一、什么是进程
程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。
简单的说,进程就是一个正在进行的一个过程或者说一个任务,负责执行任务的人是CPU。
打个比方,我打开了QQ应用程序,然后跟我女朋友聊天,这就是一个进程。
二、进程与程序的区别
程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。
写代码,其实就是写程序,也就是说,程序仅仅是一大堆代码而已,而进程,指的是运行这段程序的运行过程。
另外,需要强调的是:同一个程序执行两次,那也是两个进程。
还是打开QQ聊天,虽然是同一个软件,但是可以开两个聊天窗口,一个跟女朋友聊天,一个跟老板汇报工作。
三、进程的创建
进程需要由操作系统创建,也就是说,只要有操作系统,就有进程的概念。
有一些操作系统只为一个应用程序设计,比如台灯中的控制器,打开台灯之后所有的进程就都已经存在了。
比较常见的还是通用系统,我们的笔记本、服务器都是通用系统,可以运行很多应用程序。
对于通用系统来说,需要有在系统运行过程中创建和销毁进程的能力。
操作系统创建进程有四种方式:
1.系统初始化
2.正在运行的进程开启子进程
3.用户请求交互而创建的新进程
4.批处理作业的初始化
新进程的创建都是由一个已存在的进程执行一个创建进程的程序而创建的。
在Windows系统中,操作系统调用CreatProcess处理进程的创建并把相应的程序读入新进程。
在UNIX系统中,操作系统调用fork,创建一个与父进程一模一样的副本。
父进程和子进程有各自不同的地址空间,任何一个进程在其地址空间中的修改不会影响到另外一个进程。
四、进程的终止
1.正常退出
自愿正常结束一个进程。
我在给老板汇报完工作之后,老板又给我布置了新的任务,而且说这个需求很着急,然我尽快完成,那我就得先跟女朋友说拜拜了,然后一点聊天页面的关闭按钮,这个进程就结束了。
2.出错退出
自愿创建一个进程但出现了一些问题。
老板请求控制我的电脑,要看我的代码演示效果,然后我打开终端,运行python3 text.py,但是我不小心把字打错了,应该运行的是test.py这个程序,text.py根本不存在,这时候就会报错并退出。
C:Users86188>python text.py
python: can't open file 'text.py': [Errno 2] No such file or directory
3.严重作错误
非自愿退出进程。
女朋友是一个算法小白,问我一道算法题,我一看她的错误信息:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero
哦,这是因为把0作为了分母而导致程序退出,一看就是没有考虑边界情况。
4.被其它进程杀死
由于我一边跟女朋友聊天一边给老板演示,频繁的切换,再加上我电脑本来就开启了好多应用程序,QQ突然间卡死了,怎么点都没有用,没办法,启动任务管理器,结束进程,简单粗暴有效。
五、进程的层次结构
每个进程只有一个父进程。
在Windows系统中,所有的进程地位是相同的,但是在创建进程时,父进程获得一个标志,称为句柄,可以用来控制子进程,但是父进程有权把句柄传给其它子进程。
在UNIX系统中所有的进程都是以init进程为根组成树形结构。
六、进程的并发实现
进程的并发实现在于操作系统中断一个正在运行的进程,把此时进程运行的所有状态保存到操作系统维护的进程表中,该表存放了进程状态的重要信息:程序计数器、堆栈指针、内存分配状态、打开文件状态、账号和调度信息和其它所有在进程由运行态转为就绪态或阻塞态时必须保存的信息,以保证该进程再次启动时能够继续上一次的状态运行。
Python中的进程
multiprocess介绍
仔细说来,multiprocess不是一个模块而是python中一个操作、管理进程的包。
之所以叫multi是取自multiple的多功能的意思,在这个包中几乎包含了和进程有关的所有子模块。
Python提供了multiprocessing模块用来开启子进程,并在子进程中执行定制的任务。
multiprocessing模块的功能众多:支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。
Process创建进程
multiprocess中的Process模块可以创建进程。
先看一下源码:
from multiprocessing import Process
在pycharm中安装Ctrl点击Process单词
class Process(process.BaseProcess):
_start_method = None
@staticmethod
def _Popen(process_obj):
return _default_context.get_context().Process._Popen(process_obj)
Process继承自process.BaseProcess,而且Process本身没有--init--方法,所以我们要看它的基类,也就是BaseProcess:
class BaseProcess(object):
def __init__(self, group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None):
assert group is None, 'group argument must be None for now'
count = next(_process_counter)
self._identity = _current_process._identity + (count,)
self._config = _current_process._config.copy()
self._parent_pid = os.getpid()
self._popen = None
self._closed = False
self._target = target
self._args = tuple(args)
self._kwargs = dict(kwargs)
self._name = name or type(self).__name__ + '-' + ':'.join(str(i) for i in self._identity)
if daemon is not None:
self.daemon = daemon
_dangling.add(self)
咱们先看有用的内容,
class BaseProcess(object):
def __init__(self, group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None):
...
self._target = target
self._args = tuple(args)
self._kwargs = dict(kwargs)
self._name = name or type(self).__name__ + '-' + ':'.join(str(i) for i in self._identity)
...
由BaseProcess类实例化得到对象指向一个子进程中的需要执行的任务,target指向函数名,注意不要加括号,name是给子进程起的名字,args指定为传给target函数的位置参数,是一个元组的形式,kwargs指定为传给target函数的关键字参数,是一个字典的形式。
好了,我们现在知道创建一个进程需要的元素了,接下来就可以coding了:
import time
from multiprocessing import Process
def task(process_name):
print(process_name, " started on: ", time.asctime(time.localtime(time.time())))
time.sleep(2)
print(process_name, " end on: ", time.asctime(time.localtime(time.time())))
if __name__ == '__main__': # Windows下因为系统创建进程的机制必须写main
process = Process(target=task, kwargs={"process_name": "Process 1"})
process.start() # 仅仅只是给操作系统发送了一个信号
print("Main process end on: ", time.asctime(time.localtime(time.time())))
输出结果为:
Main process end on: Thu Feb 6 12:33:49 2020
Process 1 started on: Thu Feb 6 12:33:49 2020
Process 1 end on: Thu Feb 6 12:33:51 2020
思考题1:target赋值为什么不能加括号?
思考题2:Windows下开启进程为什么一定要放在main函数中?
process = Process(target=task, kwargs={"process_name": "Process 1"})
创建了一个进程对象,并把该进程要执行的函数注册到进程中,此时还没有启动进程。
process.start() # 仅仅只是给操作系统发送了一个信号
这是告诉操作系统,开启process这个进程,这个进程中将执行task函数,而task这个进程是由我当前运行的python程序创建出来的,所以当前的python程序运行的进程为父进程,process开启的进程为子进程。
process的执行,相当于在你看不到的内存中又创建了一个python文件,执行task函数中的内容,只不过创建的这个python文件跟父进程的程序是有所联系的,在新建文件中import了原文件。
注意,process.start()并不是马上就执行这个进程,观察输出结果,首先输出的Main process end,这说明主程序已经运行到最后一行了,然后Process 1才开启。
这是因为,进程有三个状态:执行、就绪、阻塞,只有轮到子进程,CPU执行时间片才会运行进程。
再考虑一个问题,主进程代码运行完了,子进程为什么没结束?
我为什么会这样问,来看一下刚才代码的最后一行:
print("Main process end on: ", time.asctime(time.localtime(time.time())))
打印提示信息和系统当前时间,按道理来说这段代码执行完之后主进程代码就结束了,但是控制台上还有两行输出结果,这两行结果是子进程的输出结果,也就是说,主进程代码运行完了但是子进程没结束。
注意,我们说的是主进程代码运行完了,并没有说是主进程死了,这就是接下来要说的进程的声明周期。
如果子进程的运行时间长,那么等到子进程执行结束程序才结束,如果主进程的执行时间长,那么主进程执行结束程序才结束。
实际上我们在子进程中打印的内容在主进程的执行结果中是看不到的,但是pycharm帮我们做了优化,它能够识别到你开启了子进程,帮你把子进程中打印的内容显示在控制台上。
那么,怎么才能验证我上面说的那句话呢?你可能想,既然这是pycharm的优化,那我在cmd上运行的话是不是就可以验证了。
事实证明也不行,也能看到输出结果:
C:Users>python temp.py
Main process end on: Thu Feb 6 16:24:11 2020
Process 1 started on: Thu Feb 6 16:24:11 2020
Process 1 end on: Thu Feb 6 16:24:13 2020
这TM可怎么办,我得验证我说的是真的啊,不然我不就是骗人了么。
经过我在不同的系统和不同的平台上实验,终于找到一个不输出子进程结果的运行平台了:Jupyter Notebook,由此证明jupyter不适合做多进程开发调试工具:
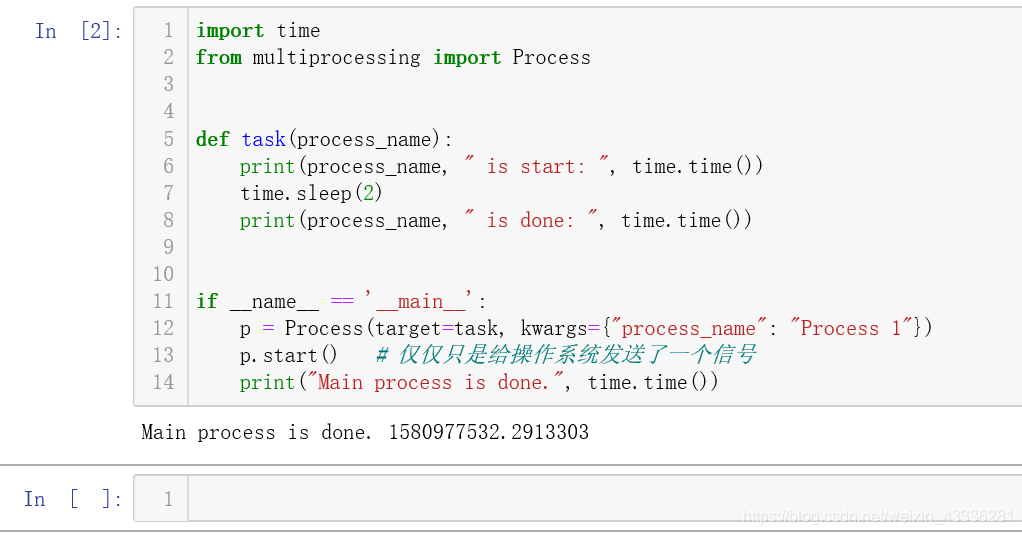
思考题答案
1:target赋值为什么不能加括号?
不加括号相当于拿到的是函数的地址,而加上括号就是执行函数之后得到的返回值。
2:Windows下开启进程为什么一定要放在main函数中?
咱们把创建进程的第一个演示代码改动一下:
import time
from multiprocessing import Process
def task(process_name):
print(process_name, " started on: ", time.asctime(time.localtime(time.time())))
time.sleep(2)
print(process_name, " end on: ", time.asctime(time.localtime(time.time())))
process = Process(target=task, kwargs={"process_name": "Process 1"})
process.start() # 仅仅只是给操作系统发送了一个信号
print("Main process end on: ", time.asctime(time.localtime(time.time())))
在Windows Pycharm下运行,会发现根本运行不了,直接就报错:
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
而在Linux下运行同样的代码:
[alex@alex ~]$ python3 temp.py
Main process end on: Thu Feb 6 15:39:24 2020
Process 1 started on: Thu Feb 6 15:39:24 2020
Process 1 end on: Thu Feb 6 15:39:26 2020
不同的操作系统得到不同的结果,这是为什么呢?
回忆一下一开始讲进程的创建说过:
在Windows系统中,操作系统调用CreatProcess处理进程的创建并把相应的程序读入新进程。
在UNIX系统中,操作系统调用fork,创建一个与父进程一模一样的副本。
Windows开启进程的机制类似于在内存中新建了一个python文件,然后将当前文件import到新的文件中,这时候会把原文件的所有代码都跑一遍,def定义的函数倒是无所谓,但是不放在main函数中的代码会被直接执行,也就是说,在新文件中又会开启一个子进程,这样下去,子进程开子进程,子进程开子进程,这会无限循环的,直到机器耗尽资源,还好我们的Windows python直接给报错。
那Linux为什么不会报错呢?这是因为Linux开启子进程只是去执行我子进程中注册的那个函数,不会执行别的代码,所以不会报错。