变量存在的意义:方便管理内存。
变量创建的语法:数据类型 变量名=变量的初始值;
int a = 10;
#define 宏常量
通常在文件上方定义,表示一个常量
#const修饰的变量const 数据类型 变量名 = 常量值;
通常在变量定义前面加关键字const,修饰该变量伟常量,不可修改。
区别:define是宏定义,程序在预处理阶段将用define定义的内容进行了替换。因此程序运行时,常量表中并没有用define定义的常量,系统不为它分配内存。const定义的常量,在程序运行时在常量表中,系统为它分配内存。
C++ 关键字
标识符命名规则
作用:C++规定给标识符(变量,常量)命名时,有自己的规则。
1、标识符不能是关键字
2、标识符只能由字母、数字、下划线组成
3、第一个字符必须伟字母或下划线
4、标识符中字母区分大小写
#数据类型
存在的意义:给变量分配一个合适的内存空间。
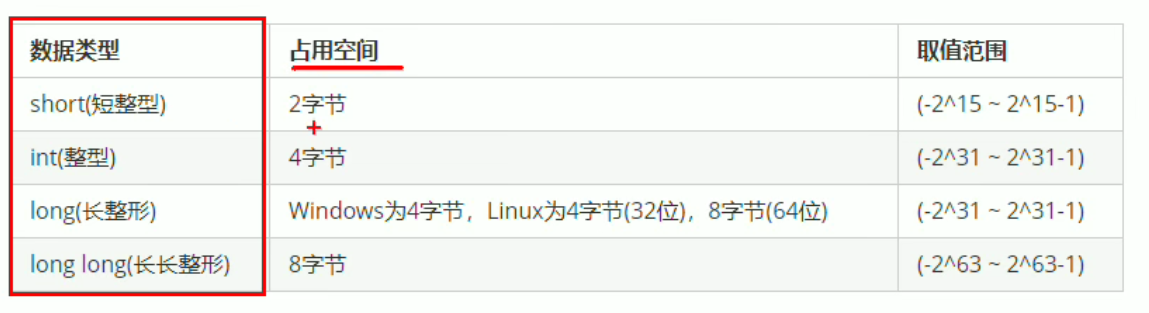
sizeof关键字
//可以利用sizeof求出数据类型占用的内存大小
//语法:sizeof(数据类型、变量)
实型

默认输出一个小数,只会输出六个有效数字
float f2 = 3e2;
cout << f2<<endl; 300
float f3 = 3e-2;
cout << f3; 0.3
1、单精度
2、双精度
字符型
C/C++字符变量只存一个字节。
字符型变量并不是把字符本身存到内存中,而是存的ascii值。
转义字符
加参数
字符串型
C语言风格字符串
char 变量名[] = “字符串的值";
C++语言风格字符串
String 变量名=”字符串值“;
布尔类型
true=1;
false=0;
只占用1个字节。
bool只要是非0都为真。
三目运算符。
创建三个变量abc
将a和b做比较,将变量打的值赋值给C。
int a = 10;
int b = 20;
int c = 30;
c=(a > b ? a : b);
switch语句
缺点:判断时候只能是整形或字符型,不可以是一个区间。
优点:结构清晰,执行效率高。
一维数组创建
//数组类型 数组名[数组长度];
//数组类型 数组名[数组长度] = { 值1,值2,值3 };
//数组类型 数组名[] = { 值1,值2,值3 };
一维数组名称的用途:
1、可以统计整个数组在内存中的长度
2、可以获取数组中内存的首地址
cout << (int)&arr[0] << endl;
//将地址转为10进制
二维数组定义方式:
数据类型 数组名[行数][列数];
数据类型 数组名[行数][列数]={{数据1,数据2},{数据3,数据4}}
数据类型 数组名[行数][列数]={数据1,数据2,数据3,数据4};
数据类型 数组名[][列数]={数据1,数据2,数据3,数据4}
二维数组数组名
1、查看二维数组所占内存空间
2、获取二维数组的首地址
int arr[2][3] = { 1,2,3,4,5,6 };
cout << sizeof(arr)<<endl;
cout << arr << endl;
cout << sizeof(arr[0]) << endl;//一行所占的内存大小。
cout << arr[0][0] << endl;
函数
函数的声明
提前告诉编译器函数的存在,可以利用函数的声明。
函数的分文件编写
作用:让代码结构更加清晰
1、创建后缀名为.h的头文件
2、创建后缀名为.cpp的源文件
3、在头文件写函数的声明
4、在源文件中写函数的定义
指针
空指针和野指针
空指针:指针变量只想内存中编号为0的空间
用途:初始化指针变量
注意:空指针只想的内存是不可访问的。
C++核心编程部分
1、内存分区模型
C++程序在执行的时候,将内存大方向划分为4个区域
运行的时候。
1、代码区:存放函数体的二进制代码,由操作系统管理的
2、全局区:存放静态变量和全局变量
3、栈区:由编译器自动分配释放,存放函数的参数值,局部变量等。(只要是局部都是栈区)
4、堆区:由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收。
意义:不同的区域存放的数据,赋予不同的生命周期,更灵活的编程。
在程序编译后,未执行以前分成两个区域
代码区:
存放CPU执行的机器指令
代码区是共享的,共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可。
代码区是只读的,使其只读的原因是防止程序意外地修改它的指令。
全局区:
全局变量和静态变量存放的区域
全局区还包含了常量区,字符串常量和其他常量存放在此
该区域的数据在程序结束后操作系统释放。
总结:
C++在运行之前,编译后,分为全局区和代码区
代码区的特点是共享和只读
全局区中存放全局变量、静态变量、常量
常量区存放const修饰的全局变量 和字符串常量。
不要返回局部变量的地址
int* func() {//形参数据也放在栈区
int a = 10;
return &a;
}
int main() {
int* p = func();
cout << *p << endl;//第一次可以打印是因为,编译器做了保留
cout << *p << endl;//第二次数据不再保留了。
system("pause");
return 0;
}
堆区:
由程序员分配释放,若程序员不是放,程序结束的时候由操作系统回收
在C++中主要利用new在堆区开辟内存
指针本质也是局部变量,放在栈上,但是指针保存的数据是存放在堆区。
#include <iostream>
using namespace std;
int* func() {
int* a = new int(10);
return a;
}
int main() {
int* p = func();
cout << *p << endl;// 在堆区开辟的数据
cout << *p << endl;//
system("pause");
return 0;
}
new操作符
C++利用new操作符在堆区开辟数据
堆区开辟的数据,由程序员手动开辟,手动释放,释放利用操作符delete
语法:new 数据类型
利用new创建的数据,会返回该数据对应的类型的指针。
delete操作符
堆区的数据 由程序员管理开辟 程序员管理释放
如果想释放堆区的数据,利用关键字 delete释放
int *p=new int(10);
delete p;
在堆区利用new开辟数组
创建10整形数据的数组,在堆区
int *arr=new int[10];//10代表数组有10个元素。
释放数组的时候
delete[] arr;
引用
语法:数据类型 &别名=原名
int &b=a;
b=20;
cout<<a<<endl;// a为20
int main() {
int a = 10;
int b = 20;
//int &c;//错误,引用必须初始化
int &c = a;//一旦初始化以后,就不可以更改
c = b;//这是赋值操作,不是更改引用
cout << " a = " << a << endl;
cout << " b = " << b << endl;
cout << " c = " << c << endl;
system("pause");
return 0;
}
1、引用必须要初始化
2、引用一旦初始化后,就不可以更改。
访问权限
三种
公共权限 成员类内可以访问 类外可以访问
保护权限 成员类内可以访问 类外不可以访问 区别:继承中。儿子可以访问父亲中的保护内容。
私有权限 成员类内可以访问 类外不可以访问 区别:儿子不能访问父亲的内容。儿子不可以访问父亲的私有内容。
struct和class区别:
struct默认权限为公共
class默认权限为私有
成员属性设置为私有
优点1:将所有成员属性设置为私有,可以自己控制读写权限
优点2:对于写权限,我们可以检测数据的有效性
void setName(string name){
if(name=="")
return;
}
#pragma once
防止头文件被重复包含。
仿函数:在类中重载()符号。
