学习计算机组成原理有什么用?
从StackOverFlow上一个很经典的问题说起
运行下面的程序,然后比较加上Arrays.sort(data)这行之后,程序速度的变化
import java.util.Arrays;
import java.util.Random;
public class Test
{
public static void main(String[] args)
{
// Generate data
int arraySize = 32768;
int data[] = new int[arraySize];
Random rnd = new Random(0);
for (int c = 0; c < arraySize; ++c)
data[c] = rnd.nextInt() % 256;
// !!! With this, the next loop runs faster
//Arrays.sort(data);
// Test
long start = System.nanoTime();
long sum = 0;
for (int i = 0; i < 100000; ++i)
{
// Primary loop
for (int c = 0; c < arraySize; ++c)
{
if(data[c]>128)
sum+=data[c];
}
}
System.out.println((System.nanoTime() - start) / 1000000000.0);
System.out.println("sum = " + sum);
}
}
在我的电脑上,对数组排序后程序运行速度是原来的四倍,这就奇了怪了,怎么排个序就快了这么多?你可能模模糊糊知道应该往计组的方面想,要从底层找原因,毕竟这篇博文就是试图向你说明了解计组有什么用。
现在将排序注释掉,并把primary loop里面的代码换成
int t = (data[c] - 128) >> 31;
sum += ~t & data[c];
再次运行程序,你会发现程序运行的时间跟排序后的运行时间差不多,甚至还快一点。有意思吧,通过前面的两次改动,我们已经把问题锁定在了Primary loop这里,现在看来是if语句搞的鬼。没想到这个平日里看起来浓眉大眼,人畜无害的东西也会给我玩花样,想不到想不到。
为了快点写完作业,我选择瞎蒙
现代计算机的设计,在提高运行速度这块想出了很多办法,cache绝对算的上是最精彩的那一个。不过跟本问题相关的是流水线的设计,我们还是先来认识这熟悉又陌生的词语吧。
流水线是一种实现多条指令重叠执行的技术,你可以类比于生产流水线。
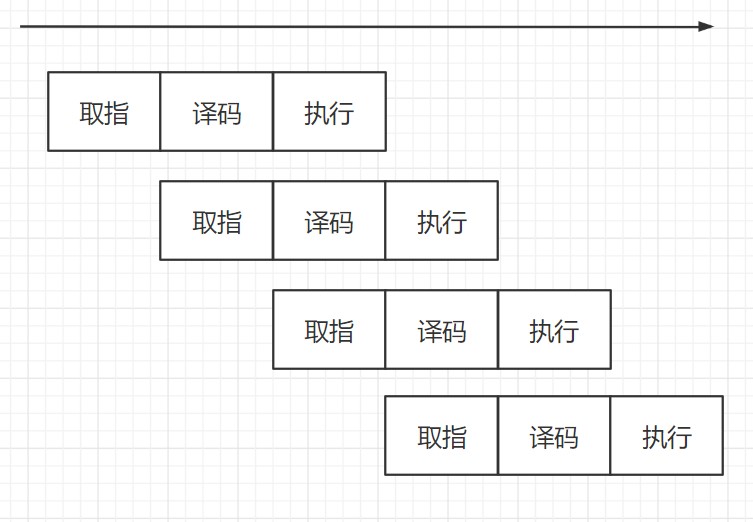
类似于这样,大家印象中的流水线都是高速运转的,没有人希望它停顿。如果流水线存在分支的话,按照常理来讲,我们只能是停下来等结果。等比较的结果出来了,再决定走哪条分支 。流水线说,我是一个永不止步的男人,怎么能因为这点事就停顿呢?忍不了,咋整呢?
有一种办法是分支冒险(branch hazard),虽然名字听起来很高大上,其实就是赌一把,蒙一个。我假设这个分支发生,赌对了自然什么都不用做,赌错了就得丢弃假设不发生之后执行的指令。这有点像赶作业的时候,碰到判断题如果你不想做的话,就一路打×,因为这种题目大概率打叉的情况多。当然,计算机没有你那么聪明不知道这条规律,但它可以使用动态分支预测的方法来提高预测的准确性。
这里介绍两位预测位机制,猜错两次就变换猜测方向。
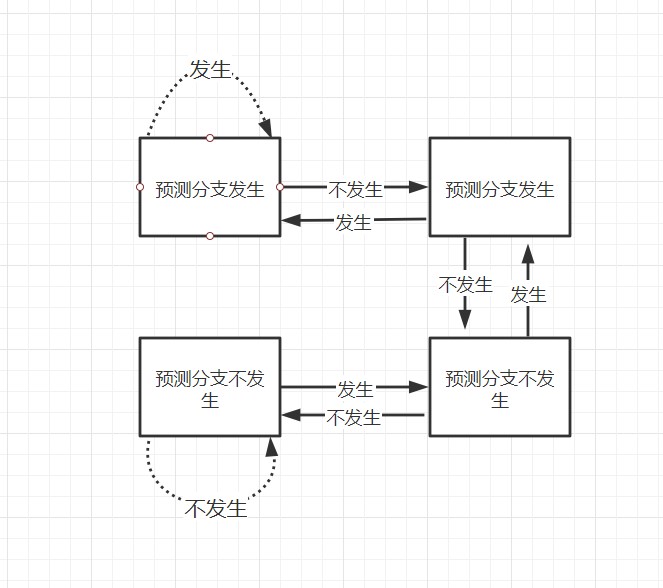
让我们再来回忆一下之前的实例程序的流程,在0-256的范围随机生成了一个数组,并且将大于128的值加到sum变量中。现在,让我们用刚刚学到的知识分析那条万恶的if语句
if(data[c]>128)
sum+=data[c];
累计两次预测失败我们就会变换预测方向,如果不对数组进行排序的话,数组中的数字是随机分布的,我们预测的准确性将会非常低。这意味着我们将会耗费大量的时间在:将流水线中投机执行的中间结果全部抛弃,重新获取正确分支路线上的指令执行。如果是已经排好序的数组,最坏的情况下我们也只有四次预测失败,这为我们节省了大把的时间。这也是为什么我们换成位运算,程序会更快的原因。因为不会存在预测失败重新执行的情况。
好像和我程序里写的不一样
public class Thread01 implements Runnable {
private int cnt=10;
@Override
public void run() {
while (cnt>0){
System.out.println(Thread.currentThread().getName()+" cnt= "+cnt--);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
Thread01 thread01=new Thread01();
Thread a=new Thread(thread01,"a");
Thread b=new Thread(thread01,"b");
Thread c=new Thread(thread01,"c");
Thread d=new Thread(thread01,"d");
Thread e=new Thread(thread01,"e");
a.start();
b.start();
c.start();
d.start();
e.start();
}
}
运行这段程序,你会发现有两个线程输出了同样的数字,按道理这是绝对不可能发生的事情。还是计算机惹的锅,因为CPU访问缓存区比访问内存要快得多,所以为了高效,现代计算机往往会在高速缓存区中缓存共享变量.
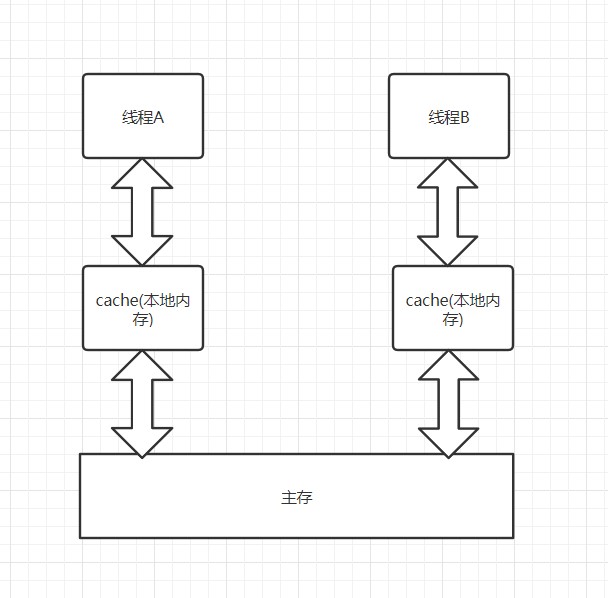
也就是说,大家各搞各的,这与cache的写回操作有关(保险的办法当然是写直达,但咱不是为了快嘛,所以就出问题了)。有可能你修改的时候,来不及通知我这个值已经不能用了,要重新获取,最后的结果就是输出了两个一模一样的值。
关于Cache写操作是如何影响程序性能的,可以参考 Cache写策略(Cache一致性问题与骚操作)
多线程的东西很多:重排序,内存屏障,CAS....感兴趣的同学可以查阅相关资料,这篇博文只是抛砖引玉而已。