1.LPA算法简介
标签传播算法(Label Propagation Algorithm,LPA)是由Zhu等人于2002年提出,它是一种基于图的半监督学习方法,其基本思路是用已标记节点的标签信息去预测未标记节点的标签信息。
LPA算法思路简单清晰,其基本过程如下:
(1)为每个节点随机的指定一个自己特有的标签;
(2)逐轮刷新所有节点的标签,直到所有节点的标签不再发生变化为止。对于每一轮刷新,节点标签的刷新规则如下:
对于某一个节点,考察其所有邻居节点的标签,并进行统计,将出现个数最多的那个标签赋值给当前节点。当个数最多的标签不唯一时,随机选择一个标签赋值给当前节点。
在标签传播算法中,节点的标签更新通常有同步更新和异步更新两种方法。同步更新是指,节点x在t时刻的更新是基于邻接节点在t-1时刻的标签。异步更新是指,节点x在t时刻更新时,其部分邻接节点是t时刻更新的标签,还有部分的邻接节点是t-1时刻更新的标签。LPA算法在标签传播过程中采用的是同步更新,研究者们发现同步更新应用在二分结构网络中,容易出现标签震荡的现象。因此,之后的研究者大多采用异步更新策略来避免这种现象的出现。
2.LPA算法
2.1相似矩阵构建
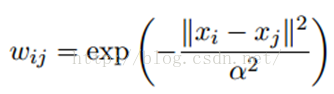
2.2LPA算法
标签传播算法非常简单:通过节点之间的边传播label。边的权重越大,表示两个节点越相似,那么label越容易传播过去。我们定义一个NxN的概率转移矩阵P:

Pij表示从节点i转移到节点j的概率。我们将YL和YU合并,我们得到一个NxC的soft label矩阵F=[YL;YU]。soft label的意思是,我们保留样本i属于每个类别的概率,而不是互斥性的,这个样本以概率1只属于一个类。当然了,最后确定这个样本i的类别的时候,是取max也就是概率最大的那个类作为它的类别的。那F里面有个YU,它一开始是不知道的,那最开始的值是多少?无所谓,随便设置一个值就可以了。
简单的LP算法如下:
(1)执行传播:F=PF;
(2)重置F中labeled样本的标签:FL=YL;
(3)重复步骤(1)和(2)直到F收敛。
步骤(1)就是将矩阵P和矩阵F相乘,这一步,每个节点都将自己的label以P确定的概率传播给其他节点。如果两个节点越相似(在欧式空间中距离越近),那么对方的label就越容易被自己的label赋予。步骤(2)非常关键,因为labeled数据的label是事先确定的,它不能被带跑,所以每次传播完,它都得回归它本来的label。
2.3变身的LPA算法
我们知道,我们每次迭代都是计算一个soft label矩阵F=[YL;YU],但是YL是已知的,计算它没有什么用,在步骤(2)的时候,还得把它弄回来。我们关心的只是YU,那我们能不能只计算YU呢?我们将矩阵P做以下划分:

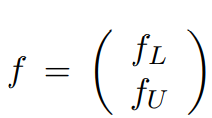 ,
,
这时候,我们的算法就一个运算:

迭代上面这个步骤直到收敛就ok了。可以看到fU不但取决于labeled数据的标签及其转移概率,还取决了unlabeled数据的当前label和转移概率。因此LP算法能额外运用unlabeled数据的分布特点。
2.4收敛性证明
当n趋近于无穷大是,有
 ,
,
其中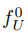 是fU的初始值,因此我们需要证明
是fU的初始值,因此我们需要证明  因为P是行标准化的,并且PUU是P的子矩阵,所以
因为P是行标准化的,并且PUU是P的子矩阵,所以
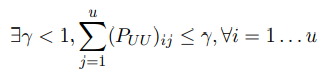 ,
,
因此
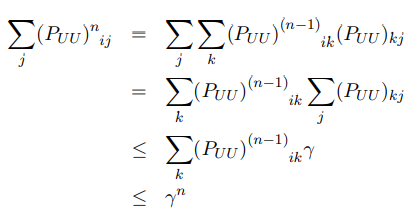
当n趋近于无穷大时,rn=0,(PUU)n收敛于0,也意味着因此的初始值是无关紧要的,同时第n次迭代时fU收敛。