经典例子:
1.由26个字母组成的字符串 ^[A-Za-z]+$
2. 中国境内邮政编码 [1-9]\d{5}
3.IP地址 0-99:[1-9]?\d 100-199:1\d{2} 200-249:2[0-4]\d 250-255:25[0-5]
组合起来:
(([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5]).){3}([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5]) #不直接扩展4次是因为最后一段地址后没有点
**************************************************************************************************
re库是python的标准库,主要用于字符串匹配。
引用re库:
import re
re库使用raw string类型(原生字符串类型)
表示为r'text',例如r'[1-9]\d{5}'
在原生字符串类型中转义符不被解释为转义。就比如如果用string类型,则要写成[1-9]\\d{5}

re.search(pattern,string,flags=0)
pattern:正则表达式的字符串或原生字符串表示
string:待匹配的字符串
flags:正则表达式使用时的控制标记
re.match()和re.findall()同上。
re.split(pattern,string,maxsplit)
若maxsplit=1则只由第一个匹配项分割
re.finditer()参数和re.match()相同,但是为迭代用法:
import re
for m in re.finditer(r'[1-9]\d{5}','BIT100081 TSU100084'):
if m:
print(m.group(0))
#100081
#100084
re.sub(pattern,repl,string,count=0,flags=0)
repl:替换匹配字符串处的字符串;count:匹配的最大替换次数

re库的函数式用法:
rst = re.search(pattern,string)
面向对象的用法(效率更高)
pat = re.compile(pattern)
rst = pat.search(string)
r'text'这样的形式并不是正则表达式,只有经过re.compile()编译后生成的regex对象才是正则表达式.
关于match对象:


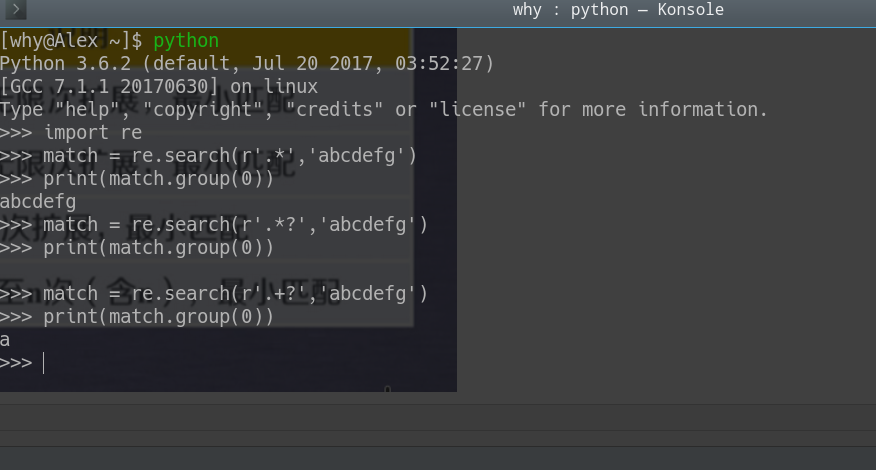
贪婪匹配和最小匹配
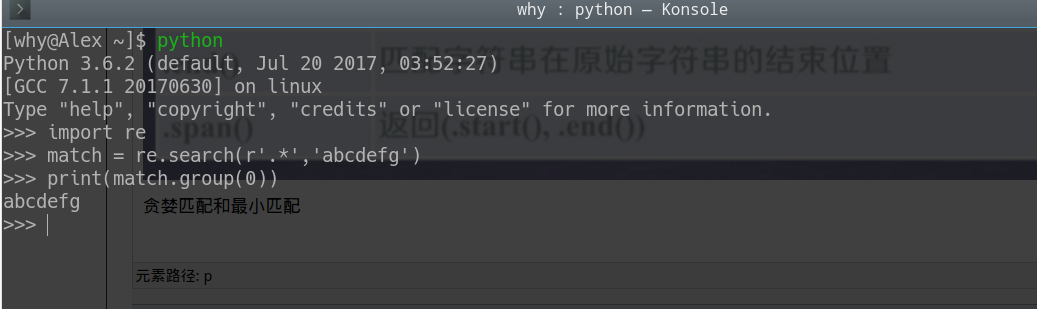
re库会默认最大匹配
如果想要最小匹配呢?