainKeyPoints, //训练图关键点 float reprojectionThreshold, //阈值 vector<DMatch>&matches, //匹配矩阵结果 Mat &homography //变换矩阵 ); private: vector<KeyPoint> m_queryKeypoints; //查询集关键点 Mat m_queryDescriptors; //查询集描述符 vector<DMatch> m_matches; //匹配描述 vector<vector<DMatch>> m_knnMatches; //使用knn匹配的描述符 Mat m_grayImg; //灰度图 Mat m_warpedImg; //透视变换图 Mat m_roughHomograhy; //单应性矩阵(粗超的) Mat m_refinedHomography; //单应性矩阵(精细的) Pattern m_pattern; //模式信息 Ptr<FeatureDetector> m_detector; //其实就是特征提取(使用智能指针来管理内存)FeatureDetector是后面要用到提取的基类 Ptr<DescriptorExtractor> m_extractor; //特征向量提取DescriptorExtractor也是基类 Ptr<DescriptorMatcher> m_matcher; //特征匹配(同上) };
以上的代码里面我们创建了特征提取器,特征描述器,特征匹配器。器,机器,自动处理的工具或方法。
ok,我们把实时图片搬出来,这里调用摄像头捕捉现实场景,把图像存储在currentFrame中,交给pipleline对象的procesFrame处理;
//摄像头处理的函数声明 void processVideo(const Mat &patternImage, CameraCalibration &calibration, VideoCapture &capture) { Mat currentFrame; capture >> currentFrame; //获取摄像机图片 if (currentFrame.empty()) { cout << "不能打开文件" << endl; return; } Size frameSize(currentFrame.cols, currentFrame.rows); //定义窗口的大小 ARPipeline pipeline(patternImage, calibration); //构造对象其实就是把ARPipline中的m_pattern中训练好 ARDrawingContext drawingCtx("Markerless AR", frameSize, calibration); //绘制场景 bool shouldQuilt = false; do { capture >> currentFrame; if (currentFrame.empty())//获取图像 { shouldQuilt = true; continue; } shouldQuilt = processFrame(currentFrame, pipeline, drawingCtx); } while (!shouldQuilt); }
设计findPattern方法对实时图片进行检测它与标记图是否匹配;
bool ARPipeline::processFrame(const Mat&inputFrame) { bool patternFound = m_patternDetector.findPattern(inputFrame, m_patternInfo); //对实时的相机图片查找模式信息其实就是在识别图和相机图间找单映射矩阵,并填充info.points2d if (patternFound) {//如果找到 m_patternInfo.computePose(m_pattern, m_calibration); //计算姿势 } return patternFound; }
findPattern方法中,把实时图片转化为灰度图,通过PatternDetector中的器提取出特征点和特征描述符,在匹配器的作用下获取实时的匹配点对信息m_matches,后面的一部分就是对匹配过程中遇到的问题进行处理和优化,分开说吧;
//在image中查找模式信息,如果找到返回真 bool PatternDetector::findPattern(const Mat &image, PatternTrackingInfo &info)//查找模式信息 { //转成成灰度图 getGray(image, m_grayImg);//获取灰度图 extractFeatures(m_grayImg, m_queryKeypoints, m_queryDescriptors); //从灰度图中获取关键点和描述信息 getMatches(m_queryDescriptors, m_matches); //获取匹配
//=======
//======= }
知识扩展,或者说科普一下知识点呗~ORB算子,FREAK算子,FLANN算法
ORB特征点提取上个博客可以了解一点,网上资料也很多:http://www.cnblogs.com/Alip/p/7026512.html
下面介绍一点FREAK算子,其实别人介绍的很清楚,这里是稍作梳理;
FREAK算法是2012年CVPR上《FREAK: Fast Retina Keypoint》文章中,提出来的一种特征提取算法,也是一种二进制的特征描述算子,跟BRISKORB差不多,扯了个Retina的比较玄乎,主要创新点就是那个Retina的采样pattern.然后由粗到精、扫视搜索的匹配也算是个贡献。
1.先讲了一下Retina的原理,是用不同尺度的DoG采样的。是为FREAK的Motivations。
2.Retinal sampling pattern:是圆的,中间密集些,离中心越远越稀疏(指数下降),感受野有重叠。
3.由粗到精构建描述子。类似ORB,穷举贪婪搜索找相关性小的。43个感受野,大概共有一千对点的组合,作者认为这样找出的前512就足够了,再多的都是相关的了,提供不了更多的信息了。而这512对,分成四组,第一组前128对是相关性更小的,可以代表粗的信息,后面的越来越精。所谓的由粗到精,为Saccadic search也就是扫视匹配提供基础。
4.Saccadic search,因为FREAK的构造是由粗到精的,因此匹配的时候,先看前16bytes,即代表粗信息的部分。如果距离小于某个阈值,再继续看后面精的部分,如果大于就不用往后看了。
5.由于采用了retina pattern来采样,对方向旋转的容错性也还是不错的,“比BRISK强”。
采样模式

上图中每一个黑点代表一个采样点,每个圆圈代表一块感受野,具体在处理时时对该部分图像进行高斯模糊处理,以降低噪声的影响,而且每个圆圈的半径表示了高斯模糊的标准差。这种采样模式与BRISK算法的不同之处在于,每个感受野与感受野之间有重叠的部分。与ORB和BRIEF算法的不同之处在于,ORB和BRIEF算法中的高斯模糊半径都是相同的,而这里采用了这种不同大小的高斯模糊的核函数。作者提出,正是这些不同之处,导致最后的结果更加优秀。通过重叠的感受野,可以获得更多的信息,这些信息可以使最终的描述符更具有独特性。而不同大小的感受野在人体的视网膜中也有这样类似的结构。
最终FREAK算法的采样结构为6、6、6、6、6、6、6、1,这里的6代表每层中有6个采样点并且这6个采样点在一个同心圆中,一共有7个同心圆,最后的1代表的是特征点。
特征描述
FREAK算法也是用二进制串对特征点进行描述,这里用F进行表示,则有
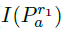 表示采样点对Pa中前一个采样点的像素值,同理,
表示采样点对Pa中前一个采样点的像素值,同理,表示后一个采样点的像素值。
当然得到特征点的二进制描述符后,也就算完成了特征提取。但是FREAK还提出,将得到的N bit二进制描述子进行筛选,希望得到更好的,更具有辨识度的描述子,也就是说要从中去粗取精。(也就是降维)
FREAK采样模式中共43个采样点,7个同心圆上各均匀分布6个,形成C432=903个点对,所有点对比较产生903位的二进制串。但由于采样点的混叠,采样点对具有很高的相关性,所以在对特征点描述之前,需要选择低相关性点对。选择相同尺寸的大量图片进行训练,对每一个检测到的关键点进行全部点对描述,形成N×903的矩阵;计算矩阵每一列0、1的均值,越接近0.5,该列相应点对相关性越低;按均值与0.5的差值绝对值从小到大的顺序排列,取前M位,并记住这M位点对的索引,那么这M位点对索引就是训练产生的结果。选取前512列作为最终的二进制描述符。(也可以是256、128、64、32等)。在进行匹配操作时使用这些低相关性点对就计算得到了低相关性描述子。
由于FREAK描述符自身的圆形对称采样结构使其具有旋转不变性,采样的位置好半径随着尺度的变化使其具有尺度不变性,对每个采样点进行高斯模糊,也具有一定的抗噪性能,像素点的强度对比生成二进制描述子使其具有光照不变性。因此由上述产生的二进制描述子可以用来进行特征匹配。在匹配之前,再补充一下特征点的方向信息。
特征方向
由于特征点周围有43个采样点,可产生43*(43-1)/2=903个采样点对,FREAK算法选取其中45个长的、对称的采样点对来提取特征点的方向,采样点对如下:
用O表示局部梯度信息,M表示采样点对个数,G表示采样点对集合,Po表示采样点对的位置,则:
同BRISK算法,可得到特征点的方向。
特征匹配
在特征描述中,我们得到了512bit的二进制描述符,该描述符的列是高方差——>低方差的排列,而高方差表征了模糊信息,低方差表征了细节信息,与人眼视网膜相似,人眼先处理的是模糊信息,再处理细节信息。因此,选取前128bit即16bytes进行匹配(异或),若两个待匹配的特征点前16bytes距离小于设定的阈值,则再用剩余的位信息进行匹配。这种方法可以剔除掉90%的不相关匹配点。注意:这里的16bytes的选取是建立在并行处理技术(SIMD)上的,并行处理技术处理16bytes与处理1bytes的时间相同;也就是说,16bytes并不是固定的,如果你的并行处理技术能处理32bytes与处理1bytes的时间相同的话,那么你也可以选取前32bytes。
高维数据的快速最近邻算法FLANN
在计算机视觉和机器学习中,对于一个高维特征,找到训练数据中的最近邻计算代价是昂贵的。对于高维特征,目前来说最有效的方法是 the randomized k-d forest和the priority search k-means tree,而对于二值特征的匹配 multiple hierarchical clusteringtrees则比LSH方法更加有效。目前来说,fast library for approximate nearest neighbors (FLANN)库可以较好地解决这些问题。
FLANN里面包含三个算法:随机k-d树算法、 优先搜索k-means树算法和 层次聚类树
自己查了一些,算法思路别人介绍的都有。在这里我想说的是需要弄清的两件事,一是知道如何建立树和索引,二是知道如何查询和检索。拿K-D树来说,百科介绍的也很清楚
先以一个简单直观的实例来介绍k-d树算法。假设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},数据点位于二维空间内(如图1中黑点所示)。k-d树算法就是要确定图1中这些分割空间的分割线(多维空间即为分割平面,一般为超平面)。下面就要通过一步步展示k-d树是如何确定这些分割线的。
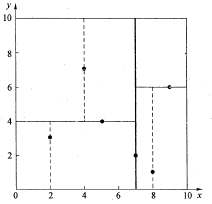
二维数据k-d树空间划分示意图
数据维度只有2维,所以可以简单地给x,y两个方向轴编号为0,1,也即split={0,1}。
(1)确定split域的首先该取的值。分别计算x,y方向上数据的方差得知x方向上的方差最大,所以split域值首先取0,也就是x轴方向;
(2)确定Node-data的域值。根据x轴方向的值2,5,9,4,8,7排序选出中值为7,所以Node-data = (7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于split = 0(x轴)的直线x = 7;
(3)确定左子空间和右子空间。分割超平面x = 7将整个空间分为两部分,如图2所示。x < = 7的部分为左子空间,包含3个节点{(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点{(9,6),(8,1)}。
以此类推;
在k-d树中进行数据的查找也是特征匹配的重要环节,其目的是检索在k-d树中与查询点距离最近的数据点。这里先以一个简单的实例来描述最邻近查找的基本思路。
星号表示要查询的点(2.1,3.1)。通过二叉搜索,顺着搜索路径很快就能找到最邻近的近似点,也就是叶子节点(2,3)。而找到的叶子节点并不一定就是最邻近的,最邻近肯定距离查询点更近,应该位于以查询点为圆心且通过叶子节点的圆域内。为了找到真正的最近邻,还需要进行'回溯'操作:算法沿搜索路径反向查找是否有距离查询点更近的数据点。此例中先从(7,2)点开始进行二叉查找,然后到达(5,4),最后到达(2,3),此时搜索路径中的节点为<(7,2),(5,4),(2,3)>,首先以(2,3)作为当前最近邻点,计算其到查询点(2.1,3.1)的距离为0.1414,然后回溯到其父节点(5,4),并判断在该父节点的其他子节点空间中是否有距离查询点更近的数据点。以(2.1,3.1)为圆心,以0.1414为半径画圆,如图4所示。发现该圆并不和超平面y = 4交割,因此不用进入(5,4)节点右子空间中去搜索。
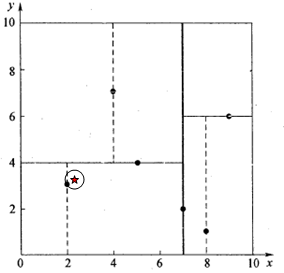
查找(2.1,3.1)点的两次回溯判断
像实际的应用中,如SIFT特征矢量128维,SURF特征矢量64维,FREAK特征矢量128维,维度都比较大,直接利用k-d树快速检索(维数不超过20)的性能急剧下降。假设数据集的维数为D,一般来说要求数据的规模N满足N»2D,才能达到高效的搜索。所以这就引出了一系列对k-d树算法的改进。这也是实践当中使用蛮力匹配方法的一点原因,所以改进高维数据的运算是个重点。
1.随机k-d树算法
主要思想:找出数据集中方差最高的维度,利用这个维度的数值将数据划分为两个部分,对每个子集重复相同的过程。
建立多棵随机k-d树,从具有最高方差的N_d维中随机选取若干维度,用来做划分。在对随机k-d森林进行搜索时候,所有的随机k-d树将共享一个优先队列。
增加树的数量能加快搜索速度,但由于内存负载的问题,树的数量只能控制在一定范围内,比如20,如果超过一定范围,那么搜索速度不会增加甚至会减慢。

2. 优先搜索k-means树算法
随机k-d森林在许多情形下都很有效,但是对于需要高精度的情形,优先搜索k-means树更加有效。 K-means tree 利用了数据固有的结构信息,它根据数据的所有维度进行聚类,而随机k-d tree一次只利用了一个维度进行划分。
算法1 建立优先搜索k-means tree:
(1) 建立一个层次化的k-means 树;
(2) 每个层次的聚类中心,作为树的节点;
(3) 当某个cluster内的点数量小于K时,那么这些数据节点将做为叶子节点。
算法2 在优先搜索k-means tree中进行搜索:
(1) 从根节点N开始检索;
(2) 如果是N叶子节点则将同层次的叶子节点都加入到搜索结果中,count += |N|;
(3) 如果N不是叶子节点,则将它的子节点与query Q比较,找出最近的那个节点Cq,同层次的其他节点加入到优先队列中;
(4) 对Cq节点进行递归搜索;
(5) 如果优先队列不为空且 count<L,那么从取优先队列的第一个元素赋值给N,然后重复步骤(1)。
3. 层次聚类树
层次聚类树采用k-medoids的聚类方法,而不是k-means。即它的聚类中心总是输入数据的某个点,但是在本算法中,并没有像k-medoids聚类算法那样去最小化方差求聚类中心,而是直接从输入数据中随机选取聚类中心点,这样的方法在建立树时更加简单有效,同时又保持多棵树之间的独立性。
同时建立多棵树,在搜索阶段并行地搜索它们能大大提高搜索性能(归功于随机地选择聚类中心,而不需要多次迭代去获得更好的聚类中心)。建立多棵随机树的方法对k-d tree也十分有效,但对于k-means tree却不适用。
参考博文:
http://www.cnblogs.com/eyeszjwang/articles/2429382.html
http://blog.csdn.net/jinxueliu31/article/details/37768995?utm_source=tuicool