HouseBrain-Lite(Python3.6版本,希望大家抓紧时间做)
软件工程基础作业的项目文档&组内学习笔记 from lgx
This is a smart room monitoring system developed based on the Flask framework and OpenCV technology, using the Raspberry Pi as a server to deploy the project.
| 安装指令(或在PyCharm中直接安装插件) | 用途 | 版本号 |
|---|---|---|
| flask-blueprint | 蓝图,用于将后端逻辑部分分开 | 1.3.0 |
| Flask-Migrate | 迁移仓库,用于更新Model时更方便 | 2.5.3 |
| Flask-Script | Flask脚本 | 2.0.6 |
| Flask-SQLAlchemy | 一种用于Flask的ORM框架 | 2.4.1 |
| PyMySQL | python的MySQL插件 | 0.9.3 |
| Jinja2 | 模板引擎 | 2.11.1 |
| Flask-Bootstrap | 用于引入Bootstrap | 3.3.7.1 |
注意:Flask-Migrate和PyMySQL这两个版本不是用的最新版本,安装时请指定标粗的版本!
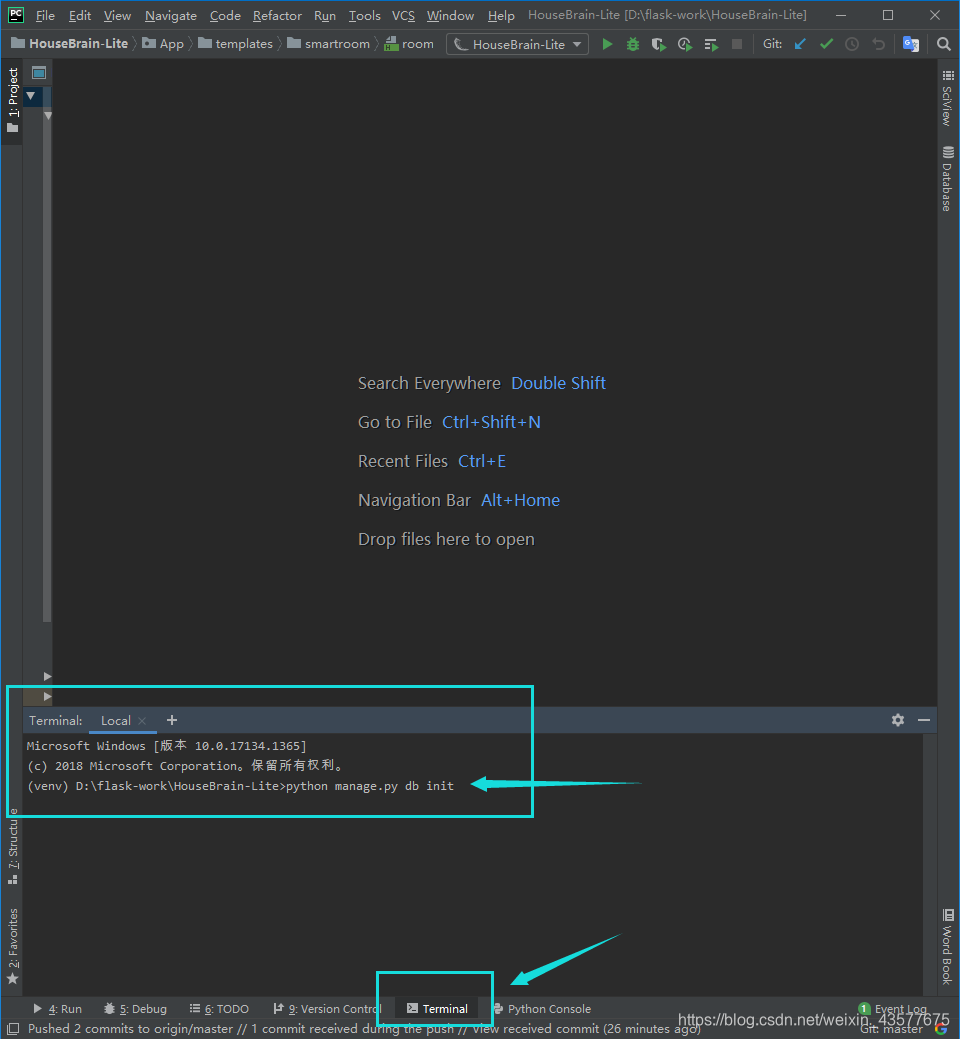
生成迁移仓库(migration)的三句命令行:
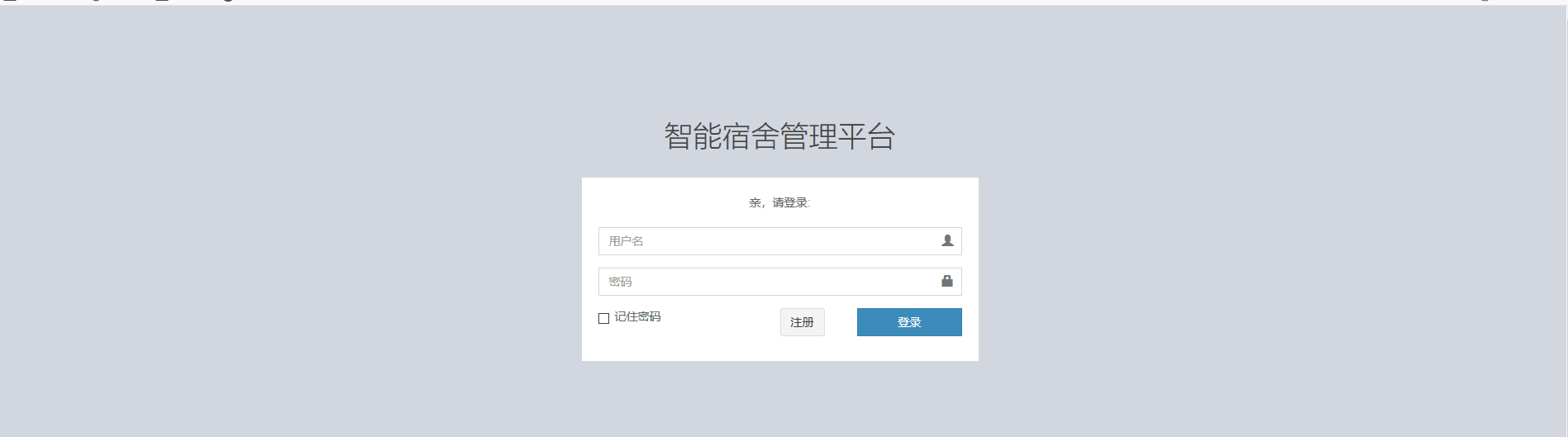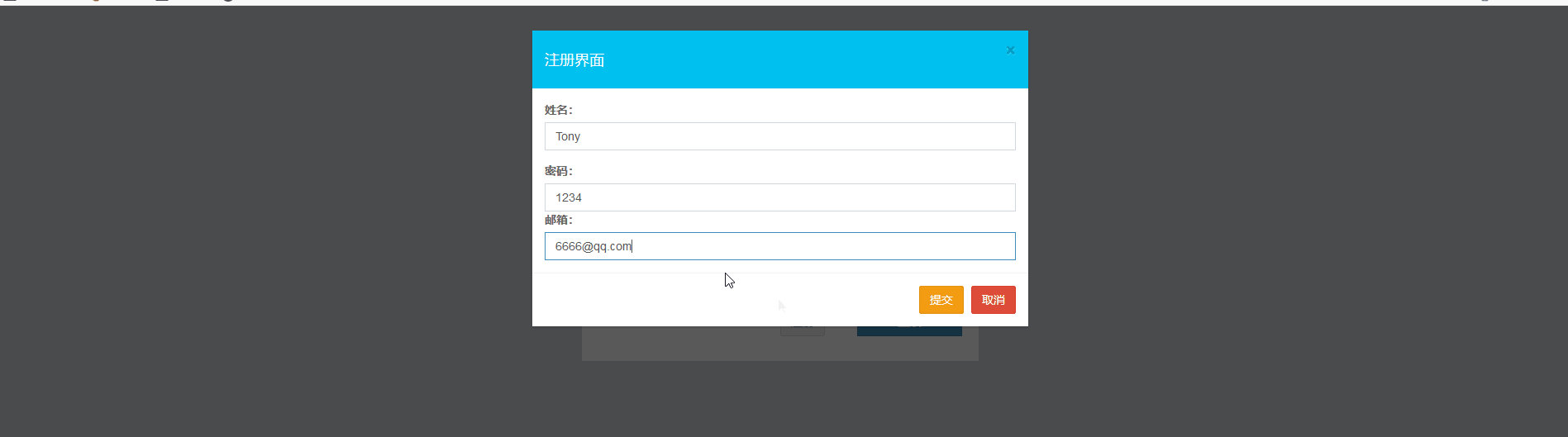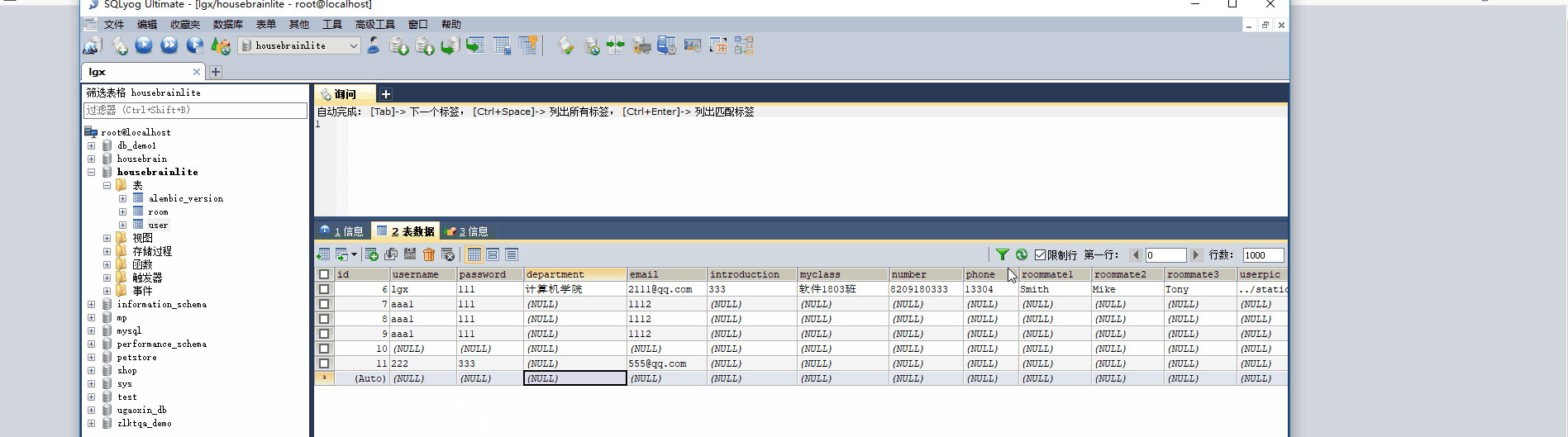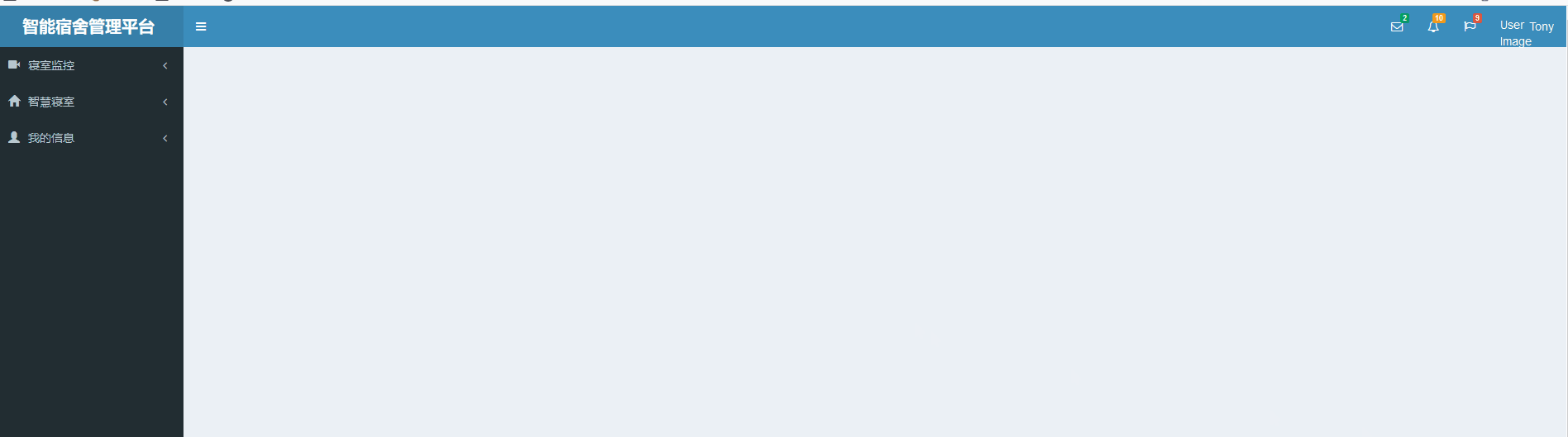
python manage.py db init python manage.py db migrate python manage.py db upgrade首先新建名为 ‘ housebrainlite ’ 的数据库,之后执行这三条语句,就可以生成数据库表结构啦(如下图)
(PyCharm中的‘Terminal’中是写命令行的)
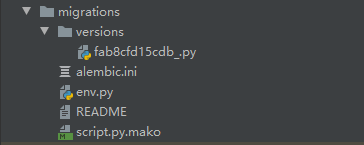
这里是执行三条命令行语句后生成的文件,以及数据库中的表结构

下面的是迁移仓库使用时的常见错误
如果数据库迁移Target database is not up to date报错,删掉migration之后重新执行上述三句命令行即可,
当然如果还是不好使,建议重启电脑,然后再开项目,毕竟也不是不可能(lgx碰过一次,卡了二十分钟)
(如果使用sqlite数据库还要删除.sqlite文件)
migration的生成有时候可能会比较慢,如果执行上述三句命令行没有生成migration文件,建议重新启动项目,或者等待片刻
如果有“ImportError: No module named 'MySQLdb'”报错,是因为python2和python3在数据库模块支持这里存在区别,python2是mysqldb,而到了python3就变成mysqlclient,pip install mysqlclient即可。因为现有学习资料(尤其是网课)很多的flask教程都是基于python2的,所以难免会有一些差异
最后收藏的一些比较好的和本项目有关的博客,不过有不少问题实际上也是书上找到的,这里推荐大家都有的一本书《Flask Web开发》(第二版),如果想看本书源码请进入该链接 https://github.com/miguelgrinberg/flasky
Python Flask-表单提交方式 https://blog.csdn.net/Co_zy/article/details/76658862
数据库迁移Target database is not up to date报错 https://blog.csdn.net/huang5487378/article/details/66973805
pip 常用命令 https://blog.csdn.net/sunlanchang/article/details/52563882
Pycharm项目上传到Github https://blog.csdn.net/m0_37306360/article/details/79322947
SQLAlchemy简明教程 https://jiajunhuang.com/articles/2019_10_30-sqlalchemy.md.html
Flask 环境变量 FLASK_APP 说明 https://foofish.net/flask_app.html
下面是关于本项目架构的说明

项目的根目录下的几个文件我做一下单独的说明:
migrations:生成的migration迁移仓库,主要用途是如果没有迁移仓库,修改数据库表就会变得相当的麻烦(先删除原有的表再重新生成),而且表中原有的数据也会因为颠覆掉原有的表而丢失。使用迁移仓库,在更新表结构之后,只需要先后执行 python manage.py db migrate 和 python manage.py db upgrade 即可,每次更新后数据库中的那串字符(version_num)就会有想应的变更(下图是对应的数据库表)

venv:是在新建项目时PyCharm会自动为该Flask项目生成一个虚拟环境,当然好处是方便,不需要你自己建立并引入自己的虚拟环境,同时不同项目直接用不同的插件也是非常简洁明了;缺点也非常明显,就是每次新建一个项目的时候都要自己手动引入一堆的pip…,还挺麻烦
manage.py:Flask应用项目的主脚本,也就是最开始新建Flask项目时生成的的那个hello.py,是项目的启动文件
README.md:不同于.html和.py文件,文件后缀名为.md的文件全称是Markdown类型的文件。该文件通常用于项目文档的书写,在GitHub中也有专门展示项目文档的地方。不过书写Markdown类型的项目文档我们需要Markdown的语法,Markdown的这些语法提供很多强大且好用的功能,如:代码块、引用、段落分层等。不过Markdown虽然如此强大,可是我不想写那些语法啊,记不住不说还麻烦,有没有一款我能够写Markdown如同写Word文档一样的感觉呢?有的,Typora是你不二选择!在Typora下载客户端后,写项目文档就能够行云流水一般顺滑,保证你写项目文档写到上瘾(因为不想写代码嘛)
既然写项目文档会上瘾,就希望各位在小组的文档中可以记录一些自己碰到的典型/非典型bug,以及一些自己的收获,或者是自己收藏的博客文章,都可以采取Markdown文档的形式在组内分享,毕竟互相取经防患于未然真的可以节省好多好多时间。
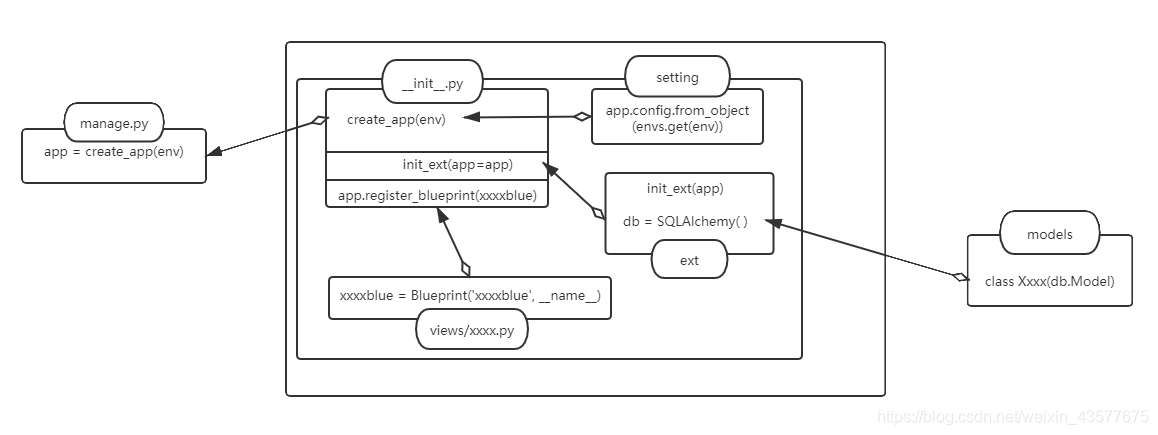
下面是项目主要文件之间的关系(图示如下)
再说一下Flask项目中对数据库的操作,以user.py为例
(以下项目文档涉及到大量代码)
# 首先这些常规的该有都要有
from flask import Flask, Blueprint, render_template, session, redirect, url_for, request, Response
# 对应功能分别是:Flask、蓝图(也就是蓝本)、渲染模板、session、页面重定向、跳转、request、Response
# 然后是蓝本的注册与引用,这里涉及到多个文件,这里就统一放到一起说了
# 1.在保证model有User类的前提下,首先在user.py中引入model中的User
from App.models import db, User
# 2.引入之后再user.py中声明一个蓝图对象user
userblue = Blueprint('userblue', __name__)
# 3.视线转向__init__.py这个文件,首先引入蓝图,有多少蓝图就引入多少,我们以刚才声明的userblue蓝图为例
from App.views.user import userblue
# 4.最后呢,我们在__init__.py中的create_app方法中注册userblue蓝图
app.register_blueprint(userblue)
# 总结的上述四条就是每新注册一个蓝图的步骤,通常每一个蓝图对应数据库中的一个表
上面简单介绍了蓝图的注册与配置,接下来说一下有关session的内容,我们看一下项目中的login(登录)方法
# 首先写一个方法的第一步就是配置路由(route),路由中有地址,login的地址就是'/',意思就是初始路由,运行项目后最先展现的页面就是登录页面也是这个原因。后面的methods=['GET','POST']是因为该方法用到了GET和POST
# 看一下下面的这段代码,这段代码是执行GET,作用是提供页面跳转的功能,也就是说我打开login.html的页面执行的就是这个GET部分的内容,即打开login这个页面
if request.method == 'GET':
return render_template('login.html')
#因为上面的if判断语句已经声明是一个GET,所以下面的else就代表着POST部分
else:
username = request.form.get('username')
password = request.form.get('password')
result = User.query.filter(User.username == username,
User.password == password).first()
# 重点来了,request.form.get是一种从表单获取数据的写法
# 之后的User.query.filter()是一个查询方法,括号中的放入的是查询条件,first就是查第一个的意思
# 注意,不同于Java,Python由于其语言的特性,编译器中的很多地方都没有智能提示,比如.query.filter就没有智能提示,只能是靠手一个字母一个字母敲出来,虽然有一种让你感觉你写的是错误代码的感觉,不过这类SQLAlchemy的语句有很多都没有智能提示,所以这些代码一定要熟记于心,尤其是敲错了这部分的代码还是很影响心情和效率的
# 现在说一下session部分,看下面的代码
# 登录成功或者失败的判断
if result:
# 定义一个字典
userItem = {}
# 开始存数据
userItem['username'] = result.username
userItem['userpic'] = result.userpic
userItem['roomid'] = result.roomid
# session是http协议的状态跟踪技术,http协议是tcp短连接
session['user'] = userItem
return render_template('index.html')
# 这部分的代码我同样也写了注释,因为真的很重要,这里是将username、userpic和roomid存入到session中
# 刚才定义的session在之后的很多方法中也有用到,可以说几乎都有用到,只要是和增删改查相关的内容,如:
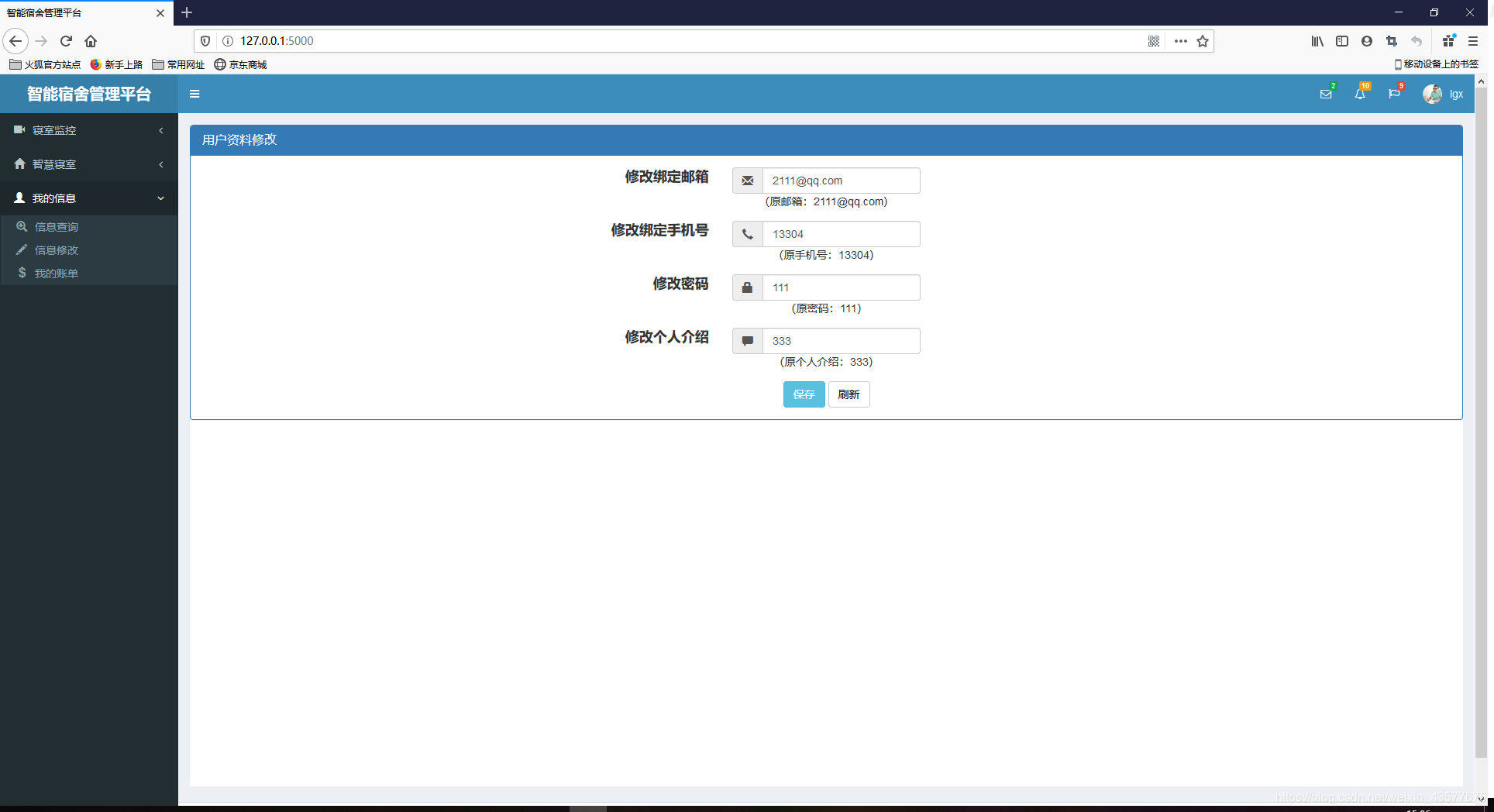
# 用户修改自己的个人信息
@userblue.route('/myinfo/myupdate', methods=['POST', 'GET'])
def myupdate():
item = session.get('user')
user = User.query.filter(User.username == item.get("username")).first()
if request.method == 'GET':
return render_template('myinfo/myupdate.html',user = user)
else:
user.email = request.form.get('myupdate_email')
user.phone = request.form.get('myupdate_phone')
user.password = request.form.get('myupdate_password')
user.introduction = request.form.get('myupdate_introduction')
db.session.add(user)
db.session.commit()
return render_template('myinfo/myupdate.html',user = user,message='修改成功')
# 修改就可以理解为先将之前的数据查询,然后再进行增加的操作
最后说一下BootStrap,也就是前端页面
前端页面可以仿照着我之前做过的页面进行布局
login界面
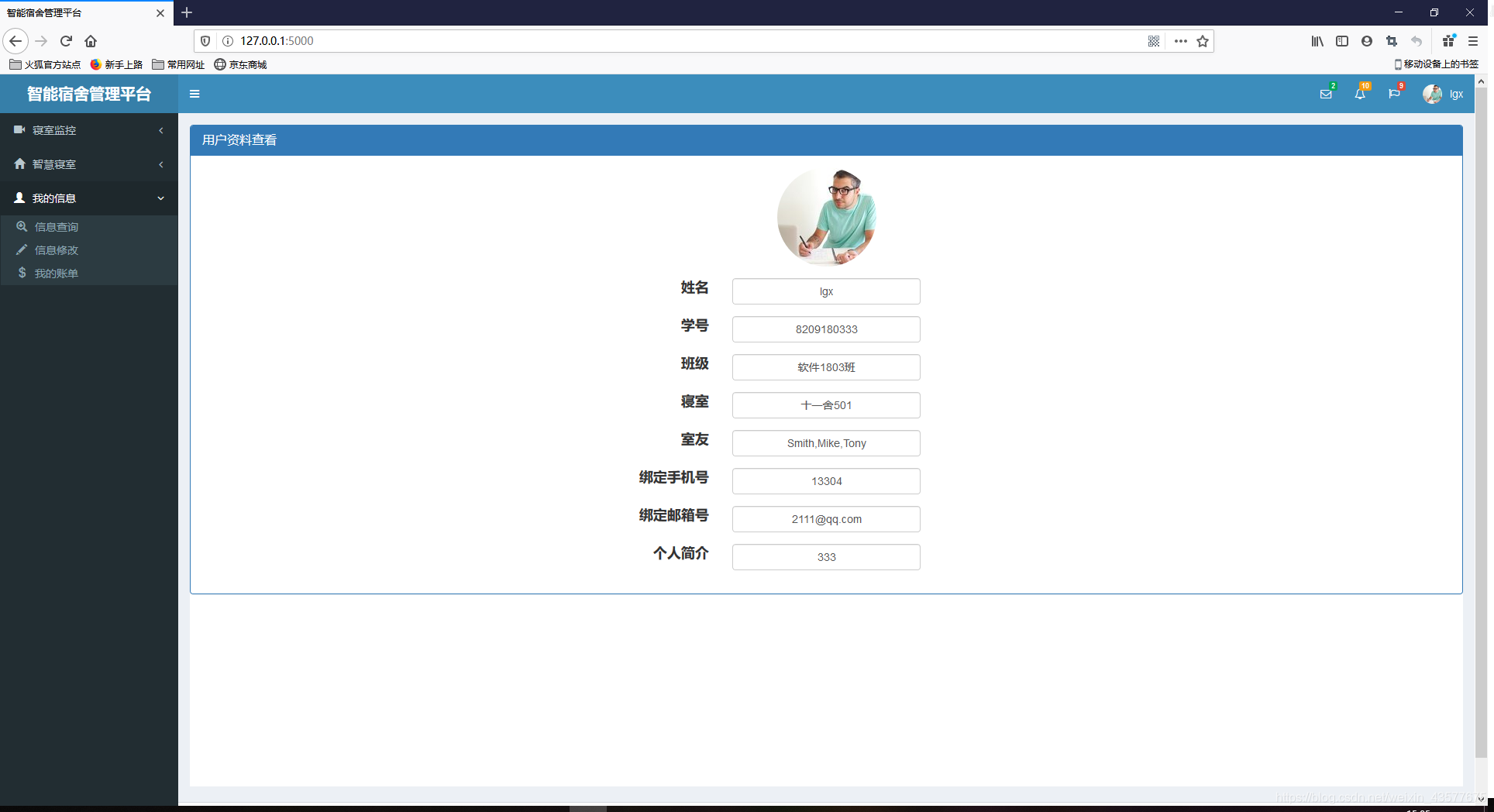
个人空间界面

水电缴费界面
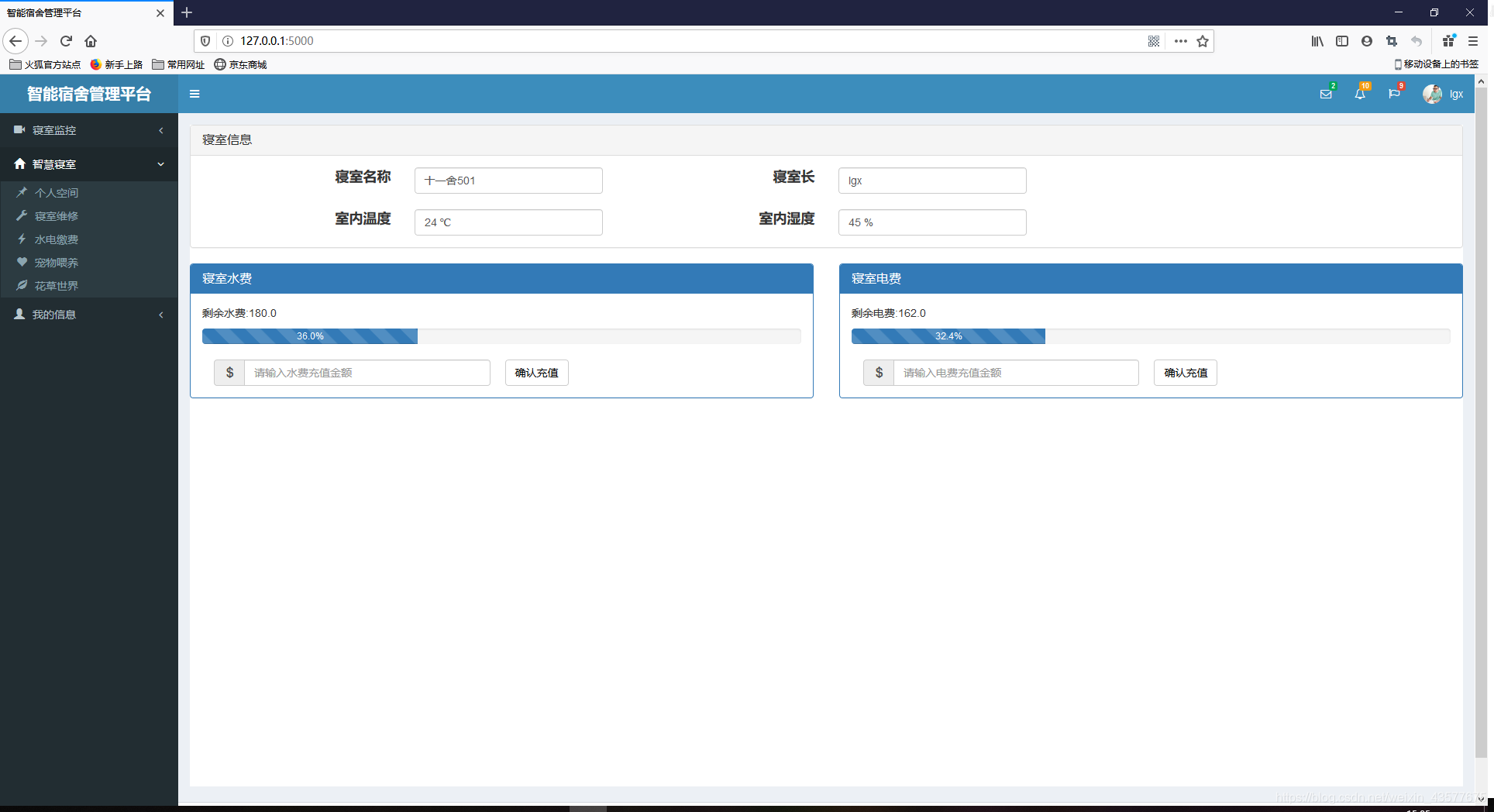
信息查询界面
信息修改界面
登录操作如下:
进入主页后目前已经做的部分:
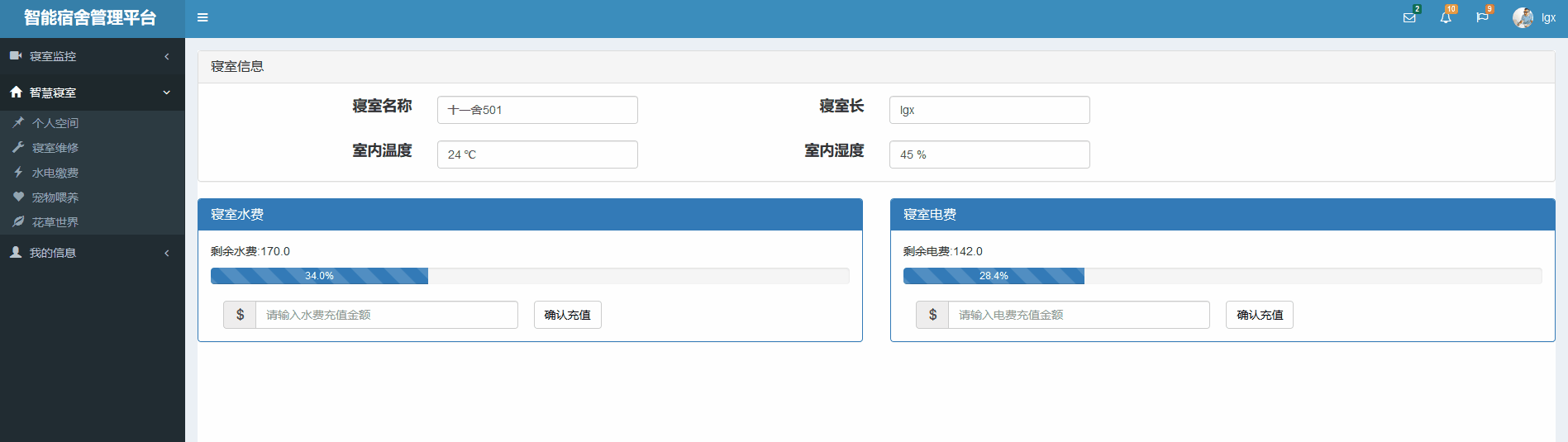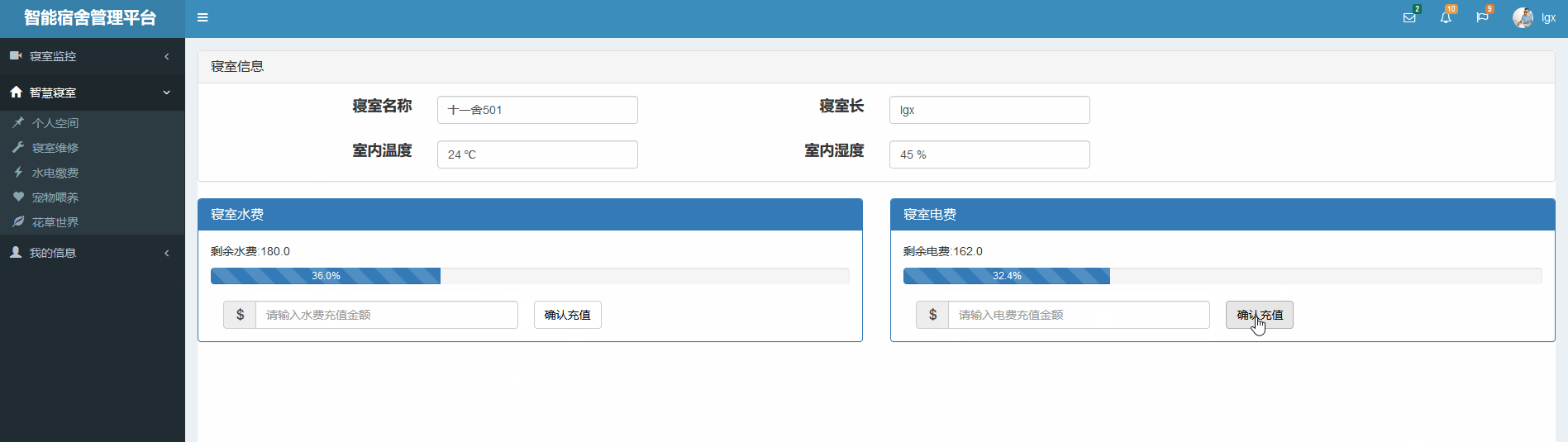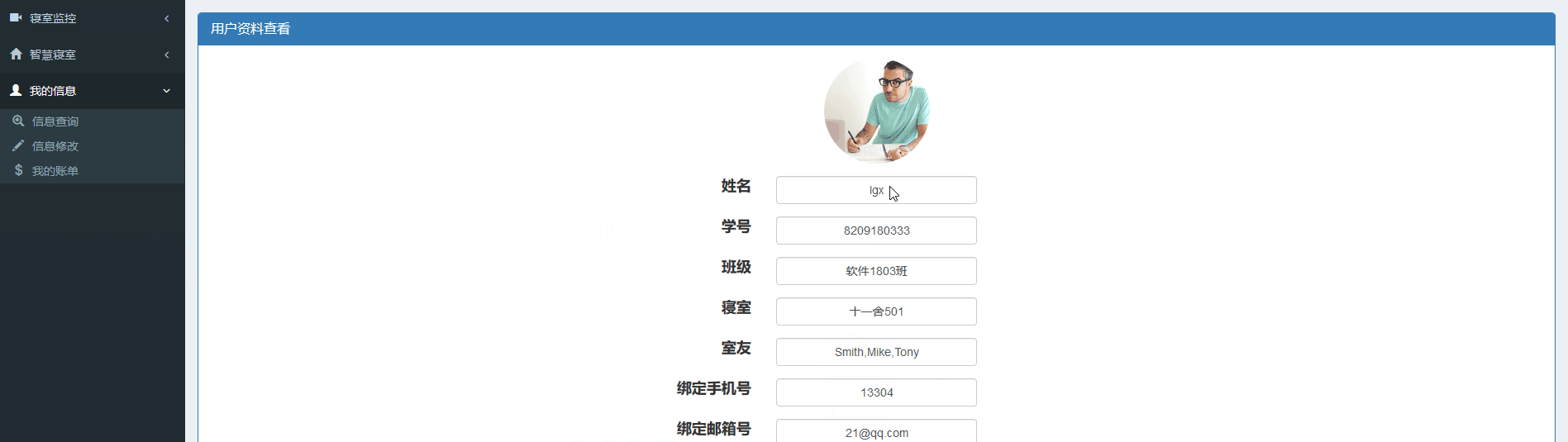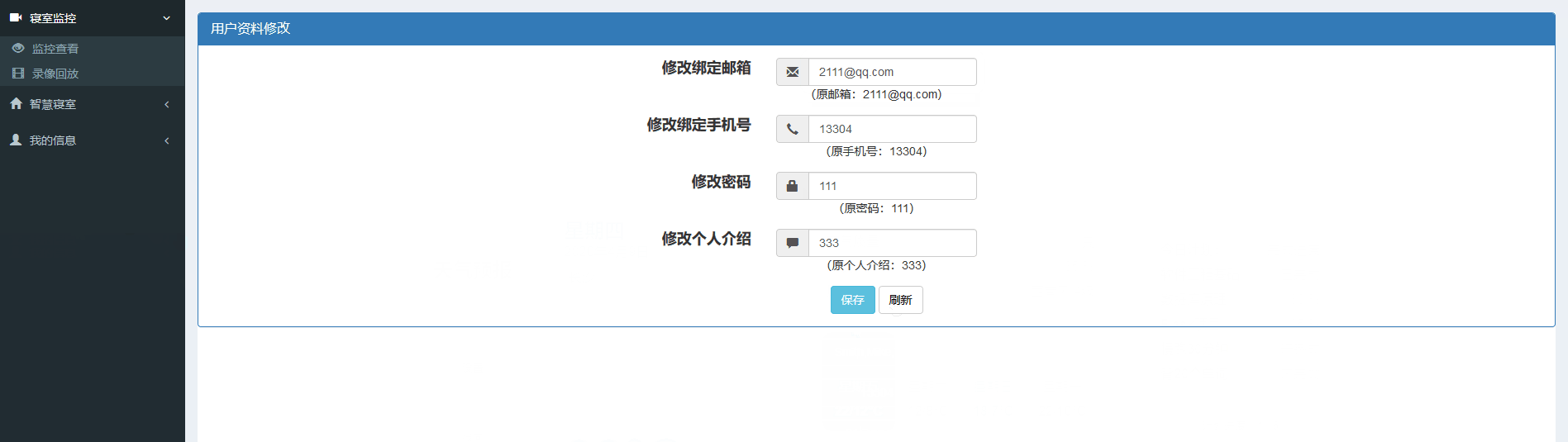
大家如果有更好的想法也可以按照自己的来写,这里的代码部分仅作为参考
祝大家项目顺利~~ ( 逃
宿舍视频流实现 form lwl
主要技术:
- opencv
- 深度学习
- 请求处理
主要实现功能
视频监控
发现行人可以及时检测出,并且圈出这些人
关于与后端的接口交互问题,建议开启跨域访问,留下相关接口。我可以直接在监控模块中留下可以发出请求的函数
人脸识别开门
使用opencv进行图片收集,DL进行人脸识别
准确率较高。
问题:需要进行硬件模拟
关于宿舍卫生状况提醒
使用深度学习制作的图片分类问题,能够较精确的判断宿舍是干净还是比较脏。
目前设想是每天固定时间段对宿舍进行卫生,如果检测判定为脏,那么就发送邮件等提醒给用户,并且附上图片
- 使用kaggle上的数据
- cnn卷积神经网络,正则化,图像增强防止过拟合
- 迁移学习(考虑到性能,还是不用为好)
目前在较低的内存开销下,能够实现80%的正确率。
<修改>