选一个自己感兴趣的主题或网站。
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
主题
虎扑新闻热榜
全部代码与过程
文本分析
import requests
from bs4 import BeautifulSoup
url = "https://voice.hupu.com/hot"
header={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
res = requests.get(url, headers=header)
html = res.content.decode('utf-8')
soup = BeautifulSoup(html, "html.parser")
text = soup.select('.card-fullText-hd a')
for i in text:
f = open('info.txt', 'a+', encoding='utf-8')
f.write(i.get_text())
f.close()
生成词云
# -*- coding:utf-8 -*-
from PIL import Image,ImageSequence
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
import jieba.analyse
lyric= ''
f=open('info.txt','r', encoding='utf-8').read()
result = ''
result += ' '.join(jieba.lcut(f))
image= Image.open('1.png')
graph = np.array(image)
wc = WordCloud(font_path='C:WindowsFontsSTZHONGS.TTF',background_color='White',max_words=50,mask=graph)
print(result)
wc.generate_from_text(result)
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.imshow(wc.recolor(color_func=image_color))
plt.axis("off")
plt.show()
wc.to_file('xiaoxingxing.jpg')
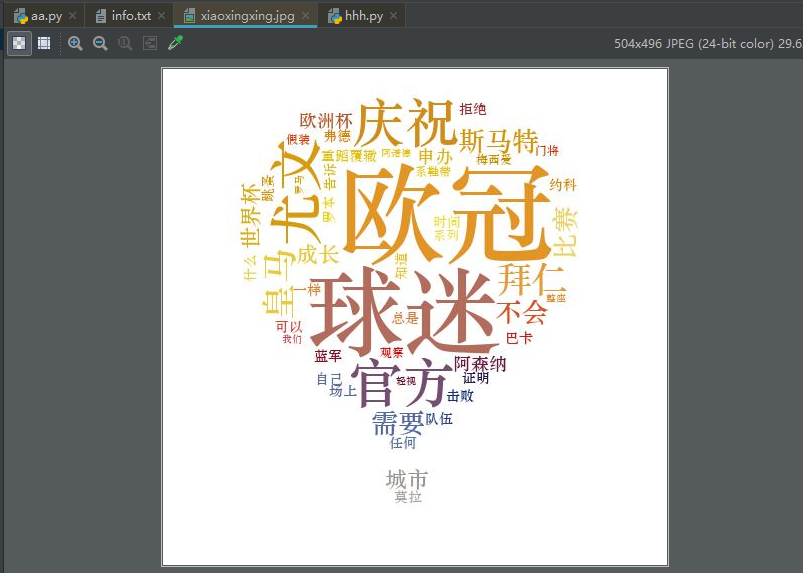
结果
遇到问题和解决办法
对库的应用不熟悉。Jieba库和WordCloud库。请教同学后得到解决。
全部数据