一、二进制,位,字节、字符
我们都知道,在计算机内部,数据都是以二进制的形式存储,所有的信息最终都表示为一个由0和1组成的字符串,每一个二进制位都是只有0或者1两种状态,每一个0或者0称为位(bit),然后规定每八个二进制位为一个单位,为一个字节(byte),现在可以明白了,位和字节都是内存的空间单位,或者说是计算机中数据量的计量单位,如 int 为32位,也可以说是4字节。

字符就是在计算机显示器给我们显示的一个个文字或者符号,比如:A。B、C,你,好,&,+等都是一个字符
二、编码
刚才说的字符都是显示给人看的,计算机是不能直接存储字符的,那问题来的,计算机是怎么存储字符的呢?
刚才已经说过,计算机是以二进制的形式存储数据的,数据都是字符,存储方式是二进制,那他们是怎么对应上的呢?

这种将字符对应成二进制的形式就是------编码
例如:我们输入A,计算机将1000001存进内存,而显示时遇到1000001,就是在屏幕上显示A,
其实编码就是一个翻译的过程,将人类的字符语言与计算机的二进制语言进行翻译。

几种编码方式
ASCII编码:
美国人发明的,一个字节是8位,每一位上有0或者1两种情况,那一个字节就有256种不同的状态,如果将256种不同的编码对应一种字符,那就是256字符。老美需要表示的字符有128种,所以美国人发明了ASCII就是用256种种的128种规定了他们需要的字符:一下是常用的几种

![]()
![]()


ASCII的缺陷就在于表示的字符太少,世界上有那么多的字符,他只表示了128种,显然是不够用的。
iso8859-1 :
1字节八位的所有组合有256种,刚才ASCII只使用其中的128种,而iso-8859-1是使用单字节编码,范围就是0——255;显然ISO-8859-1表示的范围也是非常的有限。但是ISO-8859-1使用的是单字节编码,而计算机存储也是以字节为单位,所以两者对应关系是一致的,所以使用ISO-8859-1在计算机中是非常方便的,所以现在很多协议默认使用的就是ISO-8859-1编码方式。虽然ISO-8859-1不能直接表示中文,但是他可以利用其它编码方式表示中文,也就是将其他编码的中文拆分成一个一个字节来表示,这一个个字节组合起来就是要表示的中文。
GB2312:
国标码,专门用来表示汉字,是双字节编码,
规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的 字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
GBK :
GB2312 是对 ASCII 的中文扩展。 但是中国的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来,然后又对GB2312进行扩展,
原先规定两个字节都是大于127的才表示一个中文,现在只要求第一个字节大于127,第二个字节可以小于127,这样又多出来很多编码,扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
unicode :
很多地区都开始制定自己国家、自己语言的编码方式,导致计算机的编码方式不能够统一,ISO (国际标谁化组织)的国际组织决定着手解决这个问题,重新搞一个包括了地球上所有文化、所有字母和符号 的编码!他们打算叫它"Universal Multiple-Octet Coded Character Set",简称 UCS, 俗称 "UNICODE"。 ISO 就直接规定必须用两个字节,也就是16位来统一表示所有的字符。UNICODE 对于ASCII编码不变,只是将其长度由原来的8位扩展为16位,比如字母a为"00 61"。 至此,计算机中不论英文还是中文都是两个字节表示和存储;显然英文字符在计算机中造成了内存的浪费。
UTF
考虑到unicode编码不兼容iso8859-1编码,而且容易占用更多的空间:因为对于英文字母,unicode也需要两个字节来表示。所以unicode不便于传输和存
储。因此而产生了utf编码,utf编码兼容iso8859-1编码,同时也可以用来表示所有语言的字符,不过,utf编码是不定长编码,每一个字符的长度从1-6个字
节不等。
UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全 部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
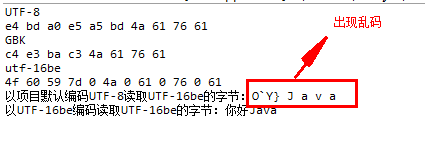
package com.neuedu.demo01; import java.io.UnsupportedEncodingException; public class EncodeDemo01 { public static void main(String[] args) throws UnsupportedEncodingException { String string="你好Java"; byte [] byte1=string.getBytes();//转换成字节序列用的是项目的默认编码UTF-8 //UTF -8 中文占3个字节,英文占一个字节 System.out.println("UTF-8"); for (byte b : byte1) { //把字节转换成int 以16进制的方式显示 System.out.print(Integer.toHexString(b& 0xff) + " "); } System.out.println(); //GBK 中文占两个字节,英文占一个字节 byte [] byte2=string.getBytes("GBK"); System.out.println("GBK"); for (byte b : byte2) { //把字节转换成int 以16进制的方式显示 System.out.print(Integer.toHexString(b& 0xff) + " "); } System.out.println(); //java 是双字节编码 utf-16be byte [] bytes3=string.getBytes("utf-16be"); //utf-16be 中文英文都是占用两个字节 System.out.println("utf-16be"); for (byte b : bytes3) { //把字节转换成int 以16进制的方式显示 System.out.print(Integer.toHexString(b& 0xff) + " "); } System.out.println(); /* * 当你的字节序列是某种编码时,当想把字节序列变成字符串时,也需要以这种编码方式转换 * 通常所说的乱码就是在转换的时候读和写的编码方式不一样 */ String str1=new String(bytes3); System.out.println("以项目默认编码UTF-8读取UTF-16be的字节:"+str1); String str2=new String(bytes3,"utf-16be"); System.out.println("以UTF-16be编码读取UTF-16be的字节:"+str2); } }
结果:
参考资料:http://blog.csdn.net/chenjing502/article/details/38364911