现在我们有一个视频流,可以拆解出 N 个帧出来,这时候初始帧/某一帧中出现了一个我们感兴趣目标,我们希望在后续帧中对这个目标进行追踪,这时候就需要 CV 中的目标追踪;
目标追踪的效果如下:

虽然效果看起来和实时人脸检测识别效果一样,但是其实只对初始帧进行了人脸检测和识别,后续帧只需要进行检测,不需要再进行识别;
Q: 那么问题来了,为什么不直接对每一帧进行检测+识别?
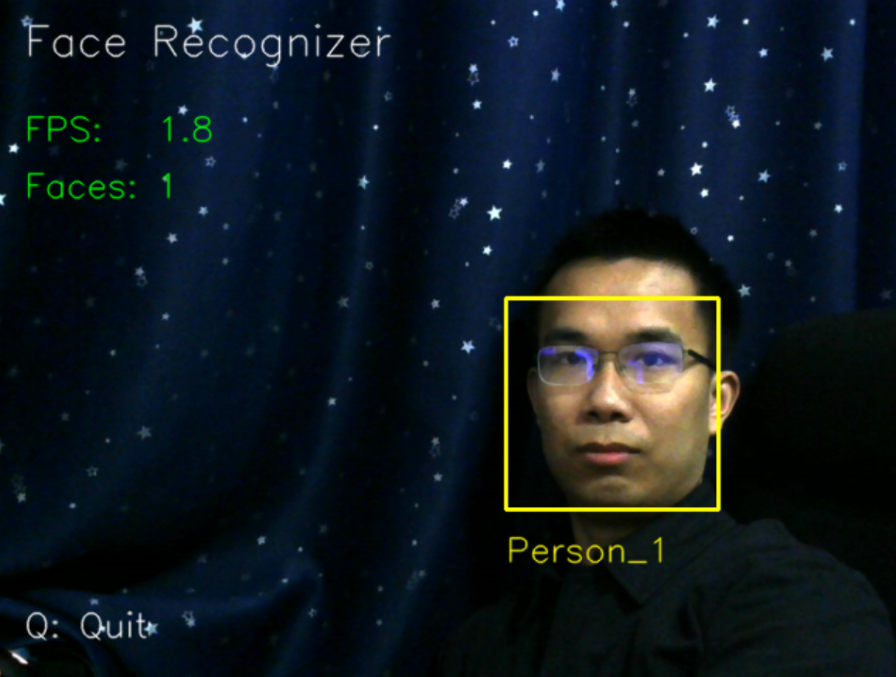
A: 因为识别所占用的资源要远远大于检测;可以看到下图中,左边进行实时的检测+识别,在无 GPU,CPU=i7-8700K 的情况下,FPS 只有 1.8;
而右图中如果换成目标追踪的方法(只对初始帧做识别,后续帧只做跟踪),FPS 可以达到了 28,获得了差不多 15 倍的提升;

为了实现目标追踪,我们按照以下步骤进行:
- 对于初始帧(视频流中的第一帧),输入/通过检测算法,得到一系列目标的位置坐标;
- 为这些 ROI 创建 ID;
- 在视频流中的后续帧,寻找帧之间目标对象的关系,将帧之间的目标关联起来;
目标跟踪可以让我们对于每一个追踪的目标指定一个唯一的 ID,所以让我们可以对视频中的跟踪物体进行计数,应用于计算人数的场景;
一个理想化的目标追踪算法能够实现:
- 只需要初始化的时候进行目标检测;
- 处理速度能够很快;
- 可以处理被跟踪目标,消失或者超过边界的情况;
- 可以处理帧之间目标消失,然后再出现的特殊情况;
上图 gif 中只有一个目标,所以其实后续帧中的检测出来的目标,如果还是一个,肯定就是我们第一帧中识别出来的 person_X;
但是往往是一帧中出现多目标,我们就需要对于前后帧中的多目标进行比对匹配;
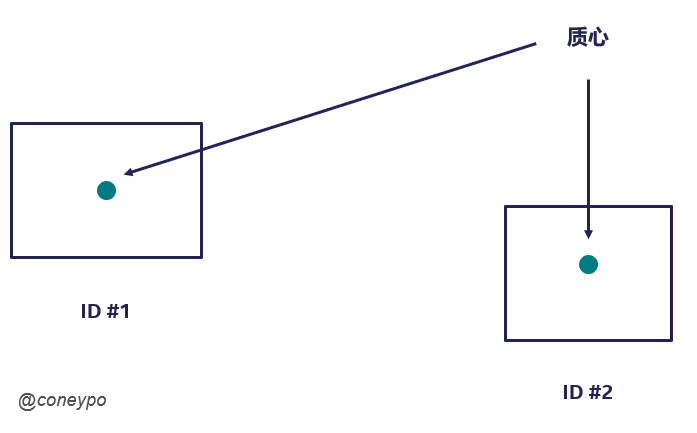
以下图为例,比如左边是第 N 帧 ,有两个目标,我们检测识别出来是 ID#1 和 ID#2,在 N+1 帧中,也检查出来两个目标,我们知道这两个目标就是 ID#1 和 ID#2,但是不知道到底哪个是 ID#1 哪个是 ID#2;

所以就需要 质心追踪算法(Centroid Tracking)来进行判定后续帧中的 ID:

质心追踪算法(Centroid Tracking),依赖于在视频流的连续帧中,比较已知目标和新出现目标之间质心的欧氏距离;
整体的处理逻辑流程如下,希望能够只在第一帧/初始帧进行检测识别,并试图将第 N+1 帧中的目标,与第 N 帧的目标关联起来,这样对于后续帧,不再需要进行识别,只需要进行检测就可以得到目标的 ID 了;
- 第 N 帧:目标检测,目标识别
- 第 N+1 帧:目标检测,目标追踪
- 第 N+2 帧:目标检测,目标追踪
- 第 N+2 帧:目标检测,目标追踪
- ...

步骤一:对于某帧取特征框并计算质心
对于视频流,通过检测算法对于每帧图像进行检测;
比如上图中有两个特征框 / 或者我们假定两个特征框给它,分别为 ID #1 和 ID #2,可以计算出两个特征框的质心,分别得到位置坐标 (x,y);
以实际视频流为例:

步骤二:计算新旧目标特征框质心的欧氏距离
对于视频流中的后续帧,我们利用检测算法来计算特征框,但是我们不会再去给对于每一个检测到的物体添加新的 ID 或者标记什么的(只做检测,不做识别),而是希望将新的目标能够和旧目标联系起来;
我们通过计算每对新旧目标的欧式距离来得到这些目标之间的关系;
如下图所示,比如帧 N 时候有两个目标(绿色),帧 N+1 时候有三个目标(红色),所以对于我们希望知道,这两个旧目标(绿色),在后续帧中变成了哪一个新目标(红色);
所以我们想知道如下质心之间的关系:
- 绿1->红1,绿1->红2,绿1->红3;
- 绿2->红1,绿2->红2,绿2->红3;

步骤三:更新已知目标的质心坐标
质心追踪算法的前提是:对于一个给定目标,将会在后续帧中都出现,而且在第 N 帧和 N+1 帧中的质心欧氏距离,要小于不同目标之间的欧式距离;
因此我们在视频流的连续帧之间,根据欧氏距离最小原则,将这些帧中特征框的质心联系起来,可以得到一个目标 X 在这些连续帧中的变化联系,就达到了我们目标追踪的目的;
步骤四:注册新目标
有时候会有新目标的加入,比如帧 N 的时候有 x 个目标,而帧 N+1 的时候有 x+1 个目标,增加了一个目标;
所以对于这个新增的目标,我们按照以下顺序进行注册:
- 给这个新目标一个目标 ID;
- 储存这个目标特征框的质心位置;
然后从步骤二开始,对于视频流中的每一帧进行计算欧氏距离,更新坐标等步骤;
步骤五:注销旧目标
一个目标在后续帧中可能会消失,我们的目标追踪算法也要能够处理这种情况;
但是对于消失目标的处理方法,要根据于你实际部署应用的场景;
- 第 N 帧丢失目标,注销旧目标
- 第 N 帧丢失目标,而且第 N 帧中的后续 n 帧中都没有找回来,那就注销旧目标
因为每次重新注册的成本(进行检测/识别)的成本要大于欧氏距离比对进行目标追踪的成本;
这篇介绍 OT 的理论部分,接下来会介绍如何用 Python + OpenCV 去实现 OT;
# 请尊重他人劳动成果,转载或者使用源码请注明出处:http://www.cnblogs.com/AdaminXie
# 欢迎关注我的 Github:https://github.com/coneypo/
# 如有问题请留言或者联系邮箱: coneypo@foxmail.com