部分代码已托管到码云:
多任务处理
计算机技术中,多任务处理指的是同时执行及格独立的任务。
-
在单处理器系统中,一次只能执行一个任务。
多任务处理器是通过在不同任务之间多路复用CPU的执行时间来实现的(将CPU执行操作从一个任务切换到另一个任务)。不同任务之间的执行切换机制称为上下文切换,将一个任务的执行环境更改为另一个任务的执行环境,如果切换速度够快,就会给人同时执行所有任务的错觉(并发)。
-
多任务处理器系统中,可在不同CPU上实时、并发执行多项任务。每个处理器也可以通过同时执行不同的任务来实现多任务处理。
多任务处理是所有操作系统的基础,也是并行编程的基础。font>
进程
可用ps命令查看系统下的进程:
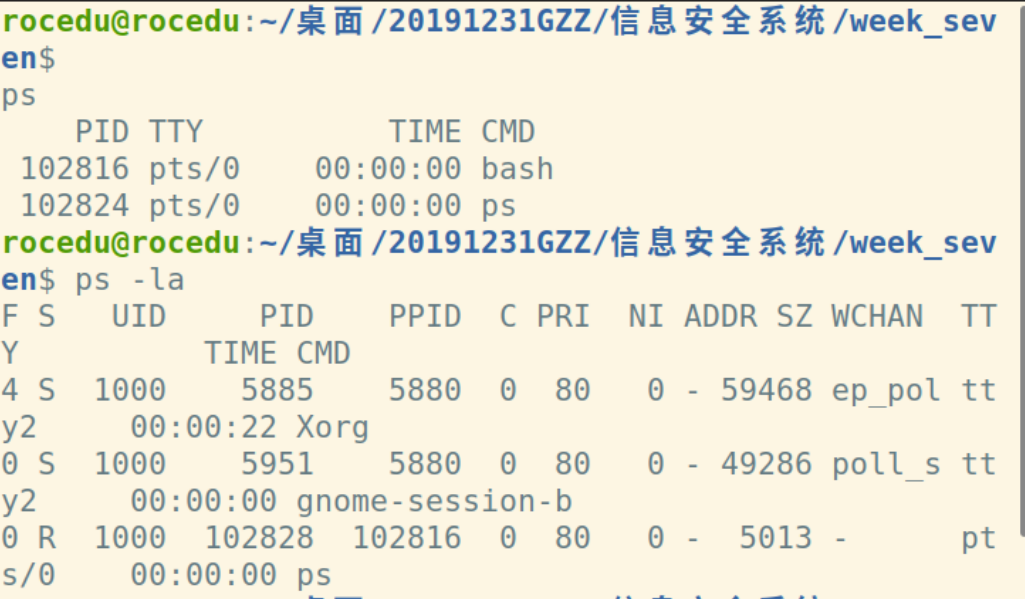
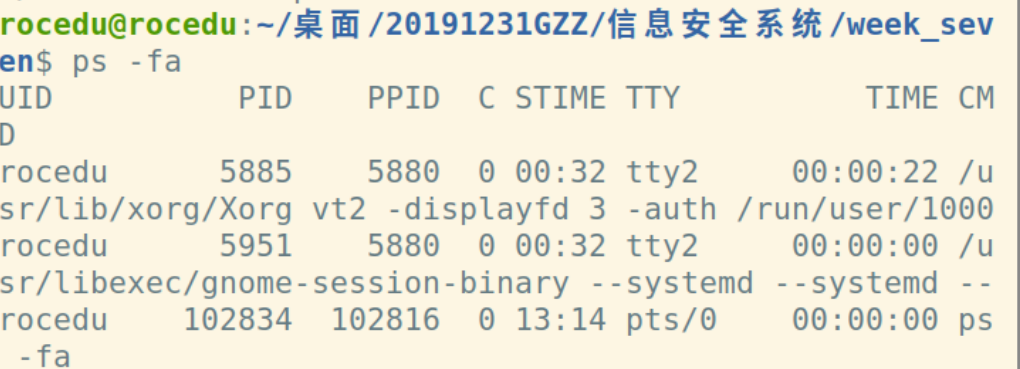
操作系统是一个多任务处理系统。操作系统中的任务也称为进程。进程是对映像的执行。
操作系统内核将一系列执行视为使用系统资源的单一实体。
系统资源包括:内存空间、I/O设备、CPU时间
操作系统内核中,每个进程用一个独特的数据结构表示,叫做进程控制块(PCB)或任务控制块(TCB),称为PROC结构体。
PROC结构体包含某个进程的所有信息。
typedef struct proc{
struct proc *next;//指向下一个PROC结构体的指针
int *ksp;//保存的堆栈指针
int pid;//标识一个进程的进程ID编号
int ppid;//父进程的ID编号
int status;//进程当前状态
int priority;//进程调度优先级
int kstack[1024];//进程执行时的堆栈。
}PROC;
操作系统内核通常会在其数据区中定义有限数量的PROC结构体,表示为
PROC proc[NPROC];
用来表示系统中的进程。
单CPU系统中,操作系统内核经常会使用PROC指针,指向当前正在执行的PROC。
多CPU的多处理操作系统中,可在不同的CPU上实时、并行执行多个进程。因此多处理器系统中正在运行的[NCPU]可能是一个指针数组,每一个元素指向一个正在特定CPU上运行进程。
多任务处理系统
type.h文件
进程同步
一个操作系统包含许多并发进程,这些进程可以彼此交互。
进程同步是指控制和协调进程交互以确保其正确执行所需的各项规则和机制。
睡眠模式
当某进程需要某些当前没有的东西时就会在某个值上进入休眠状态,该事件值表示休眠的原因。
typedef struct proc{
struct proc *next;
int *ksp;
int pid;
int ppid;
int status;
int priority;
int event;//使进程进入睡眠状态
int exitCode;
struct proc *chlid;
struct proc *sibling;
struct proc *parent;
int kstack[1024];
}PROC;
唤醒操作
多个进程可能会进入休眠状态等待同一事件,因为这些进程可能都需要同一个资源。这时,所有进程将休眠等待同一个事件值。当某个等待时间发生时,另一个执行实体(可能是某个进程或中断处理程序)会调用kwakeup(event),唤醒正处于休眠状态等待该事件的所有程序。无程序休眠等待该程序,kwakeup()就不工作(不执行任何操作)
进程终止
-
正常终止:进程调用exit(value)。发出-exit(value)系统调用来执行在操作系统内核中的kexit(value);
-
异常终止:进程因为某个信号而终止;
两种情况当进程终止时都会调用kexit()。
进程家族树
通常,进程家族树通过PROC结构中的一对子进程和兄弟进程二叉树的形式实现
PROC *child,*sibling,*parent;
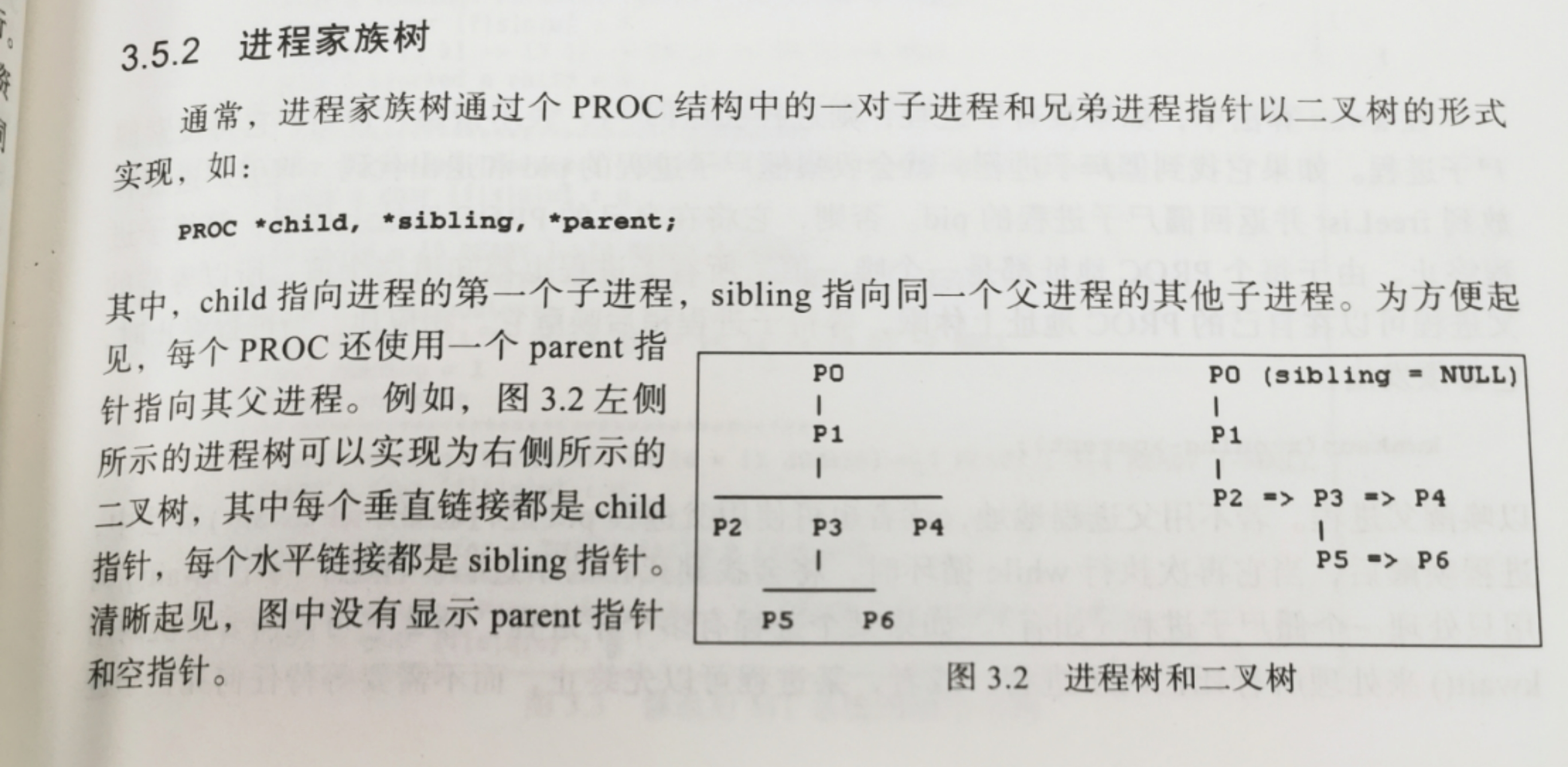
-
使用进程树更容易找到子进程
-
每个PROC都有一个退出代码(exitCode)字段,是进程终止时的进程退出值(exitValue)。进程状态更改为ZOMBIE,但不释放PROC结构体。
等待子进程终止:
任何时候,进程都可以调用内核函数
pid =kwait(int *status)
等待僵尸子进程。如果成功,则返回的pid是僵尸子进程的pid,而status包含僵尸子进程的退出代码。此外,kwait()还会将僵尸子进程释放回freeList以便重用。
kwait的算法:
int kwait(int *status)
{
if(caller has no child)return -1 for error;
while(1){//caller has children
search for a (any) ZOMBIE child;
if(found a ZOMBIE child){
get ZOMBIE child pid
copy ZOMBIE child exitCode to *status;
burry the ZUMBIE child(put its PROC back to freeList)
return ZOMBIE child pid;
}
ksleep(running);
}
}
Unix/Linux 中的进程
进程来源
-
操作系统启动时,内核会强制创建一个PID=0的初始进程,通过分配PROC结构体(PROC[0])进行创建,初始化PROC内容,并让运行指向proc[0];
-
系统执行初始化进程P0;大多数操作系统都以这种方式开始第一个进程。P0继续初始化系统,包括系统硬件和内核数据结构。
-
挂载一个根文件系统,使系统可以使用文件。
-
初始化系统后,P0复刻出一个子进程P1,并把进程切换为用户模式运行P1。
INIT和守护进程
P1通常被称为INIT进程,因为他的执行映像是init程序。
守护进程:在后台运行,不与任何用户交互
登录进程
每个LOGIN进程打开三个与自己的终端相关联的文件流,这三个文件流分别是用于标准输入的stdin、标准输出的stdout、用于标准错误消息的stderr。每个文件流都是指向进程堆栈区中FILE结构体的指针。
sh进程
用户登录成功时,LOGIN进程会获取用户的gid和uid,从而成为用户的进程。它将目录更改为用户的主目录并执行列出的程序,通常是命令解释程序sh(通常称为sh进程)。它提示用户执行命令。一些特殊的命令,如成cd(更改目录)、退出、注销等,由sh自己直接执行。其他大多数命令是各种bin目录中的可执行文件。
对于每个(可执行文件)命令,sh会复刻一个子进程,并等待子进程终止。子进程将其执行映像更改为命令文件并执行命令程序。子进程在终止时会唤醒父进程sh,父进程会收集子进程终止状态、释放子进程PROC结构体并提示执行另一个命令等。除简单命令外,sh还支持I/O重定向和通过管道连接的多个命令。
进程的执行模式
Unix/Linux中,进程以两种不同的模式执行,即内核模式和用户模式,简称Kmode和Umode。
在进程的生命周期中,会在Kmode和Umode之间发生多次迁移。每个进程都在Kmode下产生并开始执行。
在Kmode下执行所有相关操作,包括终止。在Kmode下通过将CPU状态寄存器从K模式更改为U模式,可以轻松切换到Umode。但是进入Umode就不能够随意更改CPU状态了。Umode进程只能通过下面三种方式进入Kmode。
(1)中断:外部设备发送给CPU信号,请求CPU服务。当在Umode下执行时,CPU中断是启用的,因此它将响应任何中断。中断发生时,CPU将进入Kmode处理中断,这将导致进程进入Kmode;
(2)陷阱:陷阱是错误条件,错误条件被CPU识别为异常,使得CPU进入Kmode来处理错误。在Unix/Linux中内核陷阱处理程序将陷阱原因转换为信号编号,并将信号传递给进程。对于大多数信号,进程的默认操作是终止。
(3)系统调用(syscall):允许Umode进程进入Kmode以执行内核函数的机制。当某进程执行完内核函数后,它将期望结果和一个返回值返回到Umode,0表示成功,1表示错误。发生错误,外部全局变量errno(在errno.h中)会包含一个ERROR代码,用于标识错误。
进程管理的系统调用
frok()函数
-
返回值:子进程中返回0 ,父进程中返回子进程id,错误返回-1
-
一个进程,包括代码、数据和分配给进程的资源。fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
-
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
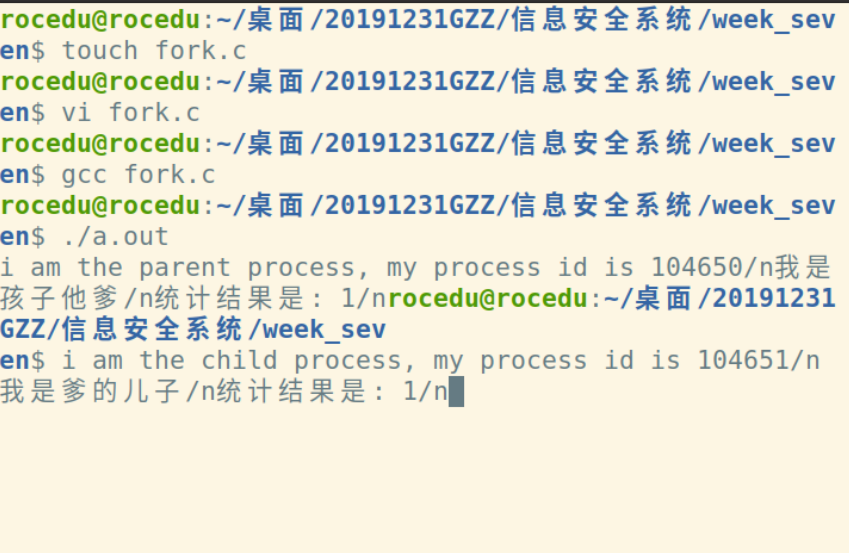
一个有关fork()的例子
代码链接如下:
运行结果如图:
-
fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值: 1)在父进程中,fork返回新创建子进程的进程ID; 2)在子进程中,fork返回0; 3)如果出现错误,fork返回一个负值;
-
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。
-
fpid的值为什么在父子进程中不同。其实就相当于链表,进程形成了链表,父进程的fpid(p 意味point)指向子进程的进程id,因为子进程没有子进程,所以其fpid为0。
C3.2代码:
(1)sleep()被注释的情况下:
/************** C3.2.CS ***************/
运行结果如下:

(2)sleep()不注释情况下:
运行结果如下:

C3.3代码:
/************** C3.3.CS wait() and exit() ***************/
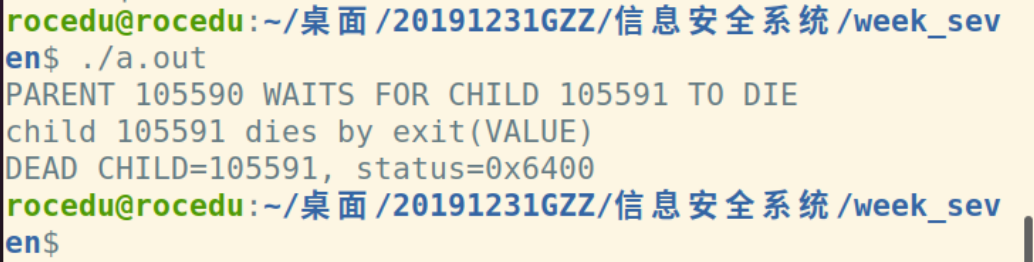
运行结果如下:
C3.4代码:
//************** C3.4.c ***********************//
运行结果如下:

I/O重定向
sh进程有三个用于终端I/O的文件流:stdin(标准输入)、stdout(标准输出)、stderr(标准错误)。其文件描述符分别对应0、1、2。
在执行 scanf("%s", &item); 时,就会从stdin读入,如果其FILE结构体 fbuf[] 为空,它就会向Linux内核发出read系统调用,从终端 /dev/ttyX 或为终端 /dev/pts/# 上读入。
网上查到的I/O重定向符号和作用图:

管道
管道是用于进程交换数据的单向进程间通信的通道。管道有一个输入端、一个输出端。在之前我们使用man -k | grep xx时,就用到管道的功能。 管道的使用可以通过程序完成,也可以在命令行中处理完成。
sh将通过一个进程运行cmd1,并通过另一个进程运行cmd2,他们通过一个管道连接在一起,因此cmd1的输出变为cmd2的输入.
-
命令管道
命令管道又叫FIFO
(1)在sh中,通过mknod命令创建一个命令管道:
(2)或在c语言中发出mknod()系统调用
(3)进程可像访问普通文件一样发个文命名管道。
参考链接: